标签:了解 ict 其他 mon 文件 pass 永久 ace 实现
一般用于不同时间格式的转换
import time时间戳(timestamp):时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
time_stamp = time.time()
print(time_stamp, type(time_stamp))格式化的时间字符串(format string):格式化时间表示的是普通的字符串格式的时间。
format_time = time.strftime("%Y-%m-%d %X")结构化的时间(struct time):struct_time元组共有9个元素共九个元素,分别为(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
print('本地时区的struct_time:\n{}'.format(time.localtime()))
print('UTC时区的struct_time:\n{}'.format(time.gmtime()))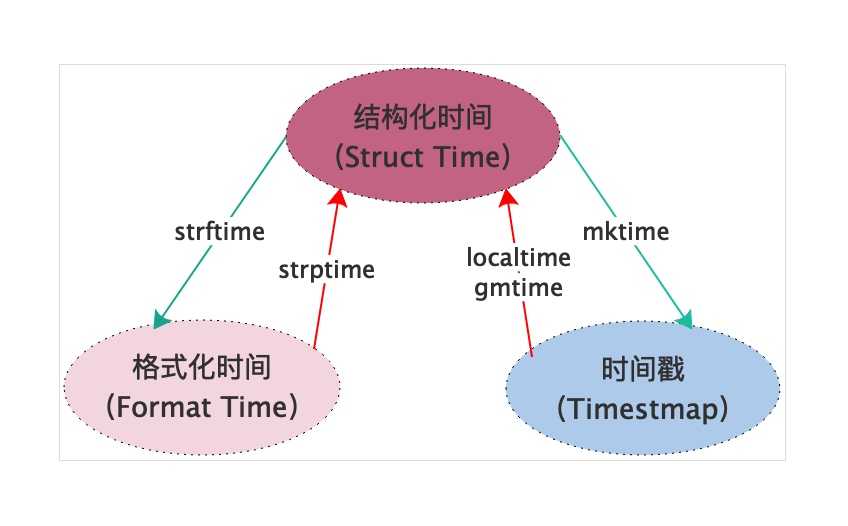
#结构化时间
now_time = time.localtime()
# 把结构化时间转换为时间戳格式
print(time.mktime(now_time))
# 把结构化时间转换为格式化时间
# %Y年-%m月-%d天 %X时分秒=%H时:%M分:%S秒
print(time.strftime("%Y-%m-%d %X", now_time))
# 把格式化时间化为结构化时间,它和strftime()是逆操作
print(time.strptime('2013-05-20 13:14:52', '%Y-%m-%d %X'))datetime模块一般用于时间的加减。
import datetime
now = datetime.datetime.now() # (*****)牢记
now + datetime.timedelta(3) # +3day
now - datetime.timedelta(3) # -3day
now + datetime.timedelta(-3) # -3day
now + datetime.timedelta(minutes=3) # +3minutes
now + datetime.timedelta(seconds=3) # +3seconds
now + datetime.timedelta(365) # +1year
now.replace(year=2012, month=12, day=22, hour=5, minute=13, second=14)random一般用于生成随机数
import random
# (0,1) (*****)
random.random()
# [1,3] 的整数 (*****)
random.randint()
# [1,3] 的小数
random.uniform()
# [1,3) 的整数
random.randrange()
# 取容器中的一个元素 (*****)
random.choice([1,2,3])
# 取容器中的多个元素
random.sample([1,2,3],2)
# 打乱容器 (*****)
lis = [1,3,4]
random.shuffle(lis)os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口,多用于文件处理
import os
# 新建一个文件夹
os.mkdir(path)
# 新建一个文件
f = open('','w',encoding='utf8')
f.close()
# 删除一个文件(*****)
os.remove(path)
# 重命名一个文件(*****)
os.rename(path)
# 删除空文件
os.removedirs(path)
# 删除一个空文件
os.rmdir(path)
# 拼接文件(*****)
os.path.join(path)
# 列出文件夹下所有内容(*****)
os.listdir(path)
# 获取文件大小(*****)
os.path.getsize(path)
# 获取文件夹下所有的文件夹和文件(*****)
os.walk(path)
# 当前当前项目路径
os.getcwd(path)
# 获取文件路径(*****)
os.path.dirname(os.path.dirname(__file__))
# 判断文件是否存在(*****)
os.path.exists(path)
# 执行linux命令
os.system('cd c:')
# 获取文件的绝对路径(*****)
os.path.abspath(__file__) # 获取当前文件的绝对路径
os.path.abspath(path) # 获取某一个文件的绝对路径sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行时环境。
import sys
# 获取当前文件的环境变量,就是模块的搜索路径(*****)
sys.path
sys.path.append # 添加环境变量
# 当终端 python test.py 参数1 参数2 ... 执行python文件的时候会接收参数(*****)
sys.argv
# 标准输出
sys.stdout.write()
# 标准输入
sys.stdin.read(n) # 读取的字符,如果输出过多的字符,只接受n个把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening。
序列化的优点:
反序列化:把json形式的数据从硬盘读入内存(*****)(*****)
缺点:不能保存函数之类的数据类型,保存的类型为字符串形式
Json序列化并不是python独有的,json序列化在java等语言中也会涉及到,因此使用json序列化能够达到跨平台传输数据的目的。
json数据类型和python数据类型对应关系表
| Json类型 | Python类型 |
|---|---|
| {} | dict |
| [] | list |
| "string" | str |
| 520.13 | int或float |
| true/false | True/False |
| null | None |

import json
# 内存中转换的
dic = {'name':'nick'}
# 了解
res = json.dumps(dic)
json.loads(res)
def write_json(filename, dic):
with open(filename,'w',encoding='utf8') as fw:
json.dump(dic, fw) (*****)
def read_json(filename):
with open(filename,'r',encoding='utd8') as fr:
data = json.load(fr) (*****)
return dataimport pickle
# 内存中转换的
def func():
pass
# 了解
res = pickle.dumps(func)
pickle.loads(res)
def write_pickle(filename, func):
with open(filename,'wb') as fw:
pickle.dump(func, fw) (*****)
def read_pickle(filename):
with open(filename,'rb') as fr:
data = pickle.load(fr) (*****)
return data标签:了解 ict 其他 mon 文件 pass 永久 ace 实现
原文地址:https://www.cnblogs.com/zhoajiahao/p/11002809.html