标签:应该 project 读取 指定 输出流 stat 字符 指针 流的概念
java的io是实现输入和输出的基础,可以方便的实现数据的输入和输出操作。在java中把不同的输入/输出源(键盘,文件,网络连接等)抽象表述为“流”(stream)。通过流的形式允许java程序使用相同的方式来访问不同的输入/输出源。stram是从起源(source)到接收的(sink)的有序数据。
注:java把所有的传统的流类型都放到在java io包下,用于实现输入和输出功能。
按照不同的分类方式,可以把流分为不同的类型。常用的分类有三种:
1.2.1 按照流的流向分,可以分为输入流和输出流。
此处的输入,输出涉及一个方向的问题,对于如图15.1所示的数据流向,数据从内存到硬盘,通常称为输出流——也就是说,这里的输入,输出都是从程序运行所在的内存的角度来划分的。
注:如果从硬盘的角度来考虑,图15.1所示的数据流应该是输入流才对;但划分输入/输出流时是从程序运行所在的内存的角度来考虑的,因此如图15.1所在的流时输出流。而不是输入流。
对于如图15.2所示的数据流向,数据从服务器通过网络流向客户端,在这种情况下,Server端的内存负责将数据输出到网络里,因此Server端的程序使用输出流;Client端的内存负责从网络中读取数据,因此Client端的程序应该使用输入流。
注:java的输入流主要是InputStream和Reader作为基类,而输出流则是主要由outputStream和Writer作为基类。它们都是一些抽象基类,无法直接创建实例。
1.2.2 按照操作单元划分,可以划分为字节流和字符流。
字节流和字符流的用法几乎完成全一样,区别在于字节流和字符流所操作的数据单元不同,字节流操作的单元是数据单元是8位的字节,字符流操作的是数据单元为16位的字符。
字节流主要是由InputStream和outPutStream作为基类,而字符流则主要有Reader和Writer作为基类。
1.2.3 按照流的角色划分为节点流和处理流。
可以从/向一个特定的IO设备(如磁盘,网络)读/写数据的流,称为节点流。节点流也被称为低级流。图15.3显示了节点流的示意图。
从图15.3中可以看出,当使用节点流进行输入和输出时,程序直接连接到实际的数据源,和实际的输入/输出节点连接。
处理流则用于对一个已存在的流进行连接和封装,通过封装后的流来实现数据的读/写功能。处理流也被称为高级流。图15.4显示了处理流的示意图。
从图15.4可以看出,当使用处理流进行输入/输出时,程序并不会直接连接到实际的数据源,没有和实际的输入和输出节点连接。使用处理流的一个明显的好处是,只要使用相同的处理流,程序就可以采用完全相同的输入/输出代码来访问不同的数据源,随着处理流所包装的节点流的变化,程序实际所访问的数据源也相应的发生变化。
1.3.1 流的原理浅析:
java Io流共涉及40多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java Io流的40多个类都是从如下4个抽象类基类中派生出来的。
对于InputStream和Reader而言,它们把输入设备抽象成为一个”水管“,这个水管的每个“水滴”依次排列,如图15.5所示:
从图15.5可以看出,字节流和字符流的处理方式其实很相似,只是它们处理的输入/输出单位不同而已。输入流使用隐式的记录指针来表示当前正准备从哪个“水滴”开始读取,每当程序从InputStream或者Reader里面取出一个或者多个“水滴”后,记录指针自定向后移动;除此之外,InputStream和Reader里面都提供了一些方法来控制记录指针的移动。
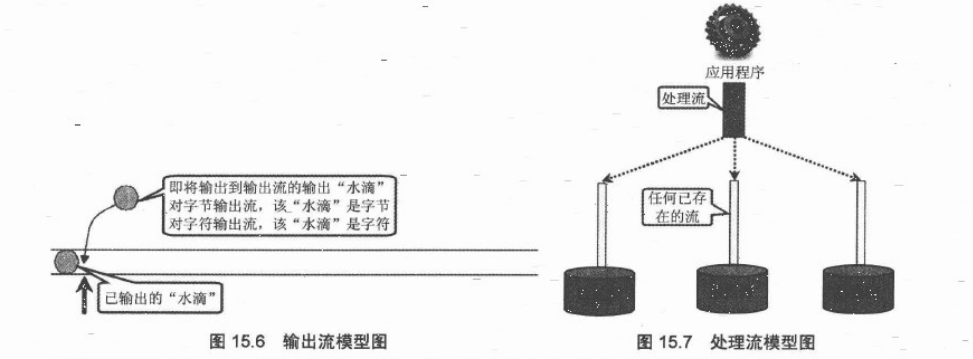
对于OutputStream和Writer而言,它们同样把输出设备抽象成一个”水管“,只是这个水管里面没有任何水滴,如图15.6所示:
正如图15.6所示,当执行输出时,程序相当于依次把“水滴”放入到输出流的水管中,输出流同样采用隐示指针来标识当前水滴即将放入的位置,每当程序向OutputStream或者Writer里面输出一个或者多个水滴后,记录指针自动向后移动。
图15.5和图15.6显示了java Io的基本概念模型,除此之外,Java的处理流模型则体现了Java输入和输出流设计的灵活性。处理流的功能主要体现在以下两个方面。
处理流可以“嫁接”在任何已存在的流的基础之上,这就允许Java应用程序采用相同的代码,透明的方式来访问不同的输入和输出设备的数据流。图15.7显示了处理流的模型。
1.3.2 java输入/输出流体系中常用的流的分类表
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象基类 | InputStream | OutputStream | Reader | Writer |
| 访问文件 | FileInputStream | FileOutputStream | FileReader | FileWriter |
| 访问数组 | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter |
| 访问管道 | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter |
| 访问字符串 | StringReader | StringWriter | ||
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| 转换流 | InputStreamReader | OutputStreamWriter | ||
| 对象流 | ObjectInputStream | ObjectOutputStream | ||
| 抽象基类 | FilterInputStream | FilterOutputStream | FilterReader | FilterWriter |
| 打印流 | PrintStream | PrintWriter | ||
| 推回输入流 | PushbackInputStream | PushbackReader | ||
| 特殊流 | DataInputStream | DataOutputStream |
注:表中粗体字所标出的类代表节点流,必须直接与指定的物理节点关联:斜体字标出的类代表抽象基类,无法直接创建实例。
下面是整理的常用的Io流的特性及使用方法,只有清楚每个Io流的特性和方法。才能在不同的需求面前正确的选择对应的IO流进行开发。
2.1 Io体系的基类(InputStream/Reader,OutputStream/Writer)。
字节流和字符流的操作方式基本一致,只是操作的数据单元不同——字节流的操作单元是字节,字符流的操作单元是字符。所以字节流和字符流就整理在一起了。
InputStream和Reader是所有输入流的抽象基类,本身并不能创建实例来执行输入,但它们将成为所有输入流的模板,所以它们的方法是所有输入流都可使用的方法。
在InputStream里面包含如下3个方法。
在Reader中包含如下3个方法。
int read(char[] b,int off,int len); 从输入流中最多读取len个字符的数据,并将其存储在数组b中,放入数组b中时,并不是从数组起点开始,而是从off位置开始,返回实际读取的字符数。
对比InputStream和Reader所提供的方法,就不难发现这两个基类的功能基本是一样的。InputStream和Reader都是将输入数据抽象成如图15.5所示的水管,所以程序即可以通过read()方法每次读取一个”水滴“,也可以通过read(char[] chuf)或者read(byte[] b)方法来读取多个“水滴”。当使用数组作为read()方法中的参数, 我们可以理解为使用一个“竹筒”到如图15.5所示的水管中取水,如图15.8所示read(char[] cbuf)方法的参数可以理解成一个”竹筒“,程序每次调用输入流read(char[] cbuf)或read(byte[] b)方法,就相当于用“竹筒”从输入流中取出一筒“水滴”,程序得到“竹筒”里面的”水滴“后,转换成相应的数据即可;程序多次重复这个“取水”过程,直到最后。程序如何判断取水取到了最后呢?直到read(char[] chuf)或者read(byte[] b)方法返回-1,即表明到了输入流的结束点。
InputStream和Reader提供的一些移动指针的方法:
OutputStream和Writer:
OutputStream和Writer的用法也非常相似,它们采用如图15.6所示的模型来执行输入,两个流都提供了如下三个方法:
因为字符流直接以字符作为操作单位,所以Writer可以用字符串来代替字符数组,即以String对象作为参数。Writer里面还包含如下两个方法。
2.2 Io体系的基类文件流的使用(FileInputStream/FileReader ,FileOutputStream/FileWriter)
前面说过InputStream和Reader都是抽象类,本身不能创建实例,但它们分别有一个用于读取文件的输入流:FileInputStream和FileReader,它们都是节点流——会直接和指定文件关联。下面程序示范使用FileInputStream和FileReader。
使用FileInputStream读取文件:
public class MyClass { public static void main(String[] args)throws IOException{ FileInputStream fis=null; try { //创建字节输入流 fis=new FileInputStream("E:\\learnproject\\Iotest\\lib\\src\\main\\java\\com\\Test.txt"); //创建一个长度为1024的竹筒 byte[] b=new byte[1024]; //用于保存的实际字节数 int hasRead=0; //使用循环来重复取水的过程 while((hasRead=fis.read(b))>0){ //取出竹筒中的水滴(字节),将字节数组转换成字符串进行输出 System.out.print(new String(b,0,hasRead)); } }catch (IOException e){ e.printStackTrace(); }finally { fis.close(); } } }
注:上面程序最后使用了fis.close()来关闭该文件的输入流,与JDBC编程一样,程序里面打开的文件IO资源不属于内存的资源,垃圾回收机制无法回收该资源,所以应该显示的关闭打开的IO资源。Java 7改写了所有的IO资源类,它们都实现了AntoCloseable接口,因此都可以通过自动关闭资源的try语句来关闭这些Io流。
使用FileReader读取文件:
public class FileReaderTest { public static void main(String[] args)throws IOException{ FileReader fis=null; try { //创建字节输入流 fis=new FileReader("E:\\learnproject\\Iotest\\lib\\src\\main\\java\\com\\Test.txt"); //创建一个长度为1024的竹筒 char[] b=new char[1024]; //用于保存的实际字节数 int hasRead=0; //使用循环来重复取水的过程 while((hasRead=fis.read(b))>0){ //取出竹筒中的水滴(字节),将字节数组转换成字符串进行输出 System.out.print(new String(b,0,hasRead)); } }catch (IOException e){ e.printStackTrace(); }finally { fis.close(); } } }
可以看出使用FileInputStream和FileReader进行文件的读写并没有什么区别,只是操作单元不同而且。
FileOutputStream/FileWriter是Io中的文件输出流,下面介绍这两个类的用法。
FileOutputStream的用法:
public class FileOutputStreamTest { public static void main(String[] args)throws IOException { FileInputStream fis=null; FileOutputStream fos=null; try { //创建字节输入流 fis=new FileInputStream("E:\\learnproject\\Iotest\\lib\\src\\main\\java\\com\\Test.txt"); //创建字节输出流 fos=new FileOutputStream("E:\\learnproject\\Iotest\\lib\\src\\main\\java\\com\\newTest.txt"); byte[] b=new byte[1024]; int hasRead=0; //循环从输入流中取出数据 while((hasRead=fis.read(b))>0){ //每读取一次,即写入文件输入流,读了多少,就写多少。 fos.write(b,0,hasRead); } }catch (IOException e){ e.printStackTrace(); }finally { fis.close(); fos.close(); } } }
运行程序可以看到输出流指定的目录下多了一个文件:newTest.txt, 该文件的内容和Test.txt文件的内容完全相同。FileWriter的使用方式和FileOutputStream基本类似,这里就带过。
注: 使用java的io流执行输出时,不要忘记关闭输出流,关闭输出流除了可以保证流的物理资源被回收之外,可能还可以将输出流缓冲区中的数据flush到物理节点中里(因为在执行close()方法之前,自动执行输出流的flush()方法)。java很多输出流默认都提供了缓存功能,其实我们没有必要刻意去记忆哪些流有缓存功能,哪些流没有,只有正常关闭所有的输出流即可保证程序正常。
缓冲流的使用(BufferedInputStream/BufferedReader, BufferedOutputStream/BufferedWriter):
下面介绍字节缓存流的用法(字符缓存流的用法和字节缓存流一致就不介绍了):
public class BufferedStreamTest { public static void main(String[] args)throws IOException { FileInputStream fis=null; FileOutputStream fos=null; BufferedInputStream bis=null; BufferedOutputStream bos=null; try { //创建字节输入流 fis=new FileInputStream("E:\\learnproject\\Iotest\\lib\\src\\main\\java\\com\\Test.txt"); //创建字节输出流 fos=new FileOutputStream("E:\\learnproject\\Iotest\\lib\\src\\main\\java\\com\\newTest.txt"); //创建字节缓存输入流 bis=new BufferedInputStream(fis); //创建字节缓存输出流 bos=new BufferedOutputStream(fos); byte[] b=new byte[1024]; int hasRead=0; //循环从缓存流中读取数据 while((hasRead=bis.read(b))>0){ //向缓存流中写入数据,读取多少写入多少 bos.write(b,0,hasRead); } }catch (IOException e){ e.printStackTrace(); }finally { bis.close(); bos.close(); } } }
可以看到使用字节缓存流读取和写入数据的方式和文件流(FileInputStream,FileOutputStream)并没有什么不同,只是把处理流套接到文件流上进行读写。缓存流的原理下节介绍。
上面代码中我们使用了缓存流和文件流,但是我们只关闭了缓存流。这个需要注意一下,当我们使用处理流套接到节点流上的使用的时候,只需要关闭最上层的处理就可以了。java会自动帮我们关闭下层的节点流。
2.3 转换流的使用(InputStreamReader/OutputStreamWriter):
下面以获取键盘输入为例来介绍转换流的用法。java使用System.in代表输入。即键盘输入,但这个标准输入流是InputStream类的实例,使用不太方便,而且键盘输入内容都是文本内容,所以可以使用InputStreamReader将其包装成BufferedReader,利用BufferedReader的readLine()方法可以一次读取一行内容,如下代码所示:
public class InputStreamReaderTest { public static void main(String[] args)throws IOException { try { // 将System.in对象转化为Reader对象 InputStreamReader reader=new InputStreamReader(System.in); //将普通的Reader包装成BufferedReader BufferedReader bufferedReader=new BufferedReader(reader); String buffer=null; while ((buffer=bufferedReader.readLine())!=null){ // 如果读取到的字符串为“exit”,则程序退出 if(buffer.equals("exit")){ System.exit(1); } //打印读取的内容 System.out.print("输入内容:"+buffer); } }catch (IOException e){ e.printStackTrace(); }finally { } } }
上面程序将System.in包装成BufferedReader,BufferedReader流具有缓存功能,它可以一次读取一行文本——以换行符为标志,如果它没有读到换行符,则程序堵塞。等到读到换行符为止。运行上面程序可以发现这个特征,当我们在控制台执行输入时,只有按下回车键,程序才会打印出刚刚输入的内容。
2.4 对象流的使用(ObjectInputStream/ObjectOutputStream)的使用:
写入对象:
public static void writeObject(){ OutputStream outputStream=null; BufferedOutputStream buf=null; ObjectOutputStream obj=null; try { //序列化文件輸出流 outputStream=new FileOutputStream("E:\\learnproject\\Iotest\\lib\\src\\main\\java\\com\\myfile.tmp"); //构建缓冲流 buf=new BufferedOutputStream(outputStream); //构建字符输出的对象流 obj=new ObjectOutputStream(buf); //序列化数据写入 obj.writeObject(new Person("A", 21));//Person对象 //关闭流 obj.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
读取对象:
/** * 读取对象 */ public static void readObject() throws IOException { try { InputStream inputStream=new FileInputStream("E:\\learnproject\\Iotest\\lib\\src\\main\\java\\com\\myfile.tmp"); //构建缓冲流 BufferedInputStream buf=new BufferedInputStream(inputStream); //构建字符输入的对象流 ObjectInputStream obj=new ObjectInputStream(buf); Person tempPerson=(Person)obj.readObject(); System.out.println("Person对象为:"+tempPerson); //关闭流 obj.close(); buf.close(); inputStream.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } }
一些注意事项
1.读取顺序和写入顺序一定要一致,不然会读取出错。
2.在对象属性前面加transient关键字,则该对象的属性不会被序列化。
我们使用InputStream从输入流中读取数据时,如果没有读取到有效的数据,程序将在此处阻塞该线程的执行。其实传统的输入里和输出流都是阻塞式的进行输入和输出。 不仅如此,传统的输入流、输出流都是通过字节的移动来处理的(即使我们不直接处理字节流,但底层实现还是依赖于字节处理),也就是说,面向流的输入和输出一次只能处理一个字节,因此面向流的输入和输出系统效率通常不高。
从JDk1.4开始,java提供了一系列改进的输入和输出处理的新功能,这些功能被统称为新IO(NIO)。新增了许多用于处理输入和输出的类,这些类都被放在java.nio包及其子包下,并且对原io的很多类都以NIO为基础进行了改写。新增了满足NIO的功能。
NIO采用了内存映射对象的方式来处理输入和输出,NIO将文件或者文件的一块区域映射到内存中,这样就可以像访问内存一样来访问文件了。通过这种方式来进行输入/输出比传统的输入和输出要快的多。
JDk1.4使用NIO改写了传统Io后,传统Io的读写速度和NIO差不了太多。
了解了java io的整体类结构和每个类的一下特性后,我们可以在开发的过程中根据需要灵活的使用不同的Io流进行开发。下面是我整理2点原则:
标签:应该 project 读取 指定 输出流 stat 字符 指针 流的概念
原文地址:https://www.cnblogs.com/lucky1024/p/11022606.html