标签:mp4 info tor cal 名称 cut https gecko 面向对象
# 爬虫全过程:
# 1.发送请求(请求库)
# requests
# selenium
# 2.获取相应数据(服务器返回)
# 3.解析并提取数据(解析库)
# re正则
# bs4(beautifulsoup4)
# Xpath
# 4.保存数据(存储库)
# mongDB
# 爬虫框架
# Scrapy(基于面向对象)
# requests模块详细使用
# http协议:
# 请求url:
#
# 请求方式:
# GET
# 请求头:
# Cookie:可能需要关注
# User-Agent:用来证明自己是浏览器
#import requests
# response=requests.get()
# print(response.status_code)
# print(response.text)
# 携带请求头参数访问知乎
# import requests
# # 请求字典
# headers={‘user-agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36‘
#
# }
# # 在get请求内,添加user-agent
# response=requests.get(url=‘https://www.zhihu.com/explore‘,headers=headers)
# print(response.status_code)
# with open(‘zhihu.html‘,‘w‘,encoding=‘utf-8‘) as f:
# f.write(response.text)
#
# 携带cookies
# 携带登录cookies破解github登录验证
# 请求url:。。。。
# 请求方式:。。。。
# 请求头:。。。。
import requests
url=‘https://home.cnblogs.com/set/‘
headers={‘user-agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36‘,
‘Cookies‘:‘_ga=GA1.2.736039140.1560498371; _gid=GA1.2.393939017.1560498371; __gads=ID=22042d69ef7c440a:T=1560498371:S=ALNI_MZjbBvbmYulhYR0hD7DDAvxO0aolQ; .Cnblogs.AspNetCore.Cookies=CfDJ8D8Q4oM3DPZMgpKI1MnYlrl5aDQbB7qHF12lN377FcJeizO5Dr4IA_1e7Aq8woZhTxdhKDrbe8NA3gDFqxX5fXn7Op4tblZ3WlqCLIBc9yYqTekcG0jfa9xAH-ur9i-QKr9dvFLlxL1TVSknTiV9iA9nxENBL_WJqnpg8Lo7M5DkfKd0hslNAvuFza9WE3InaBkqJom6ThPvt0z-LN0yviYk5duwVIT8HM1tfOHM2KT_ERkPqKSUTgVRKYGKWrMsG89yDtjKBL1lp0IjzQtzIzK0215tgd3fh0guFL2U994D-ZgHTQthJ0ZZErBUrZ3Z2aHMiJnHXVJLWW3NWAlRuk-R4snWbHpJt8diYsfn-P-q79Ms2SmCAKEg8Vqzf41Qb5lYT_qvGWw0vU3uZwglGwb6KycLuTwKVIXYcrrmgR_F5mFa6MnIoylo1ljVhgRROZgBVQz15SMONXFGTpaX8zI; .CNBlogsCookie=A7F62226302E1403835FB5491EFFE521C6FEB4D05375BC64EC3B87D308A75E4372DBFD7E26B197F93A52D7C4212BA3EF74F4A65A51B7CA92266DAA7F0365C3C7FE6BA6294557EF3FB7CAB11990D3E5723D5FEB51; _gat=1‘}
github_res=requests.get(url, headers=headers)
import requests
cookies={‘Cookies‘:‘_ga=GA1.2.736039140.1560498371; _gid=GA1.2.393939017.1560498371; __gads=ID=22042d69ef7c440a:T=1560498371:S=ALNI_MZjbBvbmYulhYR0hD7DDAvxO0aolQ; .Cnblogs.AspNetCore.Cookies=CfDJ8D8Q4oM3DPZMgpKI1MnYlrl5aDQbB7qHF12lN377FcJeizO5Dr4IA_1e7Aq8woZhTxdhKDrbe8NA3gDFqxX5fXn7Op4tblZ3WlqCLIBc9yYqTekcG0jfa9xAH-ur9i-QKr9dvFLlxL1TVSknTiV9iA9nxENBL_WJqnpg8Lo7M5DkfKd0hslNAvuFza9WE3InaBkqJom6ThPvt0z-LN0yviYk5duwVIT8HM1tfOHM2KT_ERkPqKSUTgVRKYGKWrMsG89yDtjKBL1lp0IjzQtzIzK0215tgd3fh0guFL2U994D-ZgHTQthJ0ZZErBUrZ3Z2aHMiJnHXVJLWW3NWAlRuk-R4snWbHpJt8diYsfn-P-q79Ms2SmCAKEg8Vqzf41Qb5lYT_qvGWw0vU3uZwglGwb6KycLuTwKVIXYcrrmgR_F5mFa6MnIoylo1ljVhgRROZgBVQz15SMONXFGTpaX8zI; .CNBlogsCookie=A7F62226302E1403835FB5491EFFE521C6FEB4D05375BC64EC3B87D308A75E4372DBFD7E26B197F93A52D7C4212BA3EF74F4A65A51B7CA92266DAA7F0365C3C7FE6BA6294557EF3FB7CAB11990D3E5723D5FEB51; _gat=1‘}
github_res=requests.get(url,headers=headers,cookies=cookies)
print(‘2545976330@qq.com‘ in github_res.text)
多线程爬虫
# 3.6python解释器 3.7报错shutdown
import requests
import re
import uuid
from concurrent.futures import ThreadPoolExecutor#导入线程池模块
pool=ThreadPoolExecutor(50)#线程池限制50个线程
# 爬虫三部曲
# 1.发送请求
def get_page(url):
print(f‘开始异步任务:{url}‘)
response=requests.get(url)
return response
# 2.解析数据
# 解析主页获取视频详情ID
def parse_index(res):
response=res.result()
id_list = re.findall(‘<a href="video_(.*?)"‘, response.text, re.S)
for m_id in id_list:
detail_url = ‘https://www.pearvideo.com/video_‘ + m_id
pool.submit(get_page,detail_url).add_done_callback(parse_detail)
# 解析详情页获取视频url
def parse_detail(res):
response=res.result()
movie_url=re.findall(‘srcUrl="(.*?)"‘,response.text,re.S)[0]
pool.submit(get_page, movie_url).add_done_callback(save_movie)
# 保存数据
def save_movie(res):
movie_res=res.result()
with open(f‘{uuid.uuid4()}.mp4‘,‘wb‘)as f:
f.write(movie_res.content)
print(f‘视频下载结束:{movie_res.url}‘)
f.flush()
if __name__ == ‘__main__‘:
url=‘https://www.pearvideo.com/‘
pool.submit(get_page, url).add_done_callback(parse_index)
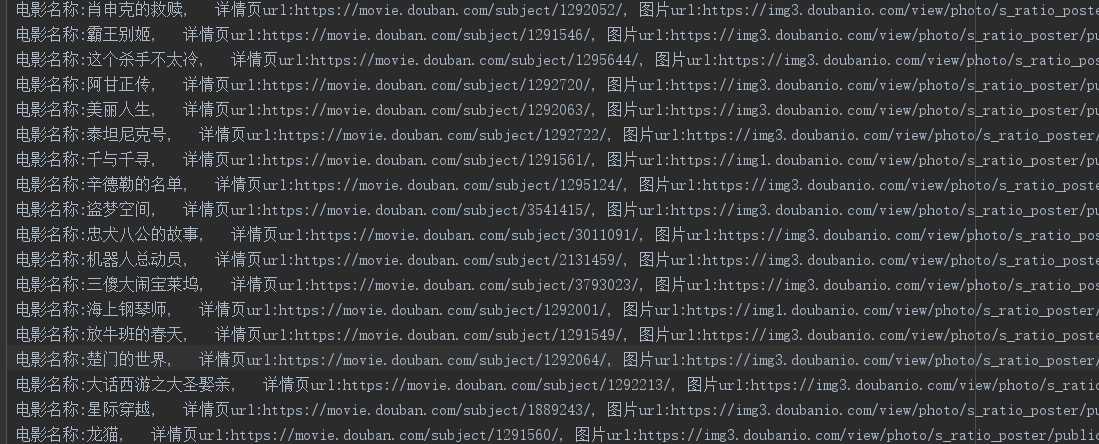
爬取豆瓣部分电影相关信息
‘‘‘‘‘‘
‘‘‘
主页:
https://movie.douban.com/top250
GET
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36
re正则:
# 电影详情页url、图片链接、电影名称、电影评分、评价人数
<div class="item">.*?href="(.*?)">.*?src="(.*?)".*?<span class="title">(.*?)</span>.*?<span class="rating_num".*?>(.*?)</span>.*?<span>(.*?)人评价
‘‘‘
import requests
import re
url = ‘https://movie.douban.com/top250‘
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36‘
}
# 1、往豆瓣TOP250发送请求获取响应数据
response = requests.get(url, headers=headers)
# print(response.text)
# 2、通过正则解析提取数据
# 电影详情页url、图片链接、电影名称、电影评分、评价人数
movie_content_list = re.findall(
# 正则规则
‘<div class="item">.*?href="(.*?)">.*?src="(.*?)".*?<span class="title">(.*?)</span>.*?<span class="rating_num".*?>(.*?)</span>.*?<span>(.*?)人评价‘,
# 解析文本
response.text,
# 匹配模式
re.S)
for movie_content in movie_content_list:
# 解压赋值每一部电影
detail_url, movie_jpg, name, point, num = movie_content
data = f‘电影名称:{name}, 详情页url:{detail_url}, 图片url:{movie_jpg}, 评分: {point}, 评价人数: {num} \n‘
print(data)
# 3、保存数据,把电影信息写入文件中
with open(‘douban.txt‘, ‘a‘, encoding=‘utf-8‘) as f:
f.write(data)
标签:mp4 info tor cal 名称 cut https gecko 面向对象
原文地址:https://www.cnblogs.com/7777qqq/p/11025103.html