标签:figure UNC keep 游离 文件中 sele 用户 style 移动
Hibernate:是一持久层的ORM的框架,能够减轻dao层的编码
ORM:Object Relational Mapping(对象关系映射)能够将java中对象与关系型数据库中的表建立联系,操作java对象即可对操作数据库中的表
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<!-- 建立类与表的映射 -->
<class name="Demo.Customer" table="cst_customer">
<!-- 建立属性与主键的映射 -->
<id name="cust_id" column="cust_id">
<!-- 生成规则 -->
<generator class="native"/>
</id>
<!-- 建立其他属性与表列字段的映射 -->
<property name="cust_name" column="cust_name"/>
<property name="cust_source" column="cust_source"/>
<property name="cust_industry" column="cust_industry"/>
<property name="cust_level" column="cust_level"/>
<property name="cust_phone" column="cust_phone"/>
<property name="cust_mobile" column="cust_mobile"/>
</class>
</hibernate-mapping><?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 配置连接mysql数据库的相关信息 -->
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql:///hibernate01</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">123456</property>
<!-- 配置hibernate方言 -->
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<!-- 可选配置 -->
<!-- 打印sql语句 -->
<property name="hibernate.show_sql">true</property>
<!-- 格式化sql语句 -->
<property name="hibernate.format_sql">true</property>
<!-- 自动创建表 update:如果数据库中没有相应的表,则会根据映射关系创建,如果有,则使用已存在的表-->
<property name="hibernate.hbm2ddl.auto">update</property>
<!-- 引入映射文件 -->
<mapping resource="Demo/Customer.hbm.xml"/>
</session-factory>
</hibernate-configuration>1:Configuration:加载hibernate核心配置文件
加载hibernate.properties :Configuration cfg=new Configuration();
但通常是加载hibernate.cfg.xml :Configuration cfg=new Configuration().configure();
2:SessionFactory:Session工厂
SessionFactory内部维护了hibernate连接池和hibernate二级缓存,线程安全,一个项目只需一个SessionFactory
3:Session:此时指的是hibernate里的session,线程是不安全的(应放在方法内部调用)是与数据库连接的桥梁
API:1)保存
Serializable save(Object object) 返回一个相对应的ID
2)查询
Object get(Object.class,Serializabel ID)
Customer customer = session.get(Customer.class,1l);Object load(Object.class,Serializabel ID)
Customer load = session.load(Customer.class, 2l);get与load查询的区别:
a:get方法执行到查询语句后立即发出sql语句查询,load查询执行时不会立即发出sql语句,在逼不得已需要使用时才会查询(lazy,懒查询)
b:get查询后返回的是对象本身,load查询返回的是代理对象,利用javassist产生代理
c:get查询查不到时会返回null,load查询查不到时返回ObjectNotFoundException
3)更新
void update(Object object)
public void Demo3(){
//更新
Session session = HibernateUtils.openSession();
Transaction ts = session.beginTransaction();
//1,先创建对象,再更新,会造成其他字节段的值为null,不推荐
/*Customer customer=new Customer();
customer.setCust_id(1l);
customer.setCust_name("赵六");*/
//2,先查询,再更新,指改变指定的字节段的值,推荐
Customer customer = session.get(Customer.class,1l);
customer.setCust_name("赵六");
session.update(customer);
ts.commit();
session.close();
}4)删除
void delete()
public void Demo4(){
//删除
Session session = HibernateUtils.openSession();
Transaction ts = session.beginTransaction();
//1,先创建对象,再删除,只会删除当前表的值,不会造成级联删除,即由关联的表的数据也一起删除
/*Customer customer=new Customer();
customer.setCust_id(1l);
session.delete(customer);*/
//2,先查询,再删除,可以级联删除,推荐
Customer customer = session.get(Customer.class,1l);
session.delete(customer);
ts.commit();
session.close();
}5)查询一个表的所有数据
public void Demo5(){
//查询所有
Session session = HibernateUtils.openSession();
Transaction ts = session.beginTransaction();
//接受HQL:Hibernate Sql Language(常用)
Query query = session.createQuery("from Customer");
List<Customer> list = query.list();
for (Customer customer : list) {
System.out.println(customer);
}
//接受Sql(不常用)
/*SQLQuery sqlQuery = session.createSQLQuery("select * from cst_customer");
List<Object[]> list = sqlQuery.list();
for (Object[] object : list) {
System.out.println(Arrays.toString(object));
}*/
ts.commit();
session.close();
}4:Transaction,事务,以后主要交给Spring
主要API commit() 提交事务 rollback( )回滚事务
持久化类=类+映射文件 ,将java对象与数据库的表建立联系,使数据可以存储再数据库中(硬盘里)
1,类中的属性私,且尽量用引用数据类型(包装类型修饰)提供get,set方法
2,类不要用final修饰,如果用final修饰,则不能被继承,影响延迟加载如load()查询会与get()变得一样
3,提供无参构造方法,hibernate底层会利用发射创建类的实例对象
4,对持久化类提供一个唯一表示OID与数据库主键对应,hibernate底层通过该ID来识别是否时同一个对象
<!-- 建立属性与主键的映射 -->
<id name="cust_id" column="cust_id">
<!-- 生成规则 -->
<generator class="native"/>
</id>
1,主键的分类
自然主键:主键是表字段的一部分,如身份证表利用身份证号充当主键
代理主键:主键不属于表字段 ,一般建议用代理主键,可以在不更改源码的情况下扩展
2,Hibernate中主键的生成策略
1)increment,适用于int,short,long 的主键,hibernate中提供的自动增长机制,在单线程中使用,首先发送一条sql语句,select max(id) from 表,然后id+1
2)identity ,使用于int,short,long,由数据库底层提供的自动增长机制,使用于MySQL等
3)sequence,适用于short,int,long,采用序列方式,使用于Oracle数据库,mysql不使用
4)uuid,适用于String 类型,由hibernate提供随机字符串
5)native ,本地策略,可以在identity和sequence来回切换,区别于用啥数据库
6)assigned,需要手动编写程序或是用户自己设置,hibernate放弃外键的管理
//持久化类的三种状态
@Test
public void Demo01(){
Customer customer=new Customer();//此时customer处于瞬时态,没有OID,没有被session接管
Session session = HibernateUtils.openSession();
Transaction ts = session.beginTransaction();
customer.setCust_name("哈哈");
session.save(customer);//customer处于持久态,数据存入数据库中,则有OID标识,且此时被session接管
ts.commit();
session.close();
System.out.println(customer.getCust_name());//处于脱管态,有OID,但没被session接管
}1:三种状态之间的转换
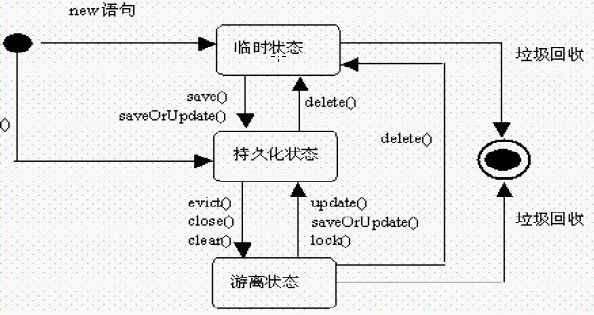
2:主要了解持久化对象 -对象有OID标识,且被session接管
特点:持久化类处于持久态时,更新的数据可以自动存到数据库中
底层依赖于Hibernate一级缓存
public void Demo02(){
//处于持久态,更新数据自动存储到数据库中
Session session = HibernateUtils.openSession();
Transaction ts = session.beginTransaction();
Customer customer = session.get(Customer.class,1l);//处于持久态
customer.setCust_phone("110911");
//不需要写session.update(customer);
ts.commit();
session.close();
}缓存:将数据或对象放入内存中,不直接通过硬盘
作用:降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能。
hibernate缓存分为两个级别,一级缓存(自带)和二级缓存(需要配置,一般不常用),用Redis代替
一级缓存:
Session级别的缓存,生命周期与session同步,由session中一系列数组组成
数据放入缓存:
1. save()。当session对象调用save()方法保存一个对象后,该对象会被放入到session的缓存中。
2. get()和load()。当session对象调用get()或load()方法从数据库取出一个对象后,该对象也会被放入到session的缓存中。
3. 使用HQL和QBC等从数据库中查询数据。
证明一级缓存的存在:
//证明一级缓存的存在
@Test
public void Demo01(){
Session session = HibernateUtils.openSession();
Transaction ts = session.beginTransaction();
Customer customer=new Customer();
customer.setCust_name("李想");
Serializable id = session.save(customer);//此时对象也被放入了缓存中
Customer customer2 = session.get(Customer.class, id);//此时会根据对象OID去缓存中查询,如果有,则不会发送查询sql语句
System.out.println(customer2==customer);//判断两个对象是否是同一个
ts.commit();
session.close();
}测试demo运行结果:
Hibernate:
insert
into
cst_customer
(cust_name, cust_source, cust_industry, cust_level, cust_phone, cust_mobile)
values
(?, ?, ?, ?, ?, ?)
true
数据从缓存中清除:
1. evit()将指定的持久化对象从缓存中清除,释放对象所占用的内存资源,指定对象从持久化状态变为脱管状态,从而成为游离对象。
2. clear()将缓存中的所有持久化对象清除,释放其占用的内存资源。
其他缓存操作:
1. contains()判断指定的对象是否存在于缓存中。
2. flush()刷新缓存区的内容,使之与数据库数据保持同步。
一级缓冲区中的结构:
里面有很多的map,map的key,和value分别为缓存区,和快照区,当在持久态时更新数据并提交事务时,数据提交到缓冲区后,会与快照区的数据进行对比,如果一样快照区不变,如果不同,则会将更改的数据自动更新到数据库中
注意:
一个session不能取另一个session中的内容
二级缓存:
SessionFactory级别的缓存,可以跨越Session存在,可以被多个Session所共享。
详细参考:http://www.cnblogs.com/200911/archive/2012/10/09/2716873.html
事务的特性:
原子性:事务是一个不可分割的工作单位,要么发生,要么不发生
一致性:一个事务中,事务前后数据的完整性必须一致
隔离性:多个事务之间互不干扰
持久性:事务一旦被提交,提交到数据库中的数据就是永久性的
并发问题:脏读,不重复度,虚度/幻读
解决并发:设置隔离级别
read uncommitted(无法解决问题)
read committed(解决脏读,oracle默认隔离级别)
repeatable read(解决不重复读和脏读,mysql默认隔离级别)
serializable(都可以解决,但是相当与一个锁表,不能多个客户端向数据库写入数据)
在hibernate核心文件中配置hibernate事务隔离级别
<!-- 设置事务的隔离级别 4-解决不可重复度和脏读,repeatable read isolation-->
<property name="hibernate.connection.isolation">4</property>事务主要是作用在Service层,确保session是同一个,需要调用SessionFactory中的getCurrentSession()方法
//获取当前线程绑定的session,底层通过ThreadLocal类来绑定Session,当调用getCurrentSession()方法时,由hibernate帮我们绑定好了,但需要到核心配置文件配置
public static Session getCurrentSession(){
return se.getCurrentSession();
在hibernate核心配置文件中配置
<!-- 配置当前线程绑定的session -->
<property name="hibernate.current_session_context_class">thread</property>测试
@Test
public void Demo01(){
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
Customer customer=new Customer();
customer.setCust_name("赵强");
session.save(customer);
ts.commit();
//不需要再手动关闭事务 session.close(); 否者会报错!
}1,Query :通过Session session 获得
通过HQL(hibernate query language)的面向对象的查询
public void Demo02(){
Session session = HibernateUtils.getCurrentSession();
Transaction st = session.beginTransaction();
//模糊查询
//String hql="from Customer where cust_name like ?";
//分页查询
String hql="from Customer";
Query query = session.createQuery(hql);
//query.setParameter(0, "王%");
//利用分页方法设置起始页和每页显示条数
query.setFirstResult(3);//第二页开始
query.setMaxResults(3);
@SuppressWarnings("unchecked")
List<Customer> list = query.list();
for (Customer customer : list) {
System.out.println(customer);
}
st.commit();
}2,Criteria:也是通过Session session获得
QBC(query by criteria)适用于条件查询,更加倾向面向对象查询
public void Demo03(){
//Criteria
Session session = HibernateUtils.getCurrentSession();
Transaction st = session.beginTransaction();
//分页查询
Criteria criteria = session.createCriteria(Customer.class);
/*criteria.setFirstResult(0);
criteria.setMaxResults(3);*/
//条件查询
criteria.add(Restrictions.like("cust_name","王%"));
List<Customer> list = criteria.list();
for (Customer customer : list) {
System.out.println(customer);
}
st.commit();
}3:SQLQuery 通过sql语句查询
//接受Sql(不常用)
SQLQuery sqlQuery = session.createSQLQuery("select * from cst_customer");
List<Object[]> list = sqlQuery.list();
for (Object[] object : list) {
System.out.println(Arrays.toString(object));
}1,表于表之间的关系
一对多:在多的一方添加一的一方的主键为外键,在一的一方实体放入多的实体的集合,在多的一方实体放入一的一方的对象
多对多:建立一个中间表,至少将两个多对多的表的主键充当字段
一对一:实现是可以其中一表唯一外键或是两个表主键对应
详细参考:https://blog.csdn.net/ago52030/article/details/1721033
2,hibernate中一对多的映射配置:(配置完成后需要将映射文件引入核心配置文件中)
多的一方表的映射配置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="Demo.LinkMan" table="cst_linkman">
<id name="lkm_id" column="lkm_id">
<generator class="native" />
</id>
<!-- name与column值一样时,column可以省略 -->
<properties name="lkm_name" />
<properties name="lkm_cust_id" />
<properties name="lkm_gender" />
<properties name="lkm_phone" />
<properties name="lkm_mobile" />
<properties name="lkm_email" />
<properties name="lkm_qq" />
<properties name="lkm_position" />
<properties name="lkm_memo" />
<!--
name:一的一方对象名称
class:一的一方类的全路径
column:多的一方表的外键字段名
-->
<many-to-one name="customer" class="Demo.Customer" column="lkm_cust_id" />
</class>
</hibernate-mapping>一的一方映射配置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<!-- 建立类与表的映射 -->
<class name="Demo.Customer" table="cst_customer">
<!-- 建立属性与主键的映射 -->
<id name="cust_id" column="cust_id">
<!-- 主键生成规则 -->
<generator class="native"/>
</id>
<!-- 建立其他属性与表列字段的映射 -->
<property name="cust_name" column="cust_name"/>
<property name="cust_source" column="cust_source"/>
<property name="cust_industry" column="cust_industry"/>
<property name="cust_level" column="cust_level"/>
<property name="cust_phone" column="cust_phone"/>
<property name="cust_mobile" column="cust_mobile"/>
<!--
name:多的一方集合的属性名称
column:多的一方的外键名称
class:多的一方实体的全路径
-->
<set name="linkMans">
<key column="lkm_cust_id"/>
<one-to-many class="Demo.LinkMan"/>
</set>
</class>
</hibernate-mapping>Hibernate一对多关系的级联设置
级联:对一个对象进行保存或更新,如果对象关联了其他对象,这会一同改变
一的一方进行级联配置:
<!--
name:多的一方集合的属性名称
column:多的一方的外键名称
class:多的一方实体的全路径
-->
<set name="linkMans" cascade="save-update">
<key column="lkm_cust_id"/>
<one-to-many class="Demo.LinkMan"/>
</set>多的一方进行级联配置:
<!--
name:一的一方对象名称
class:一的一方类的全路径
column:多的一方表的外键字段名
-->
<many-to-one name="customer" cascade="save-update" class="Demo.Customer" column="lkm_cust_id" />对象导航:只要两边映射文件都配置了级联,则只要互相设置了关联,只需要保存一方,另一方一会保存
级联删除:(多用于一的一方级联删除多的一方,先查询,再删除)
首先需要在一的一方映射文件配置:
<!--
name:多的一方集合的属性名称
column:多的一方的外键名称
class:多的一方实体的全路径
-->
<set name="linkMans" cascade="save-update,delete">
<key column="lkm_cust_id"/>
<one-to-many class="Demo.LinkMan"/>
</set>测试级联删除:
public void Demo04(){
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
Customer customer = session.get(Customer.class, 14l);
//删除客户时与之相关联的联系人也会被删除
session.delete(customer);
ts.commit();
}让一的一方放弃外键的维护
在一的一方的映射配置文件里设置 inverse="true" ,默认为false,可以避免产生多余的sql语句
<set name="linkMans" cascade="save-update,delete" inverse="true">
<key column="lkm_cust_id"/>
<one-to-many class="Demo.LinkMan"/>
</set>注意:一的一方放弃外键维护后,级联保存或更新一的一方,多的一方的外键无法随之更改,此时应级联操作多的一方
3:Hibernate中多对多表的实体创建和映射配置
例子:Role(角色表)于User(用户表)为多对多的关系,需要一个中间表
1,在两个表的实体里面分别创建对方对象的SET集合
//建立多对多的联系
private Set<Role> roles=new HashSet<>();
private Set<User> users=new HashSet<>();2,在两个表的映射文件里配置相互关系(以下只给出User映射文件的配置,Role表一样)
<!-- 建立与Role多对多的配置 -->
<!--
从上到下
nama:对方的set集合属性名
tabel:中间表的名称
column:当前表对应于中间表的外键名称
class:对方表的实体的类的全路径
column:对方表对应于中间表的外键名称
-->
<set name="roles" table="sys_user_role">
<key column="user_id" />
<many-to-many class="Demo.Role" column="role_id"/>
</set>3,之后将两个表的映射文件映入hibernate核心配置文件里
<mapping resource="Demo/Role.hbm.xml"/>
<mapping resource="Demo/User.hbm.xml"/>注意:两个多对多的表设置了相互关联后,需要其中一表放弃外键维护,一般是被动(被选)的表放弃,在其映射文件里设置inverse="true",该例子中被选表是Role(角色表)
4,多对多的级联删除(基本不用)
public void Demo06(){
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
User user = session.get(User.class, 1l);
session.delete(user);
ts.commit();
}5,一般进行User表对Role表的增删改,是对集合的操作
public void Demo07(){
//移除role_id 为8的角色
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
User user = session.get(User.class, 2l);
Role role = session.get(Role.class, 8l);
user.getRoles().remove(role);
ts.commit();
}1,OID查询
session.get() , session.load()
2,对象导航查询
根据OID查询到的对象的基础上级联查询
例:Customer customer =Session.get(LinkMan.class,1l).getCustomer();
List<LinkMan> list=Session.get(Customer.class,1l).getLinkmans();
3,HQL(Hibernate Query Language)查询
简单查询所有:上面写过
排序查询:
asc(升序)默认, desc(降序)
public void Demo08(){
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
List<Customer> list = session.createQuery("from Customer order by cust_id desc").list();
for (Customer customer : list) {
System.out.println(customer);
}
ts.commit();
}条件查询:
public void Demo09(){
//条件查询
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
//1,按位置绑定
/*Query query = session.createQuery("from Customer where cust_id=? and cust_source=?");
query.setParameter(0,6l);
query.setParameter(1, "无中生有");*/
//2,按名称绑定
Query query = session.createQuery("from Customer where cust_id=:a and cust_source=:b");
query.setParameter("a", 6l);
query.setParameter("b","无中生有");
List<Customer> list = query.list();
for (Customer customer : list) {
System.out.println(customer);
}
ts.commit();
}投影查询&分页查询:
public void Demo10(){
//投影查询&分页查询
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
//投影查询,查询对象的属性
/*List<Object[]> list = session.createQuery("select c.cust_name,c.cust_source from Customer c").list();
for (Object[] objects : list) {
System.out.println(Arrays.toString(objects));
}*/
//将查询到的对象属性值封装到对象中,注意:在对应的实体包中需要有相对应的有参构造
@SuppressWarnings("unchecked")
List<Customer> list = session.createQuery("select new Customer(cust_name,cust_source) from Customer").list();
for (Customer customer : list) {
System.out.println(customer);
}
//分页查询
/*Query query = session.createQuery("from Customer");
query.setFirstResult(0);
query.setMaxResults(3);
List<Customer> list = query.list();
for (Customer customer : list) {
System.out.println(customer);
}*/
ts.commit();
}聚合函数查询&分组查询:
public void Demo11(){
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
//使用聚合函数count(),max(),min(),avg(),sum()
/*Long count = (Long) session.createQuery("select count(*) from Customer").uniqueResult();
System.out.println(count);*/
//分组查询
@SuppressWarnings("unchecked")
List<Object[]> list = session.createQuery("select cust_source,count(*) from Customer group by cust_source").list();
for (Object[] objects : list) {
System.out.println(Arrays.toString(objects));
}
ts.commit();
}4,QBC(Query By Criteria)更加面向对象的查询
简单查询所有:上面写过
排序查询:
public void Demo12(){
//asc:升序。desc:降序。这里演示的是降序
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
Criteria criteria = session.createCriteria(Customer.class);
criteria.addOrder(Order.desc("cust_id"));
List<Customer> list = criteria.list();
for (Customer customer : list) {
System.out.println(customer);
}
ts.commit();
}分页&条件查询:
public void Demo13(){
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
Criteria criteria = session.createCriteria(Customer.class);
//分页查询
/*criteria.setFirstResult(0);
criteria.setMaxResults(3);*/
/*条件查询
* eq:=
* gt:>
* ge:>=
* lt:<
* le:<=
* or
* in
* like
* */
/*Object parameter[]={"王宝强","大屌哥"};
criteria.add(Restrictions.in("cust_name",parameter));*/
criteria.add(Restrictions.eq("cust_source","召唤"));
List<Customer> list = criteria.list();
for (Customer customer : list) {
System.out.println(customer);
}
ts.commit();
}聚合条件查询&group by having
public void Demo14(){
//聚合函数查询(不常用)
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
Criteria criteria = session.createCriteria(Customer.class);
criteria.setProjection(Projections.rowCount());
Long count = (Long) criteria.uniqueResult();
System.out.println(count);
ts.commit();
}DetachedCriteria:离线条件查询(现阶段简单实现)
public void Demo15(){
/*
* 离线查询DetachedCriteria简单实现
* 以下两句一般会写在web层
* */
DetachedCriteria detachedCriteria=DetachedCriteria.forClass(Customer.class);
detachedCriteria.add(Restrictions.eq("cust_name","大屌哥"));
//会将detachedCriteria传到dao层
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
Criteria criteria = detachedCriteria.getExecutableCriteria(session);
List<Customer> list = criteria.list();
for (Customer customer : list) {
System.out.println(customer);
}
}6:HQL的多表查询
SQL多表查询:https://baijiahao.baidu.com/s?id=1598467381137881566&wfr=spider&for=pc
Hibernate内连接:
public void Demo16(){
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
//内连接,将查到的数据封装到数组里
/*List<Object[]> list = session.createQuery("from Customer c inner join c.linkMans").list();
for (Object[] objects : list) {
System.out.println(Arrays.toString(objects));
}*/
//迫切内连接,将查到的数据封装到Customer对象里
List<Customer> list = session.createQuery("select distinct c from Customer c inner join fetch c.linkMans").list();
for (Customer customer : list) {
System.out.println(customer);
}
ts.commit();
}Hibernate外连接:
public void Demo17(){
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
//左外连接
//List<Object[]> list = session.createQuery("from Customer c left outer join c.linkMans").list();
/*
* 右外连接
* List<Object[]> list = session.createQuery("from Customer c right outer join c.linkMans").list();
*/
/*for (Object[] objects : list) {
System.out.println(Arrays.toString(objects));
}*/
//迫切左外连接
List<Customer> list = session.createQuery("select distinct c from Customer c left outer join fetch c.linkMans").list();
for (Customer customer : list) {
System.out.println(customer);
}
ts.commit();
}7,SQL语句查询
利用sql语句查询
public void Demo18(){
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
SQLQuery sqlQuery = session.createSQLQuery("select * from sct_customer");
//将查询到的数据封装到实体对象里
sqlQuery.addEntity(Customer.class);
List<Customer> list = sqlQuery.list();
ts.commit();
}1,延迟加载:lazy(懒加载)原理是使用动态代理,执行到相关语句时不会立刻发送sql语句,到真正需要时才会发送
类级别的延迟加载
在持久类映射文件的<Class lazy="true" /> 上设置的延迟为类级别,默认为true
如何让lazy失效?
1)设置 lazy="false"
2) 持久类用final修饰,让其无法继承接口,则无法实现动态代理
3)Hibernate initialize(Object object)
关联级别的延迟加载
查询获取的对象后,查询其关联的对象是否采用延迟加载
可以在映射文件的关联设置里 <set lazy="true" /> 或是<many-to-one lazy="true" />设置延迟
2,抓取策略:
什么叫抓取策略:通过获取的对象抓取其关联的对象,需要发送sql语句查询,如何发送,是否加载延迟,以达到尽可能的优化
通过在<set /> 和<many-to-one />上设置 fetch 属性值,用于控制发送的sql语句的格式的,,搭配 lazy 属性值来达到抓取策略
<set />上fetch,lazy的设置:
fetch:select,join,subselect --控制发送sql的格式
lazy:true,false,exroa(最懒级别,查什么就只发送相关的sql语句)--控制延迟
一般开发都采用默认级别,即 fetch="select" lazy="true" 偶尔会采用fetch="join"
如果lazy="false". fetch="select" 或“subselect" 会一次性的发送所需要的sql语句,而不是延迟发送
当fetch="join"时,,一次性发送一条sql语句,此时lazy设置什么属性都无所谓
<many-to-one>上fetch,lazy的设置:
fetch:select,join(为迫切左外连接)
lazy:proxy,false,noproxy(基本不用)
常采用默认值:fetch="select" lazy="proxy" --其的取值于一的一方<Class lazy="" />的取值相关联 偶尔会采用fetch="join"
3:批量抓取(减少发送的sql语句,提供效率)
例子:Customer 与 LinkMan的一对多的关系
public void Demo20(){
//通过客户批量抓取联系人
//需要在Customer_hbm_xml的<set>中设置 batch-size="5"
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
List<Customer> list = session.createQuery("from Customer").list();
for (Customer customer : list) {
System.out.println(customer.getCust_name());
for (LinkMan linkMan:customer.getLinkMans()) {
System.out.println(linkMan.getLkm_name());
}
}
ts.commit();
}
@Test
public void Demo21(){
//通过联系人批量抓取客户
//需要在Customer_hbm_xml的<class>中设置 batch-size="5"
Session session = HibernateUtils.getCurrentSession();
Transaction ts = session.beginTransaction();
List<LinkMan> list = session.createQuery("from LinkMan").list();
for (LinkMan linkMan : list) {
System.out.println(linkMan.getLkm_name());
System.out.println(linkMan.getClass().getName());
}
ts.commit();
}标签:figure UNC keep 游离 文件中 sele 用户 style 移动
原文地址:https://www.cnblogs.com/wuba/p/11025828.html