标签:地址 表达 用户 ref 字段 cti 对比 更新 otn
最近利用端午假期,我把LiteDB的源码仔细的阅读了一遍,酣畅淋漓,确实收获了不少。后面将编写一系列关于LteDB的文章分享给大家,希望这么好的源码不要被埋没。
这是一个小型的.NET平台开源的NoSQL类型的轻量级文件数据库。特点是小和快,由于完全由C#‘编写,所以可以支持LINQ,创建数据库是一个单一文件,类似Sqlite。
关于它的中文介绍大家可以看一下.net前辈-数据之巅的博客:https://www.cnblogs.com/asxinyu/p/dotnet_Opensource_project_LiteDB.html
主要特点有:
1.NoSQL文件存储。这是和传统关系型数据库的主要区别;支持实体类的字段更新;
2.类似MongoDB的简单API;
3.完全使用C#代码,在.NET 4.0环境下编写,核心dll小巧,只有168K;
4.支持ACID事务处理;
5.可以进行写入失败的恢复;
6.存储到文件或者数据流中(类似MongoDB的GridFS);
7.类似Sqlite的单一文件存储;
8.支持文件索引,可以进行快速搜索;可以直接存储文件;
9.支持Linq查询;【这也许是C#编写最直接的好处】;
10.支持命令行操作数据库,官方提供了一个Shell command line;
11.完全开源和免费,包括商业使用;
我主要阅读的源码是0.0.8版本,这个版本是LiteDB最初版本。该版本虽然存在一些bug,但相对于后面的版本,该版本技术实现的很简单粗暴,入手比较快。后面分析的细节也是根据0.0.8版本进行的。
这里贴一张0.0.8版本的项目结构图:
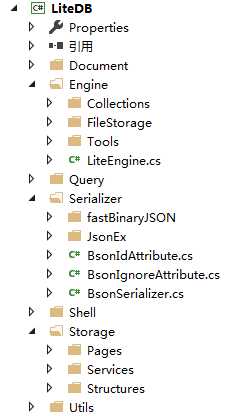
Document:LiteDB序列化到硬盘使用的是一种叫Bson格式的数据,顾名思义bson类似于json只不过将数据序列化成byte数组,在Document模块中定义了Bson的类、数组、数据类型等。
Engine:这个模块里就是与用户交互最多的LiteEngine类(后面的版本改名叫LiteDatabase)和LiteCollection类,LiteEngine对用户提供了创建或打开数据库的接口,LiteCollection是用来对单张表做增删改查操作,我们看源码,可以从这两个类作为突破点。
Query:这个模块提供了数据库对于Linq的支持,用户使用lambda表达式,在这个模块中的QueryVisitor类中被解析成一系列表达式比如:and、or、between、less等等。
Serializer:这个模块就提供了对于不同类型的数据进行Bson序列化,0.0.8版本使用了fastBinaryJSON这个开源组件,后面的版本不再使用。
Shell:这个模块为数据库提供了脚本支持。
Storage:这个文件夹里包括了整个LiteDB里最核心的三个实现模块即Pages、Structures、Services。
Pages:定义了数据库页:Header Page,Collection Page,Index Page, Data Page,Extend Page。
Structures:定义了CollectionIndex(表索引)、DataBlock(数据块)、PageAddress(页地址)、IndexKey(索引键)和IndexNode(索引节点)五个数据结构。
Services:包括了数据库对缓存、硬盘读写、索引查询、数据页的增删改查操作、回滚操作等功能的实现。
Utils:这个就是一些公用的工具类和异常定义。
后面的系列我将着重讲解以下几个部分:
1.LiteDB中关于页的概念,CollectionIndex、DataBlock和IndexNode这几个数据结构的作用。
2.Query模块如何实现linq功能,顺便试着解答博主数据之巅在博客中提出的关于分页的疑问。
3.LiteDB如何使用索引查询的,对比Mysql的索引方式,将LiteDB的跳表索引用可视化的方式展示出来。
这是我第一次用博客的形式解析源码,如果有纰漏,还望多指正。
标签:地址 表达 用户 ref 字段 cti 对比 更新 otn
原文地址:https://www.cnblogs.com/xiaozhangStudent/p/11012060.html