标签:执行 词法分析 开放 https ken 输出 技术 span 打开
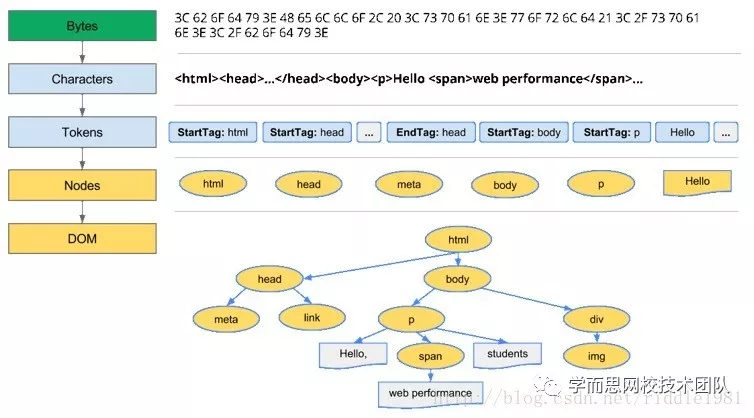
HTML解析是一个将字节转化为字符,字符解析为标记,标记生成节点,节点构建树的过程。
是词法分析过程,将输入内容解析成多个标记。HTML标记包括起始标记、结束标记、属性名称和属性值。标记生成器识别标记,传递给树构造器,然后接受下一个字符以识别下一个标记;如此反复直到输入的结束。
该算法的输出结果是 HTML 标记。该算法使用状态机来表示。每一个状态接收来自输入信息流的一个或多个字符,并根据这些字符更新下一个状态。当前的标记化状态和树结构状态会影响进入下一状态的决定
在树构建阶段,以 Document 为根节点的 DOM 树也会不断进行修改,向其中添加各种元素。
标记生成器发送的每个节点都会由树构建器进行处理。规范中定义了每个标记所对应的 DOM 元素,这些元素会在接收到相应的标记时创建。这些元素不仅会添加到 DOM 树中,还会添加到开放元素的堆栈中。此堆栈用于纠正嵌套错误和处理未关闭的标记。其算法也可以用状态机来描述。这些状态称为“插入模式”。
<html>
<body>hello</body>
</html>
标记化
初始状态是数据状态。
遇到字符 < 时,状态更改为“标记打开状态”。接收一个 a-z字符会创建“起始标记”,状态更改为“标记名称状态”。这个状态会一直保持到接收> 字符。在此期间接收的每个字符都会附加到新的标记名称上。在本例中,我们创建的标记是 html 标记。
遇到 > 标记时,会发送当前的标记,状态改回“数据状态”。 标记也会进行同样的处理。目前 html 和 body 标记均已发出。现在我们回到“数据状态”。接收到 Hello world 中的 H 字符时,将创建并发送字符标记,直到接收</body> 中的<。我们将为 Hello world 中的每个字符都发送一个字符标记。
接收</body> 中的<,现在我们回到“标记打开状态”。接收下一个输入字符 / 时,会创建 end tag token 并改为“标记名称状态”。我们会再次保持这个状态,直到接收 >。然后将发送新的标记,并回到“数据状态”。 输入也会进行同样的处理。
树构建
树构建阶段的输入是一个来自标记化阶段的标记序列
第一个模式是“initial mode”。
接收 HTML 标记后转为“before html”模式,并在这个模式下重新处理此标记。这样会创建一个 HTMLHtmlElement 元素,并将其附加到 Document 根对象上。
然后状态将改为“before head”。此时我们接收“head”标记。即使我们的示例中没有“head”标记,系统也会隐式创建一个 HTMLHeadElement,并将其添加到树中。
现在我们进入了“in head”模式,
然后转入“after head”模式。系统对 body 标记进行重新处理,创建并插入 HTMLBodyElement,
同时模式转变为“body”。现在,接收由“Hello world”字符串生成的一系列字符标记。接收第一个字符时会创建并插入“Text”节点,而其他字符也将附加到该节点
接收 body 结束标记会触发“after body"模式。现在我们将接收 HTML 结束标记,
然后进入“after after body”模式。接收到文件结束标记后,解析过程就此结束。解析结束后的操作
当HTML解析完成后,浏览器会将文档标注为交互状态,并开始解析那些处于“deferred”模式的脚本,也就是那些应在文档解析完成后才执行的脚本。然后,文档状态将设置为“完成”,一个“加载”事件将随之触发。
参考https://mp.weixin.qq.com/s/WtRxcyBbZQRcfFhfVJLBQA
标签:执行 词法分析 开放 https ken 输出 技术 span 打开
原文地址:https://www.cnblogs.com/yiyi17/p/11031305.html