标签:验证码 com image 扫描 net 图形 document ima 地址
OCR,即Optical Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程。对于图形验证码来说,它们都是一些不规则的字符,这些字符确实是由字符稍加扭曲变换得到的内容。
例如,对于验证码,我们可以使用OCR技术来将其转化为电子文本,然后爬虫将识别结果提交给服务器,便可以达到自动识别验证码的过程。
tesserocr需要安装tessoract依赖库,所以安装tesserocr前需要安装tessoract。
相关文件下载
在Windows下,首先需要下载tesseract,它为tesserocr提供了支持。http://digi.bib.uni-mannheim.de/tesseract
进入下载页面,可以看到有各种.exe文件的下载列表,这里可以选择下载3.0版本。图所示为3.05版本。
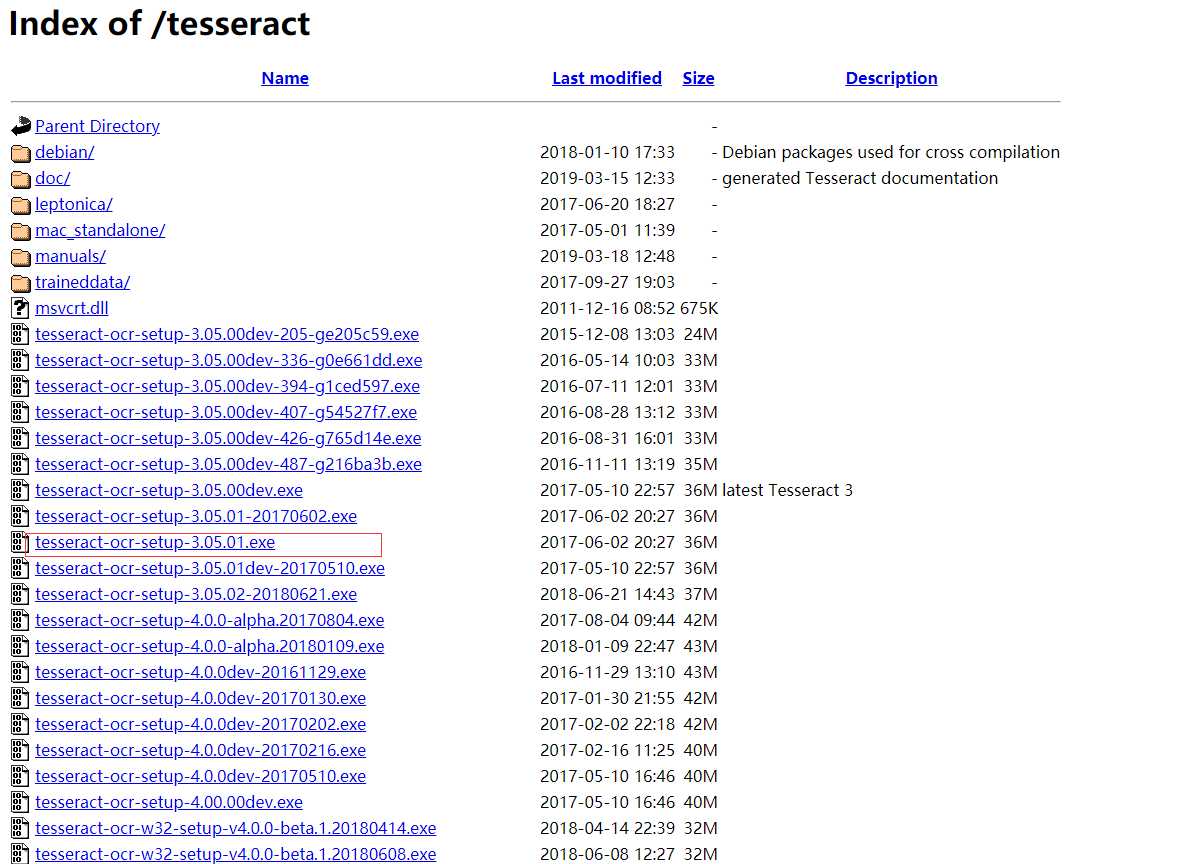
其中文件名中带有dev的为开发版本,不带dev的为稳定版本,可以选择下载不带dev的版本,例如可以选择下载tesseract-ocr-setup-3.05.01.exe。
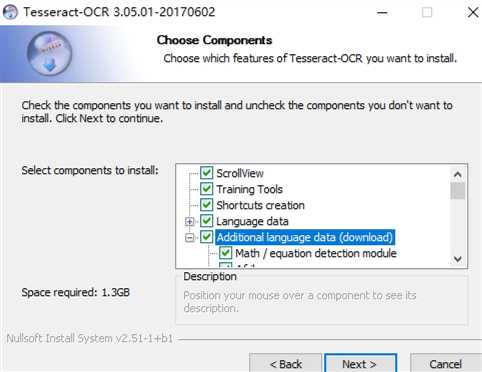
下载完成后双击,此时会出现如图所示的页面。全部勾选
windows不能用pip install tesserocr所以我这里是安装.whl文件,需要的道友请下载:
链接:https://pan.baidu.com/s/1i72kK1Wcc77B1BOvOC2pmg 提取码:pvuq
然后通过一下命令安装即可完成
pip install XXXX.whl(这是文件路径)
代码:
import tesserocr from PIL import Image img = Image.open(‘1.png‘) result = tesserocr.image_to_text(img) print(result)
验证码图片来源:http://my.cnki.net/elibregister/CheckCode.aspx
结束语:Windows不能通过pip install tesserocr 来安装tesserocr库,所以采用了.whl安装
标签:验证码 com image 扫描 net 图形 document ima 地址
原文地址:https://www.cnblogs.com/hardykay/p/11038890.html