标签:必须 继承 for 不同 大于 接下来 不可 原因 有关
集合一直都是项目中非常常见的,我是一个Android开发者,集合对于我来说,在项目中使用的次数非常之多,因为使用的多,熟能生巧,所以这里呢!就给那些初学者整理一下Java当中常用的集合吧!
因为此篇文章是给初学者看到,所以对于集合的认识,我们就不从内存的角度去分析了,等你Java学到一定的时候,再去学习一下集合的底层实现,这会让成为一名更加牛的Java程序员。
在整理之前呢,我们先聊一聊为什么集合会这么常用?,集合这个概念,我们初次接触是在高中的数学当中,高中的集合具有以下知识点:
1、集合的含义:某些指定的对象集在一起就成为一个集合,其中每一个对象叫元素。
2、集合的中元素的三个特性:
①.元素的确定性;②.元素的互异性;③.元素的无序性
说明:
(1)对于一个给定的集合,集合中的元素是确定的,任何一个对象或者是或者不是这个给定的集合的元素。
(2)任何一个给定的集合中,任何两个元素都是不同的对象,相同的对象归入一个集合时,仅算一个元素。
(3)集合中的元素是平等的,没有先后顺序,因此判定两个集合是否一样,仅需比较它们的元素是否一样,不需考查排列顺序是否一样。
高中的集合理解起来很简单,高中的集合里面放到是一个一个具体的对象,集合当中对象与对象之间是不一样的,而且集合中对象的元素是杂乱无章的,顺序没有什么规律可循,因为高中集合是无序性的。那么Java当中的集合是否又和高中的集合的概念是一致的呢?答案肯定不是啦,因为Java当中的集合是基于数据结构实现的,这些数据结构包括有:数组,链表,队列,栈,哈希表,树……等等,而高中的集合显然和这搭不上边,如果你不太懂这些数据结构,那么学起集合来可以说是非常吃力的,所以在学集合之前,请先小小的理解一些数据结构,因为你要想成为一名Java开发大神,数据结构你必须拿下!这里我贴一个数据结构自学的教学视频:
链接:http://pan.baidu.com/s/1jI1azD8 密码:4725
我也是通过里面郝斌的数据结构视频才把数据结构掌握的,尽管我大学数据结构课打酱油,但是看这个视频,只要认真,掌握真是小case!
闲话我们也唠完了,下面进入正题,总结Java当中常用的集合:
首先,提出一个接口Collection,这个接口很多集合都有实现它,而Java常用的集合包括List,Set,以及Map。而List,Set和Map都是接口,其中List接口,Set接口是继承了Collection接口,而Map接口是没有继承Collection接口,原因很简单,因为List和Set集合一般放的单个对象,Map放的是键值对,也就是成对的两个对象,键值对就是可以根据一个键值获得对应的一个值,因为Collection不具备这种特点,所以Map并没有继承Collection。值得一提的是Java的集合持有的并不是对象本身,而是一个指向对象的引用,集合当中放的全部都是引用,如果你现在还不理解这句话,那就暂时不去理解,等你学到一定阶段,再回头来理解理解也是可以的,但是请不要把过多的疑问留到以后,要想成为一名牛的Java程序员,当天的疑问当天来解决,只要你有这个习惯,不管是学习什么,最后你一定会成为很牛的人,写着写着又在乱扯,那么继续回到正题,根据前面对集合的几个接口的描述,所以有如下继承图:
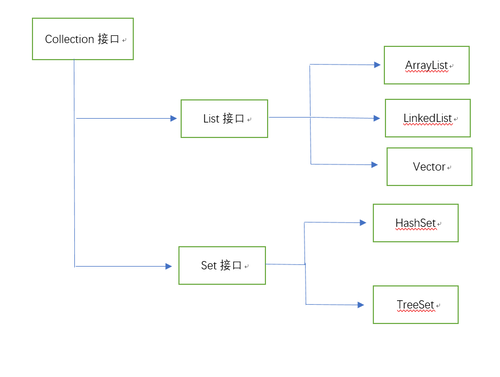
有序可重复:顺序是按照放入的顺序排列的,可重复指的是可以放入一样的元素
实现了接口该接口的集合:ArrayList,LinkedList,Vector
[1]ArrayList
底层:使用数组实现
特点:查找效率高,随机访问效率高,增删效率低,非线程安全的
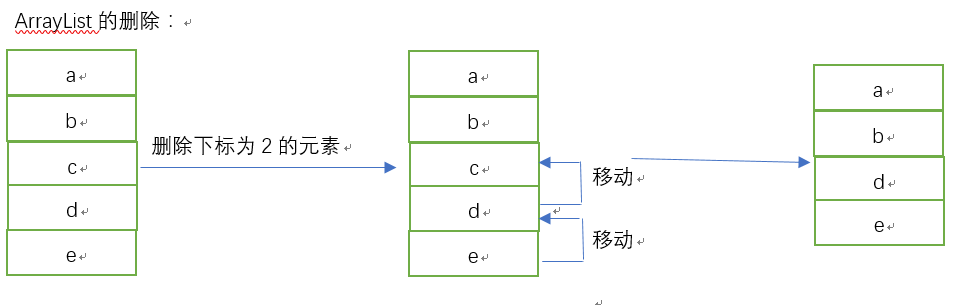
说明:由于ArrayList底层是有数组实现的,那么也就意味着在内存当中是一个有一个连续的内存空间构成,学过数据结构的肯定知道,因为是这种连续,会让访问效率变得非常之高,但也会带来一个问题,当你往中间插入一个元素,那么插入的位置之后的元素,都要往后移动,如果后面的元素有很多,这显然会让效率大大降低,那么删除呢?也同样面临同样的效率问题,因为当你删除中间的某个元素,位于这个删除的元素之后的位置的所有元素都要往前移动,查询呢?因为随机访问效率很高,所以查询的效率非常可观。看看下面的ArrayList的添加和删除: 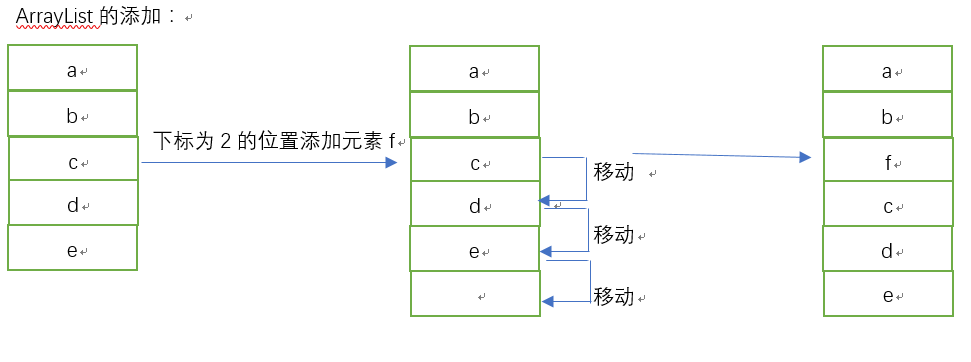
接下来就是代码部分了,数据结构的操作从四个方面着手:增删改查,以下代码只是基本的操作,实现List接口的集合具备有很多操作,我只是列举了一些基本操作,要想详细了解,请查看API,我这里给你Java API1.6中文版链接:http://pan.baidu.com/s/1eSIJ9zc 密码:wjx1
//生成arrayList实例对象
ArrayList<String> arrayList = new ArrayList<String>();
//ArrayList的添加:
arrayList.add("a"); //在末尾添加元素
arrayList.add("b");
arrayList.add("c");
arrayList.add("d");
arrayList.add("e");
arrayList.add(2,"f");//在指定位置插入元素
//ArrayList的删除
arrayList.remove(2);//移除下标为2的元素
//ArrayList的修改
arrayList.set(0,"a");//把下标为1的元素修改为元素"a"
//ArrayList的查询,这里需要遍历ArrayList
//普通for语句遍历
for(int i=0;i<arrayList.size();i++){
if(arrayList.get(i).equals("a")){
System.out.println("该集合当中存在a元素,并且位置在第"+(i+1));
}
}
//foreach语句遍历
for(String str:arrayList){
if(str.equals("a")){
System.out.println("该集合当中存在a元素");//输出其位置就要另外添加变量了
}
}
//迭代器方式:
Iterator<String> intertor = arrayList.iterator();
while(intertor.hasNext()){
if(intertor.next().equals("a")){
System.out.println("该集合当中存在a元素");
}
}
[2]LinkedList
底层:使用双向循环链表实现
特点:查找效率低,随机访问效率低,增删效率高,非线程安全的
说明:由于LinkedList底层是由双向循环链表实现的,那么这就意味着,内存当中,它存储的每一个元素的内存空间不是连续的,这给查询和访问,带来了不便,但是也存在着极大的好处,就是增删效率远远高于ArrayList,因为学过数据结构的都知道,链表的增删只需要修改指针指向就可以了,不会像数组那样每次删除,都需要元素配合进行移动,LinkedList并不需要每个元素进行移动,光说你肯定是不会理解的,那么看看下面的LinkedList的添加和删除: 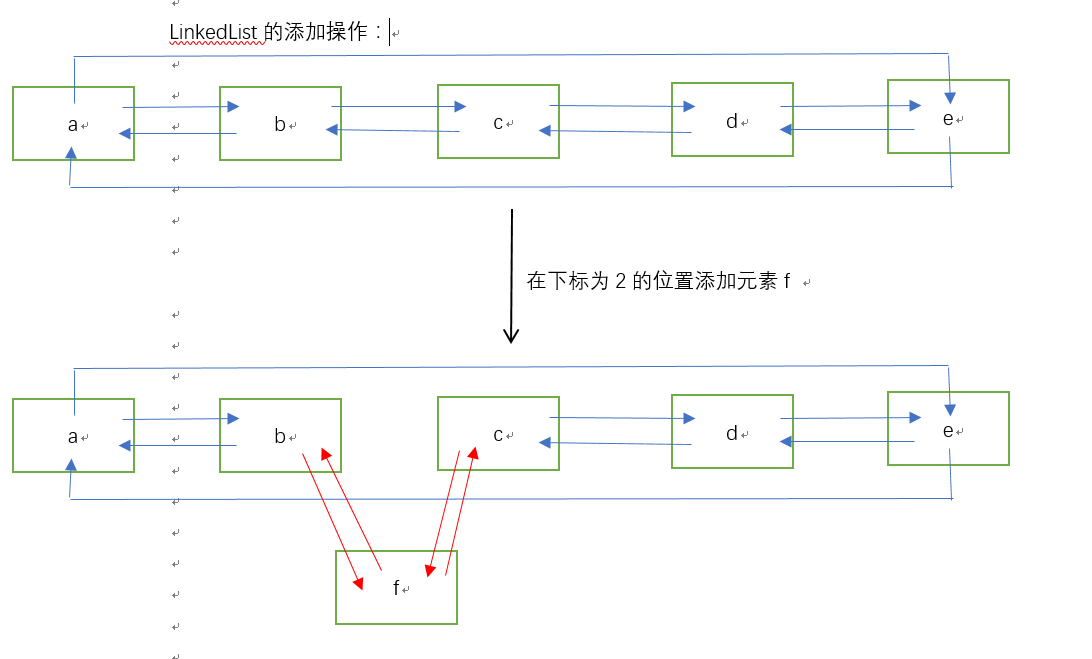
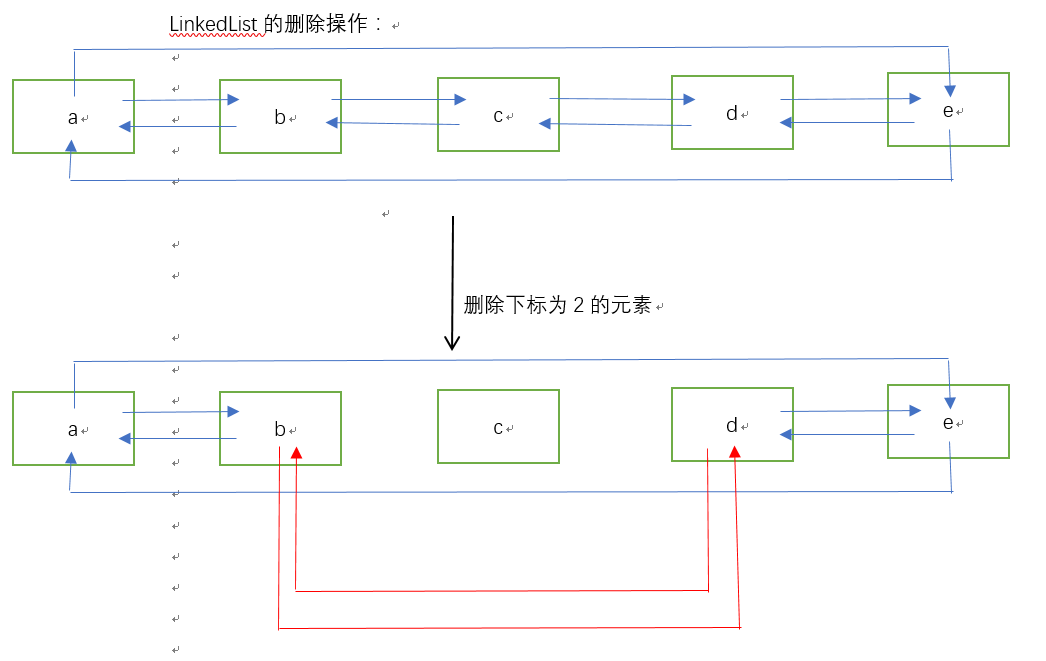
代码部分我就不写了,因为在代码上LinkedList的增删改查与ArrayList是一样的。
[3]Vector
说明:这个集合和ArrayList相似,但是它具有一些集合都不具有的特点,最大的不同之处,它跟枚举有关系。还要很重要的一点,Vector是线程安全,因为是线程安全的,所以效率上比ArrayList要低。这里就不具体介绍Vector了,因为用到的并不多,但也有可能会使用到。详细了解看Java API。
无序不可重复:无序指的是Set集合的排列顺序并不会按照你放入元素的顺序来排列,而是通过某些标准进行排列,不可重复指的是Set集合是不允许放入相同的元素,也就是相同的对象,对象相同是怎么判断的呢?Set集合是通过两个方法来判断其元素是否一样,这两个方法就是hashCode()方法和equlas()方法,首先,hashCode()方法返回的是一个哈希值,这个哈希值是由对象在内存中的地址所形成的,如果两个对象的哈希值不一样,那么这两个对象肯定是不相同的,如果哈希值一样,那么这还不能肯定这两个对象是否一样,还需要通过equlas()方法比较一下两个对象是否一样,equals()返回true才能说明这两个对象是相同的,所以当你想把你自定义的类对象放入此集合,最好重写一下hashCode()方法和equals()方法来保证Set集合”无序不可重复”的特点。判断两个对象是否一样是通过以下图片当中的流程,图片会让你更加理解。 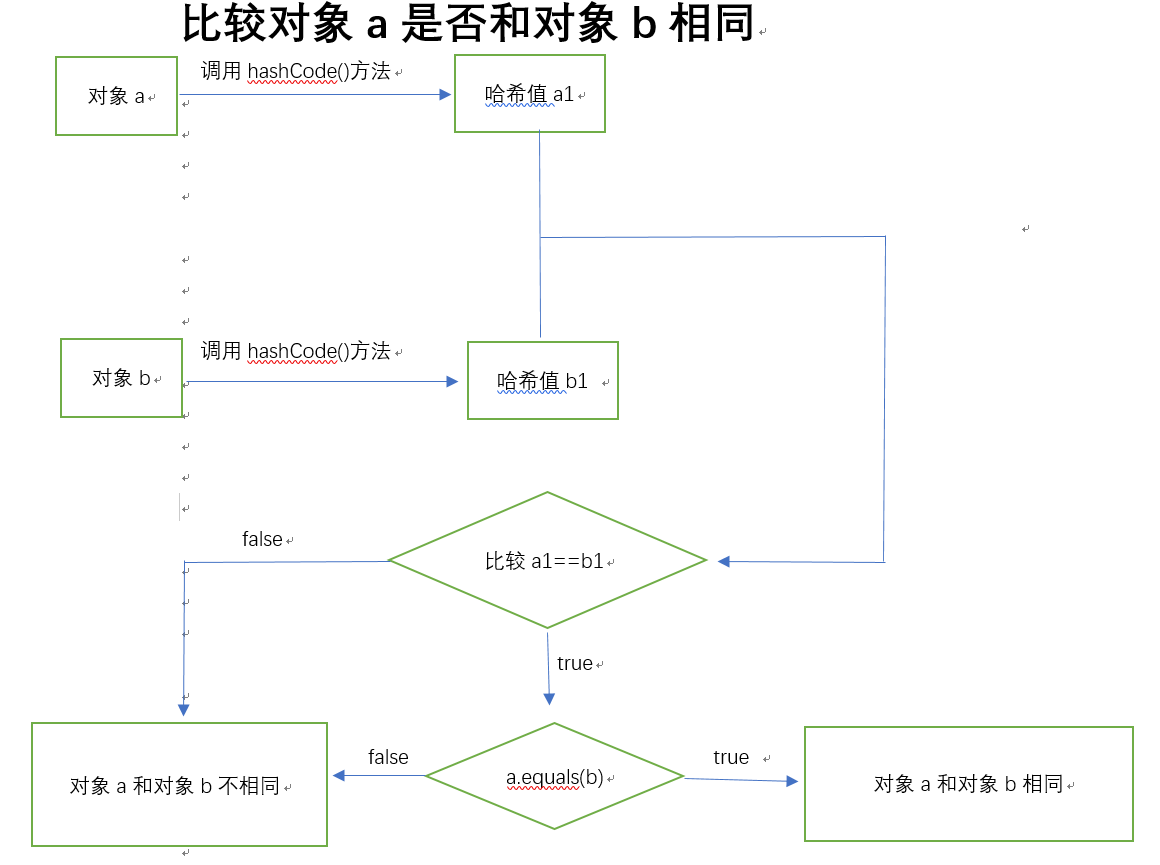
[1]HashSet
底层:使用哈希表实现
特点:非线程安全的,放入对象后,其对象的位置与对象本身的hashCode()方法返回的哈希值有关。判断重不重复,是通过对象本身的hashCode()方法和equals()方法决定的,所以当你想把你自定义的类对象放入此集合,最好重写一下hashCode()方法和equals()方法。
接下来,就是演示如何使用这个HashSet集合了,还是从4个方面着手:增删改查
//HashSet的操作
//生成HashSet的实例对象
HashSet<String> hashSet = new HashSet<String>();
//HashSet的增加
hashSet.add("1");
hashSet.add("2");
hashSet.add("3");
hashSet.add("4");
hashSet.add("5");
//HashSet的删除
hashSet.remove("2");
//HashSet的修改
//因为HashSet的元素不存在通过下标去访问,所以修改操作是没有的
//HashSet的查询
//foreach语句方式
for(String str:hashSet){
if(str.equals("a")){
System.out.println("该集合中存在a元素");
}
}
//迭代器方式:
Iterator<String> intertor1 = hashSet.iterator();
while(intertor1.hasNext()){
if(intertor1.next().equals("a")){
System.out.println("该集合当中存在a元素");
}
}
[2]TreeSet
底层:使用树实现
特点:非线程安全的,排序规则是默认使用元素的自然排序,或者根据实现Comparable接口(比较器)的compareTo()方法进行排序。判断重不重复也是通过compareTo()方法来完成的,当compareTo()方法返回值为0时,两个对象是相同的。所以存入TreeSet集合的对象对应的类一定要实现Comparable接口。
代码我就不写了,因为TreeSet集合的增删改查操作基本与HashSet一样,但是必须详细说明一下,如果你想把自己定义的类放入TreeSet集合,那么那个自定义类必须支持自然排序,说得明白点,就是一定要实现Comparable接口(比较器接口)。下面写个例子,比如:需要在TreeSet集合当中放入10个Student对象,实现通过年龄进行排序,然后按照年龄的顺序输出者10个Student对象的信息。分析一下,其实这个例子就是让你封装的自定义的类,在运用于TreeSet集合的时候能够保证其唯一性和某个排序规则。所以你在封装你的自定义类的时候一定考虑两点:
1.唯一性的判断:假设有两个Student类对象a和Student类对象b,你得保证把a和b对象放入TreeSet集合的时候,a和b是不同的对象,那么凭借什么来判断呢?假设Student有name,age属性,判断两个Student对象一样,那么就是判断name属性和age属性是否一样,换句话说,当两个对象一样的时候,这两个对象的所有属性都是相同的。这个判断需要你的自定义类实现Comparable接口(比较器接口),然后重写compareTo()方法,当这个方法返回0的时候,意味着被比较的两个对象是相同的。
2.排序规则:TreeSet的排序规则也是需要自定义类实现Comparable接口(比较器接口),然后重写compareTo()方法,当这个方法返回正值的时候,意味着前面的对象大于后面的对象,否则,意味着前面的对象小于后面的对象。
下面是详细的代码:
import java.util.TreeSet;
public class StudentTreeSetDemo {
public static void main(String[] args) {
TreeSet<Student> treeSet = new TreeSet<Student>();
treeSet.add(new Student("a", 1));
treeSet.add(new Student("b", 2));
treeSet.add(new Student("c", 3));
treeSet.add(new Student("d", 5));
treeSet.add(new Student("e", 3));
treeSet.add(new Student("f", 7));
//放入相同的
treeSet.add(new Student("d", 5));
treeSet.add(new Student("e", 3));
treeSet.add(new Student("b", 2));
for(Student student:treeSet){
student.allMessage();
}
}
}
class Student implements Comparable<Student>{
public String name;
public int age;
public Student(String name,int age ) {
this.name = name;
this.age = age;
}
public void allMessage(){
System.out.println("学生名字:"+name+",学生年龄:"+age);
}
@Override
public int compareTo(Student o) {
//排序规则:按照年龄进行排序
return age - o.age != 0?age - o.age:(name.equals(o.name)?0:1);
}
}
还要一个需要了解的Set集合,LinkedHashSet集合:
LinkedHashSet集合跟HashSet一样是根据放入的对象的hashCode()方法返回的哈希值来决定元素的存储位置,但是它同时使用链表维护元素的次序。为什么这么做呢?因为这样做可以让放入的元素像是以插入顺序保存的,换句话说,当遍历LinkedHashSet集合的时候,LinkedHashSet将会以元素的放入顺序来依次访问的。所以LinkedHashSet在遍历或者迭代访问全部元素时,性能方面LinkedHashSet比HashSet好,但是插入时性能就比HashSet差些。
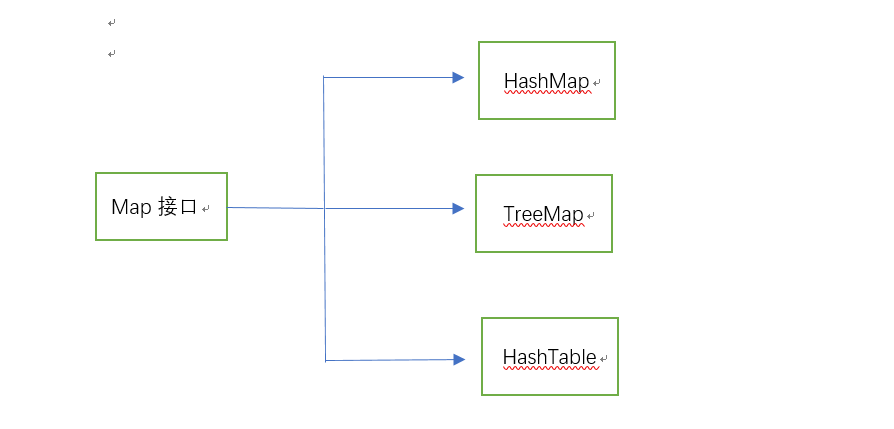
Map集合存储的元素是成对出现的,存放的是键值对,键值是唯一的,但是值可以重复,可以理解为超市里面的存储箱,一个钥匙只能打开对应的存储箱,而存储箱里面的东西是可以一样的,这里的键就是钥匙,这里的值就是就是钥匙对应的存储箱里面的东西。键是唯一的,值可以不唯一。Map的键是一个Set集合,只有这样才可以保证键的唯一性,因为Set集合从不放入重复的元素,这就保证了键的唯一性。
[1]HashMap
底层:数组和链表的结合体(在数据结构称“链表散列“)
特点:非线程安全,当你往HashMap中放入键值对的时候,如果你放入的键是自定义的类,那么其该键值对的位置与键对象本身的hashCode()方法返回的哈希值有关。判断重不重复,是通过键对象本身的hashCode()方法和equals()方法决定的,所以当你想把你自定义的类对象通过键来放入HashMap集合,最好重写一下这个自定义类的hashCode()方法和equals()方法。其实Map主要的特点都是通过键来完成的,所以你只要封装好你的自定义类,就可以保证键值的唯一性。
下面来看看代码,HashMap的增删改查
//HashMap的操作
HashMap<String,Integer> hashMap = new HashMap<String,Integer>();
//HashMap的添加
hashMap.put("1", 1);
hashMap.put("2", 2);
hashMap.put("3", 3);
hashMap.put("4", 4);
//HashMap的删除
hashMap.remove("2");//移除键值为"2"的元素
//HashMap的修改
hashMap.put("1", 11);//将键值为"1"的元素的键值覆盖为"11",修改其实就覆盖
//HashMap的查询,这里需要遍历HashMap
//1.通过遍历键的Set集合来遍历整个Map集合
System.out.println("foreach遍历");
for(String str:hashMap.keySet()){
System.out.println(str+":"+hashMap.get(str));
}
System.out.println("迭代器遍历");
Iterator<String> intertor = hashMap.keySet().iterator();
while(intertor.hasNext()){
String key = intertor.next();
System.out.println(key+":"+hashMap.get(key));
}
//2.使用Map集合的关系遍历
System.out.println("Map关系遍历");
for(Map.Entry<String, Integer> entry:hashMap.entrySet()){
System.out.println(entry.getKey()+":"+entry.getValue());
}
[2]TreeMap
底层:使用树实现
特点:非线程安全,键是TreeSet集合,排序规则是默认使用元素的自然排序,或者根据实现的Comparable接口(比较器)的compareTo()方法进行排序。判断重不重复也是通过compareTo()方法来完成的,当compareTo()方法返回值为0时,两个对象是相同的。所以保证唯一性,只需要让键对应的类实现Comparable接口(比较器),并且实现compareTo()方法。所以存入TreeMap集合作为键的对象对应的类一定要实现Comparable接口。 而跟TreeSet一样,放入后的排序,以及键的唯一性都是通过compareTo()方法完成的。所以如何让自定义的类通过键值放入TreeMap集合,并且保证唯一性,和按照一定规则排序,只需要这个自定义类实现Comparable接口(比较器),实现compareTo()方法即可。例子我就不举了,其实和TreeSet的那个例子基本一样。
[3]HashTable
底层:使用哈希表实现的
特点:线程安全,基本特点和用法和HashMap相似,性能上稍微差于HashMap,因为HashTable是线程安全的。这个集合我就不详细说明了,基本和HashMap类似,唯一不同的是它是线程安全的。
还有一个集合需要了解一下,LinkedHashMap,这个我想不用我说你也应该知道了,其实和前面说的LinkedHashSet差不多。可以结合前面的LinkedHashSet来分析一下LinkedHashMap,我想这对于你来说不难。
标签:必须 继承 for 不同 大于 接下来 不可 原因 有关
原文地址:https://www.cnblogs.com/dhshappycodinglife/p/11047766.html