标签:存放位置 体系 存储结构 创建 用户名 内存 databases cache 执行
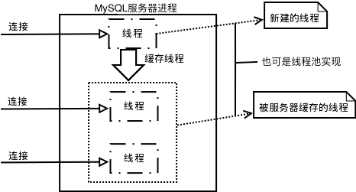
当MySQL启动(MySQL服务器就是一个进程),等待客户端连接,每一个客户端连接请求,服务器都会新建一个线程处理(如果是线程池的话,则是分配一个空的线程),每个线程独立,拥有各自的内存处理空间
show VARIABLES like ‘%max_connections%‘
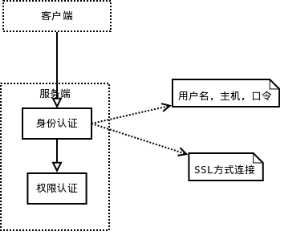
连接到服务器,服务器需要对其进行验证,也就是用户名、IP、密码验证,一旦连接成功,还要验证是否具有执行某个特定查询的权限(例如,是否允许客户端对某个数据库某个表的某个操作)
这一层主要功能有:SQL语句的解析、优化,缓存的查询,MySQL内置函数的实现,跨存储引擎功能(所谓跨存储引擎就是说每个引擎都需提供的功能(引擎需对外提供接口)),例如:存储过程、触发器、视图等。
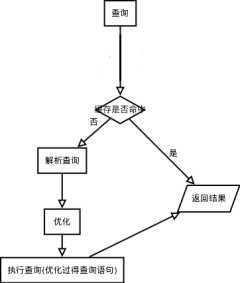
1.如果是查询语句(select语句),首先会查询缓存是否已有相应结果,有则返回结果,无则进行下一步(如果不是查询语句,同样调到下一步)
2.解析查询,创建一个内部数据结构(解析树),这个解析树主要用来SQL语句的语义与语法解析;
3.优化:优化SQL语句,例如重写查询,决定表的读取顺序,以及选择需要的索引等。这一阶段用户是可以查询的,查询服务器优化器是如何进行优化的,便于用户重构查询和修改相关配置,达到最优化。这一阶段还涉及到存储引擎,优化器会询问存储引擎,比如某个操作的开销信息、是否对特定索引有查询优化等。
show variables like ‘%query_cache_type%‘ -- 默认不开启
show variables like ‘%query_cache_size%‘ --默认值1M
SET GLOBAL query_cache_type = 1; --会报错
query_cache_type只能配置在my.cnf文件中,这大大限制了qc的作用
在生产环境建议不开启,除非经常有sql完全一模一样的查询
QC严格要求2次SQL请求要完全一样,包括SQL语句,连接的数据库、协议版本、字符集等因素都会影响

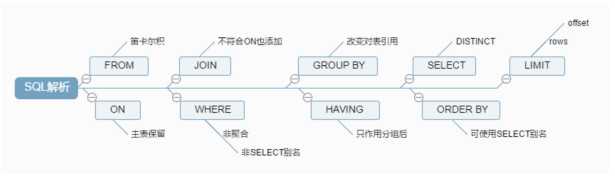



通过上面的sql大概就能看出一个sql并不一定会去查询物理数据,sql解析器会通过优化器来优化程序员写的sql
explain
select * from account t where t.id in (select t2.id from account t2)
show warnings;

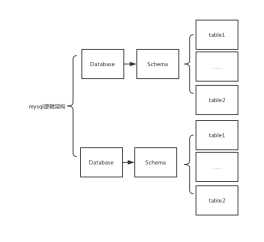
在mysql中其实还有个schema的概念,这概念没什么太多作用,只是为了兼容其他数据库,所以也提出了这个。
在mysql中 database 和schema是等价的
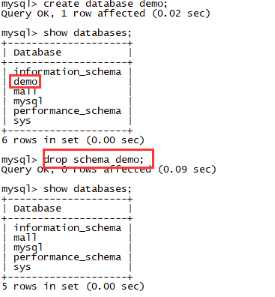
create database demo;
show databases;
drop schema demo;
show databases;
mysql安装的时候都要指定datadir,其查看方式为:
show VARIABLES like ‘datadir‘,其规定所有建立的数据库存放位置
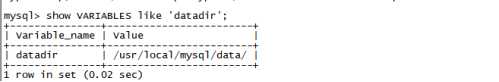
创建了一个数据库后,会在上面的datadir目录新建一个子文件夹
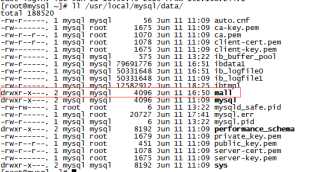
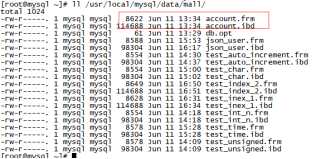
用户建立的表都会在上面的目录中,它和具体的存储引擎相关,但有个共同的就是都有个frm文件,它存放的是表的数据格式。
mysqlfrm --diagnostic /usr/local/mysql/data/mall/account.frm
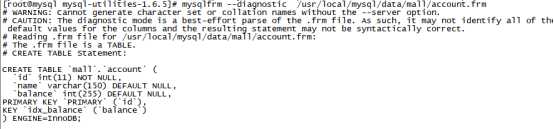
tar -zxvf mysql-utilities-1.6.5.tar.gz
cd mysql-utilities-1.6.5
python ./setup.py build
python ./setup.py install
标签:存放位置 体系 存储结构 创建 用户名 内存 databases cache 执行
原文地址:https://www.cnblogs.com/Soy-technology/p/11050444.html