标签:ike 页面 复杂 png 分布式部署 Go语言 使用 不可 一个
最近主攻go的学习,在学完了基础语法,看完了无闻翻译的《The way to go》和ccmouse大神的慕课网课程后,感觉基础差不多了,继续深入挖掘ccmouse大神的爬虫项目,收获颇丰,感觉还是有一定的难度的,会继续啃下去,学习之余感觉自己实在是井底之蛙,无数光阴尽数浪费,无所建树,思维停留在最原始的层面,无法向前迈进;庆幸现在有所觉悟,人生匆匆几十载,时间是最宝贵的,不论哪个领域,选择一个自己认定的,低下头向前冲刺,丰富自己的头脑,提升自己的认知。好像扯得有点远了,下面是项目的总结。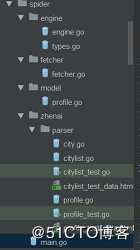 engine是总的控制文件,把请求和正则解析push到总的slice []request中,fetcher主要是通过http库去获取页面body信息,model是要保存的人的信息struct
engine是总的控制文件,把请求和正则解析push到总的slice []request中,fetcher主要是通过http库去获取页面body信息,model是要保存的人的信息struct
注意这里是两个chan), 在run方法中定义一个out chan ParseResult,和并发版相比而言,队列版多了workerChan 这个chan,主要用来实现队列的调度,TODO:细节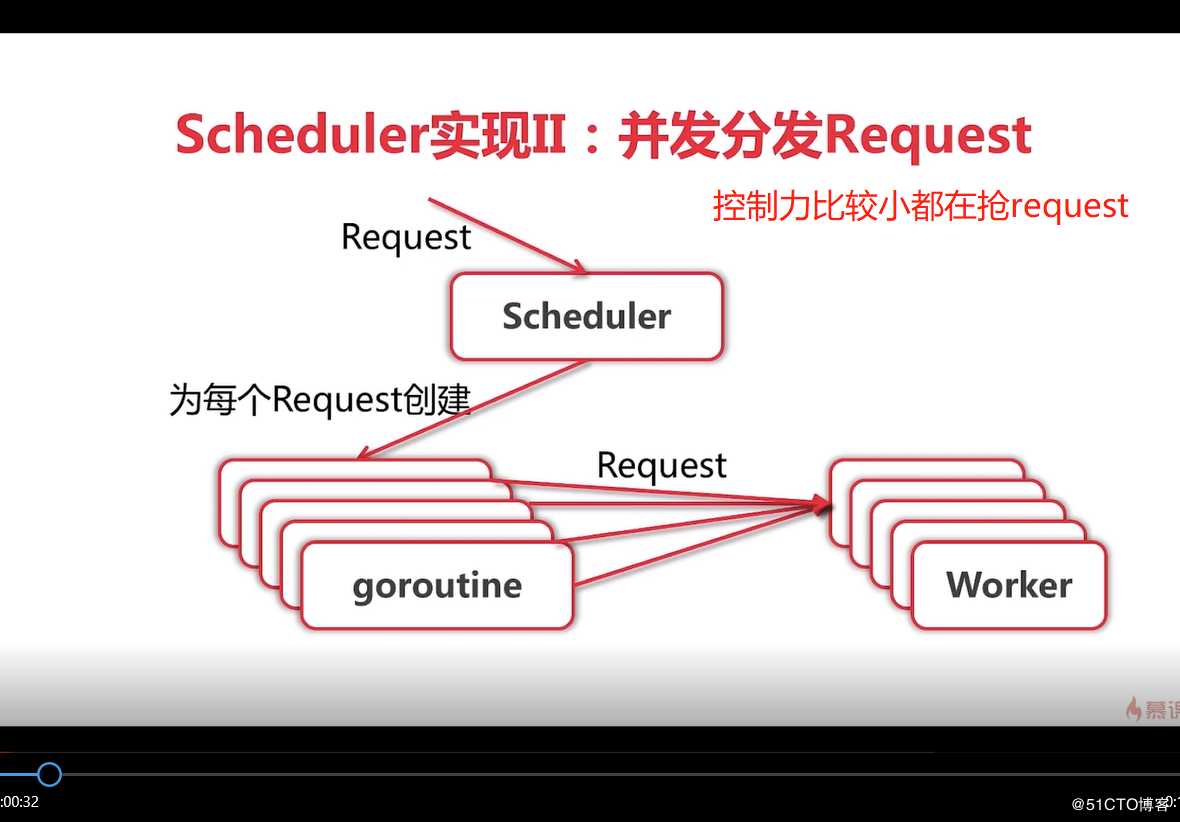
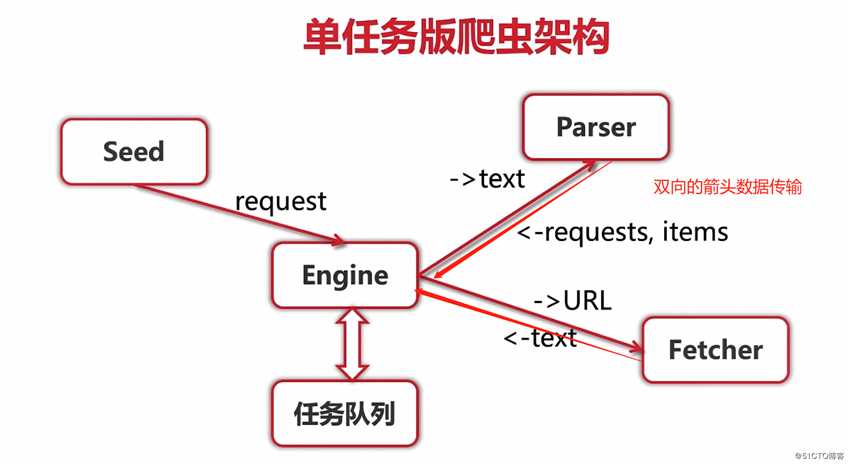
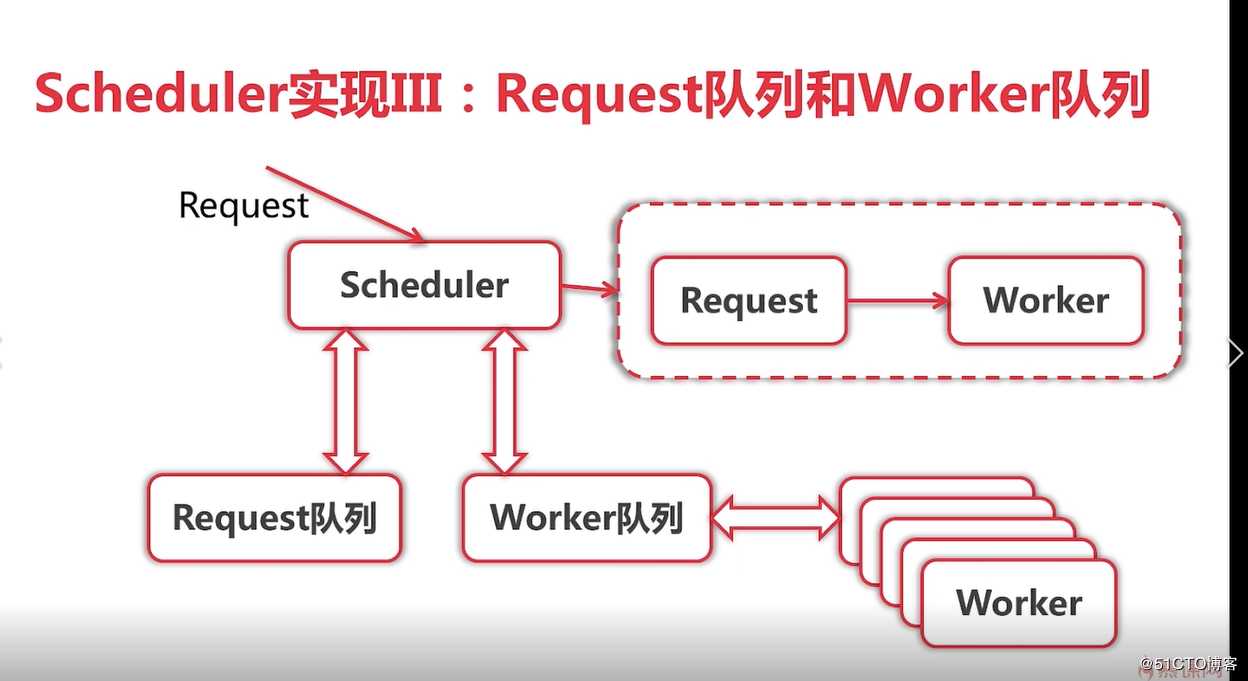
标签:ike 页面 复杂 png 分布式部署 Go语言 使用 不可 一个
原文地址:https://blog.51cto.com/jinjiang2009/2410892