标签:val 聚合 img 行转列 search order by char 表示 column
1、行转列(PIVOT函数)
语法:
TABLE_SOURCE
PIVOT(聚合函数(value_column) FOR pivot_column IN( < column_list > ))
效果图:
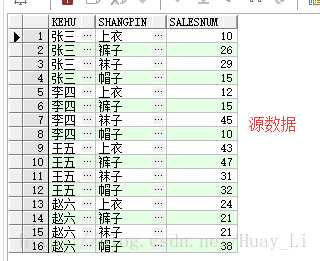
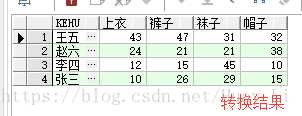
--行转列 select * from SalesList pivot( max(salesNum) for shangPin in ( --shangPin 即要转成列的字段 ‘上衣‘ as 上衣, --max(salesNum) 此处必须为聚合函数, ‘裤子‘ as 裤子, --in () 对要转成列的每一个值指定一个列名 ‘袜子‘ as 袜子, ‘帽子‘ as 帽子 ) ) where 1 = 1;
注意 pivot里面必须使用聚合函数。
2、列转行(UNPIVOT函数)
语法:
TABLE_SOURCE
UNPIVOT(value_column FOR pivot_column IN( < column_list > ))
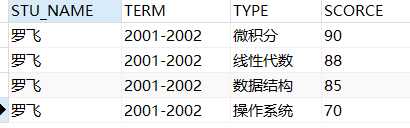
SELECT * from (SELECT ‘罗飞‘ STU_NAME, ‘2001-2002‘ TERM, ‘90‘ 微积分, ‘88‘ 线性代数, ‘85‘ 数据结构, ‘70‘ 操作系统 FROM DUAL) unpivot (scorce for type in(微积分,线性代数,数据结构,操作系统))
结果:
3、使用 listagg() WITHIN GROUP () 将多行合并成一行
SELECT T .DEPTNO, listagg (T .ENAME, ‘,‘) WITHIN GROUP (ORDER BY T .ENAME) names FROM SCOTT.EMP T WHERE T .DEPTNO = ‘20‘ GROUP BY T .DEPTNO
4、字符串替换(translate函数)
语法:TRANSLATE(char, from, to)
用法:返回将出现在from中的每个字符替换为to中的相应字符以后的字符串。
若from比to字符串长,那么在from中比to中多出的字符将会被删除。
三个参数中有一个是空,返回值也将是空值。
select translate(‘abcdefga‘,‘abc‘,‘wo‘) 返回值 from dual;
返回值:
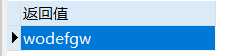
分析:
该语句要将‘abcdefga‘中的‘abc‘转换为‘wo‘, 由于‘abc‘中‘a‘对应‘wo‘中的‘w‘, 故将‘abcdefga‘中的‘a‘全部转换成‘w‘; 而‘abc‘中‘b‘对应‘wo‘中的‘o‘, 故将‘abcdefga‘中的‘b‘全部转换成‘o‘; ‘abc‘中的‘c‘在‘wo‘中没有与之对应的字符, 故将‘abcdefga‘中的‘c‘全部删除; 简单说来,就是将from中的字符转换为to中与之位置对应的字符, 若to中找不到与之对应的字符,返回值中的该字符将会被删除。 在实际的业务中,可以用来删除一些异常数据, 比如表a中的一个字段t_no表示电话号码, 而电话号码本身应该是一个由数字组成的字符串, 为了删除那些含有非数字的异常数据,
就用到了translate函数:
SQL> delete from a,
where length(translate(trim(a.t_no),
‘0123456789‘ || a.t_no,
‘0123456789‘)) <> length(trim(a.t_no));
补充:replace也有类似的功能
语法:REPLACE(char, search_string,replacement_string) 用法:将char中的字符串search_string全部转换为字符串replacement_string。
select REPLACE(‘fgsgswsgs‘, ‘fk‘ ,‘j‘) 返回值 from dual;
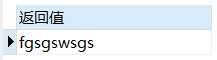
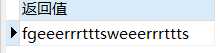
select REPLACE(‘fgsgswsgs‘, ‘sg‘ ,‘eeerrrttt‘) 返回值 from dual;
分析
分析:第一个例子中由于‘fgsgswsgs‘中没有与‘fk‘匹配的字符串, 故返回值仍然是‘fgsgswsgs‘; 第二个例子中将‘fgsgswsgs‘中的字符串‘sg‘全部转换为‘eeerrrttt‘。 总结:综上所述,replace与translate都是替代函数, 只不过replace针对的是字符串(完全匹配替换),而translate针对的是单个字符(位置匹配替换)。
标签:val 聚合 img 行转列 search order by char 表示 column
原文地址:https://www.cnblogs.com/cq-yangzhou/p/11063473.html