标签:面向 bsp 写入 说明 打开 实现 mat 不必要 lin
严格讲,文件不属于数据类型。
(1)基本语法:file=open(‘文件名’,mode)
参数mode模式可选参数,分为:r读 w写 a追加
r/w/a后面可接第二个参数,b标书二进制,f=open(‘data.bin‘,‘rb‘)
(2)完整语法格式为:
open(file, mode=‘r‘, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
mode 参数有:
myfile = open(‘hello.txt‘,‘w‘) #创建txt文件
myfile.write("人生苦短,快用Python")
myfile.close() #使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
例子:f=open(‘data.bin‘,‘rb‘) #读取二进制文件。
(1)read默认读取所有内容,且读取完再读取没有信息,此时指针指在文件末尾
(2)一行一行读取
f = open (‘hello.txt‘)
f.readline()
(3)读取所有行并打印
f = open (‘hello.txt‘)
f.readlines()
注意:
文件对象提供了三个“读”方法: .read()、.readline() 和 .readlines()。每种方法可以接受一个变量以限制每次读取的数据量,但它们通常不使用变量。
.read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中。然而 .read() 生成文件内容最直接的字符串表示,但对于连续的面向行的处理,它却是不必要的,并且如果文件大于可用内存,则不可能实现这种处理。
.readline() 和 .readlines() 非常相似。它们都在类似于以下的结构中使用:
readlines() 示例:
fh = open( ‘c:\\test.txt‘)
for line in fh.readlines():
print line.readline() 和 .readlines()之间的差异是后者一次读取整个文件,象.read()一样。.readlines()自动将文件内容分析成一个行的列表,该列表可以由 Python 的 for... in ... 结构进行处理。另一方面,.readline()每次只读取一行,通常比.readlines()慢得多。仅当没有足够内存可以一次读取整个文件时,才应该使用.readline()。
写:
writeline()是输出后换行,下次写会在下一行写。
write()是输出后光标在行末,不会换行,下次写会接着这行写
Python很多数据有类型,当这些类型数据放入文本中,会导致类型丢失。
例子:下面例子为①定义了三个变量1,2,3和一个list为[1,2,3]
②把他们分别存入文件,
③把他们分别读取出来
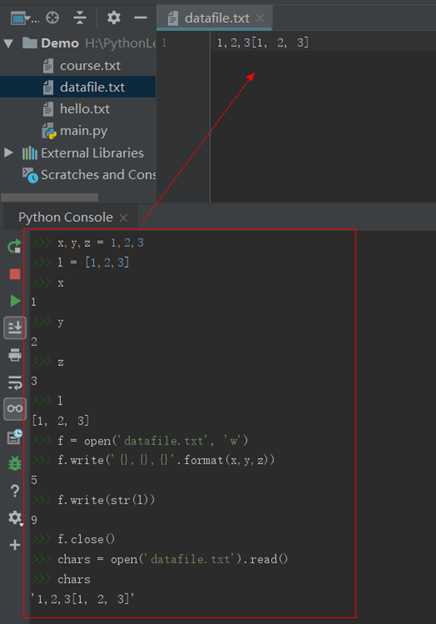
注意: 1,2,3存入使用了format方法,list存入使用了str转换为字符串再存入。存入文件后,数据类型都变成了字符型,如果想还原还需要分割逐个还原。
所以用文件存储有数据类型内容,比较麻烦。
解决方法:①序列化概念:即可以把原本在内存中的各种类型可以序列号为一种结构。需要时候还可以还原回来。
②Python准备了一个模块pickle(音译皮克乐):可以直接存储和读取本地的python类型对象
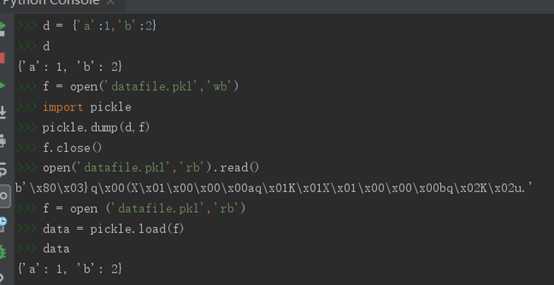
例:①定义一个字典d,
②定义一个二进制文件datafile.pkl(二进制文件后缀可以自己随意取)
③导入pickle
④用dump方法把d写入f中
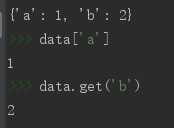
⑤用load方法把f数据读取到data中,查看仍然是原来类型数据。可以用字典方法操作data,说明类型没有发生变化
如果操作一个文件,又担心忘了关闭,可以如下操作:
用with方法把文件打开存入一个临时变量f中,
当程序运行完with范围后会自动脱离该文件即关闭文件
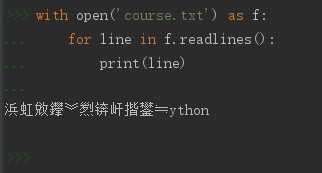
以后打开文件可以习惯用with打开文件
标签:面向 bsp 写入 说明 打开 实现 mat 不必要 lin
原文地址:https://www.cnblogs.com/yijiexi/p/11066912.html