标签:spider 实现 pid 数据页面 大致 网站 http 访问 git
通过前面的文章已经学习了基本的爬虫知识,通过这个例子进行一下练习,毕竟前面文章的知识点只是一个
一个单独的散知识点,需要通过实际的例子进行融合
其实爬虫最重要的是前面的分析网站,只有对要爬取的数据页面分析清楚,才能更方便后面爬取数据
目标站和目标数据
目标地址:http://www.hshfy.sh.cn/shfy/gweb/ktgg_search.jsp
目标数据:目标地址页面的中间的案开庭公告数据
对数据页面分析
从打开页面后可以看到默认的数据是一个月的数据,即当天到下个月该天的
通过翻页可以返现这个时候页面的url地址是不变的,所以这里我们大致就可以判断出,中间表格的数据是通过js动态加载的,我们可以通过分析抓包,找到真实的请求地址
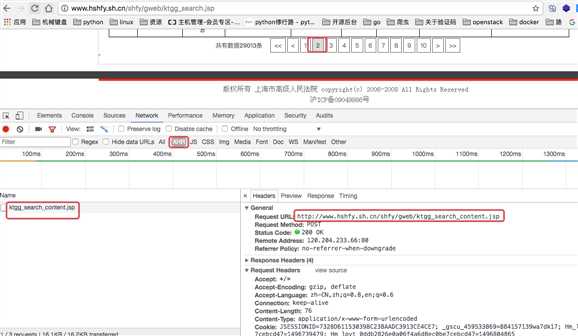
通过上图我们可以发现其实帧数的数据来源是http://www.hshfy.sh.cn/shfy/gweb/ktgg_search_content.jsp 这个地址。
当直接访问这个地址可以看到如下数据:
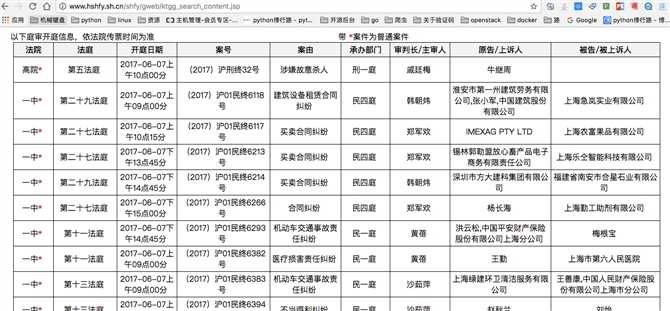
也正好验证了我们前面所说的,中间表格的数据是通过js动态加载的,所以我们剩下的就是对这个地址进行分析
分析真实地址
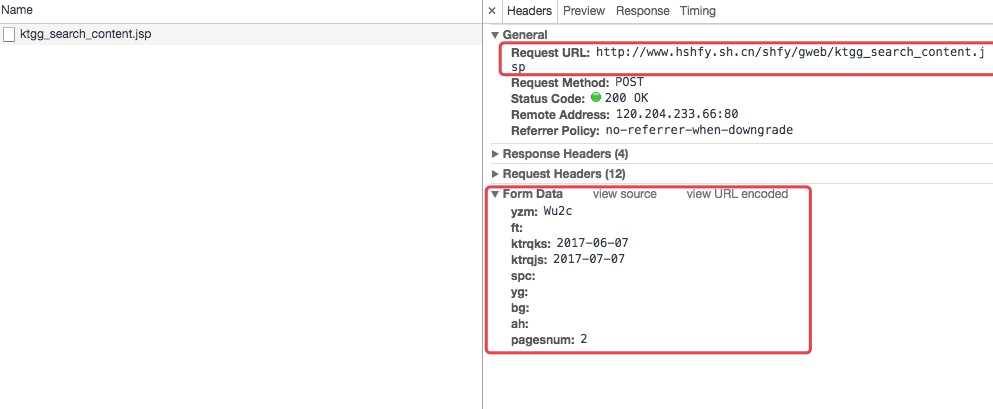
通过上图我们可以分析几个对我们有用的数据就是请求地址以及请求参数,
请求参数中,最重要的是日期以及页数
代码的功能还有待完善,只是一个初步的例子
代码地址:https://github.com/pythonsite/spider/tree/master/www.hshfy.sh.cn
python之爬虫(十一) 实例爬取上海高级人民法院网开庭公告数据
标签:spider 实现 pid 数据页面 大致 网站 http 访问 git
原文地址:https://www.cnblogs.com/shuai1991/p/11072140.html