标签:http img nump size 来源 品牌 简单的 筛选 活动
下午学习了python数据分析的应用案例---金融营销活动中欺诈用户行为分析。数据来源于DC竞赛数据:https://www.dcjingsai.com/common/cmpt/2018%E5%B9%B4%E7%94%9C%E6%A9%99%E9%87%91%E8%9E%8D%E6%9D%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BB%BA%E6%A8%A1%E5%A4%A7%E8%B5%9B_%E7%AB%9E%E8%B5%9B%E4%BF%A1%E6%81%AF.html,详细数据信息可去网站查看,标签为1表“羊毛党”,0表“正常用户”
首先,数据导入
1 import numpy as np 2 import pandas as pd 3 from collections import Counter 4 import matplotlib.pyplot as plt 5 from pymining import itemmining,assocrules,perftesting,seqmining 6 import pyecharts as pe 7 rt=pd.read_csv(r"E:\transaction_train_new.csv",sep=",") 8 ro=pd.read_csv(r"E:\operation_train_new.csv",sep=",") 9 rtt=pd.read_csv(r"E:\tag_train_new.csv",sep=",")
然后,数据预处理与简单统计
1 #数据处理与简单统计 2 rt=pd.merge(rt,rtt) 3 ro=pd.merge(ro,rtt)#把标签与行为合并方便结合标签分析行为 4 z1=ro.day.astype(np.str) 5 z2=rt.day.astype(np.str)#把day转为字符串 6 ro.time=pd.to_datetime("2018-01-"+z1+" "+ro.time) 7 rt.time=pd.to_datetime("2018-01-"+z2+" "+rt.time)#把time下面单纯的小时改为标准模式的时间 8 #统计用户总数,羊毛党数量,交易行为数,操作行为数 9 print(len(rtt.UID.values),len(rtt[rtt.Tag==1].UID.values),len(rt),len(ro))
其次,欺诈用户的一般特征分析。
从两个方面1,羊毛党通常事务性操作很少,交易性操作较多。2、羊毛党,通常会多个用户共用银行账户、各种设备等信息
1、#行为时序分析
plt.plot(ro[ro.Tag==1].groupby("day").size())
plt.plot(ro[ro.Tag==0].groupby("day").size())#查看两类用户的事务性数据操作
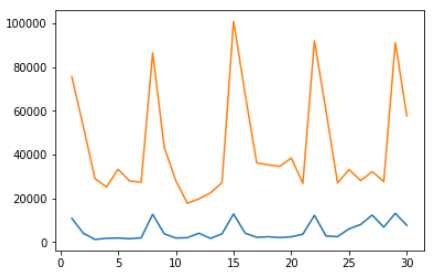
图中,蓝色为“羊毛党”,黄色为“普通用户。可见,羊毛党的事务操作较少,而交易性操作较多,即以尽可能少的成本获取尽可能多的利益
plt.plot(rt[rt.Tag==1].groupby("day").size())
plt.plot(rt[rt.Tag==0].groupby("day").size())#查看两类用户的交易性操作
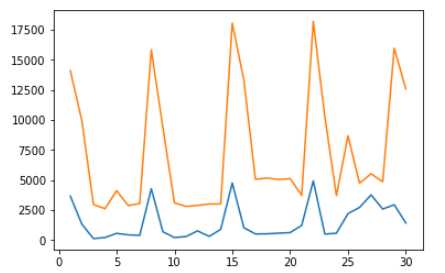
2、多账户羊毛党行为分析
1 #多账号羊毛,多个账号公用银行帐号、各种设备号、手机 2 def cl(x): 3 return set(x.UID.values) 4 z2=rt[rt.acc_id2.notnull()].groupby("acc_id2").apply(cl)#统计各转出账号acc_id2下的用户 5 p2=Counter(z2.apply(len).values)#acc_id2用户数量类别的计数 6 plt.loglog(p2.keys(),p2.values(),"o")#近似为幂函数曲线,数据明显存在问题
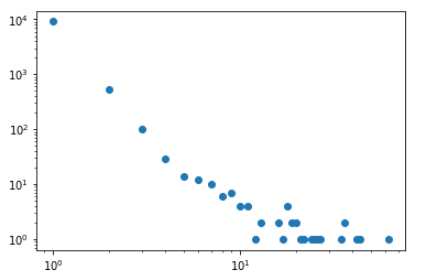
1 #记录各acc_id2下用户数大于3的用户ID,疑似为羊毛党ID 2 z4=set([]) 3 for i in z2.values: 4 if len(i)>3: 5 z4=z4|i 6 z5=set(rt[rt.Tag==1].UID.values) 7 print(len(z4),len(z5),len(z4&z5))#查看预测的羊毛党数量,实际的羊毛党数量,预测对的羊毛党数量
845 3993 725
1 #同理分析某一标签x0下的用户,>x1的为疑似羊毛党 2 def u1(x0,x1): 3 def cl(x): 4 return set(x.UID.values) 5 z2=rt.groupby(x0).apply(cl) 6 p2=Counter(z2.apply(len).values) 7 plt.loglog(p2.keys(),p2.values(),"o") 8 z4=set([]) 9 for i in z2.values: 10 if len(i)>x1: 11 z4=z4|i 12 return [z4,len(z4),len(z5),len(z4&z5)]
定义函数u1(x0,x1)分析x0标签下,疑似为用户共用情况,共用用户数>x1则认为是羊毛党
在"acc_id1"”acc_id2“"acc_id3""device_code1""device_code2"下分析羊毛党行为
1 y1=u1("acc_id1",3)#以ip作为分析指标 2 y1[1:4] 3 [845, 3993, 725] 4 y2=u1("acc_id2",2) 5 y2[1:4] 6 [333, 3993, 322] 7 y3=u1("acc_id3",3)#以ip作为分析指标 8 y3[1:4] 9 [298, 3993, 287] 10 de1=u1("device_code1",4)#以同-设备号上有>4个用户,疑似为羊毛党 11 de1[1:4] 12 [1338, 3993, 809] 13 de2=u1("device_code2",4)#手机品牌标签下的羊毛党分析 14 de2[1:4] 15 [1023, 3993, 805]
最后,汇总分析这5个指标的筛选结果
1 w=y1[0]|y2[0]|y3[0]|de1[0]|de2[0] 2 print(len(w),len(z5),len(w&z5)) 3 f0=len(w&z5)/len(w) 4 f1=len(w&z5)/len(z5) 5 f2=f0*f1*2/(f0+f1) 6 print(f0,f1,f2)#仅仅用简单的条件就能达到0.4以上
1967 3993 1282
0.6517539400101677 0.3210618582519409 0.4302013422818792
标签:http img nump size 来源 品牌 简单的 筛选 活动
原文地址:https://www.cnblogs.com/dahongbao/p/11073697.html