标签:range iterator env code ofo 判断 tuple 启动 while
用列表生成式生成一个列表
[ i*2 for i in range(10) ]
这就是一个列表生成式。
列表生成式使得创建列表代码变得简洁。但是,如果一个列表很大,这样创建就比较耗内存了。如果列表元素可以按照某种算法推算出来,那我们就可以在循环过程中不断推算出后续的元素,这样就不用创建一个完整的list。从而节省内存空间。在python中这种一边循环一边计算的机制,就称为生成器(generator)。
要创建一个generator,有很多方法,第一种方法很简单,只需要把一个列表生成式的[]换成()就创建了一个generator。
先写一个简单的生成器
#!/usr/bin/env python
# -- coding:utf-8 --
# 列表生成式
import datetime
import time
starttime1 = datetime.datetime.now()
b = ( i*2 for i in range(100000000) )
for i in b:
print i
time.sleep(1)
endtime1 = datetime.datetime.now()
print (endtime1 - starttime1).seconds
我起了一个1核1G的虚机,如果上述代码采用列表去循环程序直接OOM被killed了。但是我如果采用上述代码只会在程序启动的时候内存使用率偏高,之后几乎很少占用内存,这很明显就体现了生成器的优势。
generator非常强大。如果推算的算法比较复杂,还可以用函数来实现。
下面就来用生成器实现一个斐波那契数列。
斐波那契数列:除了第一个和第二个数之外,任意一个数都是由前面两个数相加得到。在数学上,斐波纳契数列以如下被以递推的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=3,n∈N*)
1,1,2,3,5,8...
def fibo(n):
a,b = 0,1
while n > 0:
print b
a,b = b,a+b
n -= 1
fibo(10)生成这样一个数列直接用类似列表生成式的方式就比较麻烦了,上述函数变成生成器只需要将print变成yield就可以了但是他将打印出来一个生成器而不是具体的数据,生成器是边计算边执行的它跟列表的不同之处就在于它只有一个next方法每一条数据都需要执行next方法才能得到。
#!/usr/bin/env python
def fibo(n):
a,b = 0,1
while n > 0:
#print b
yield b
a,b = b,a+b
n -= 1
print fibo(10)
f = fibo(10)
print f.next()输出结果却跟上边的代码有所不同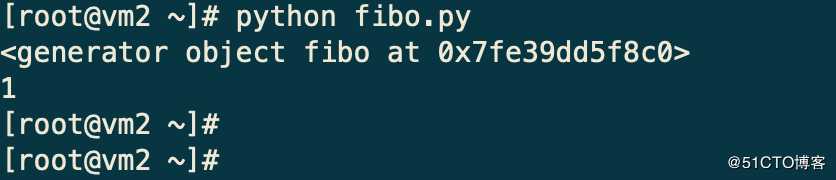
这里只打印了第一个元素,因为生成器是边计算边生成的,每调用一次next方法才会由下一个值。要遍历所有数据只要一个for循环即可:
#!/usr/bin/env python
def fibo(n):
a,b = 0,1
while n > 0:
#print b
yield b
a,b = b,a+b
n -= 1
print fibo(10)
f = fibo(10)
for i in f:
print i这个yield关键字,改变了原有的函数执行流程,函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
2.迭代器:
可以直接用于for循环的对象统称为可迭代对象:Iterable。
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
可以使用isinstance()判断一个对象是否是Iterable对象。
>>> from collections import Iterable
>>> isinstance([],Iterable)
True
>>>
>>> isinstance({},Iterable)
True
>>> isinstance(‘abc‘, Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(10, Iterable)
False
>>>
生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象:
>>> from collections import Iterator
>>>
>>> isinstance((x for x in range(10)),Iterator)
True
>>> isinstance([],Iterator)
False
>>> isinstance({},Iterator)
False
>>> isinstance(‘abc‘, Iterator)
False
>>>
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator)
True
>>> isinstance(iter(‘abc‘), Iterator)
True为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
参考链接:https://www.liaoxuefeng.com/wiki/1016959663602400/1017323698112640
标签:range iterator env code ofo 判断 tuple 启动 while
原文地址:https://blog.51cto.com/14244213/2412461