标签:_id 好的 区别 native select hang sage replica 垂直
垂直拆分就是要把表按模块划分到不同数据库表中(当然原则还是不破坏第三范式)
垂直切分只是把表按模块划分到不同数据库,但没有解决单表大数据量的问题,而水平切分就是要把一个表按照某种规则把数据划分到不同表或数据库里。
Scale Out是指Application可以在水平方向上扩展。一般对数据中心的应用而言,Scale out指的是当添加更多的机器时,应用仍然可以很好的利用这些机器的资源来提升自己的效率从而达到很好的扩展性。
Scale Up是指Application可以在垂直方向上扩展。一般对单台机器而言,Scale Up值得是当某个计算节点(机器)添加更多的CPU Cores,存储设备,使用更大的内存时,应用可以很充分的利用这些资源来提升自己的效率从而达到很好的扩展性
使用水平分割拆分表,具体根据业务需求,有的按照注册时间、取摸、账号规则、年份等。
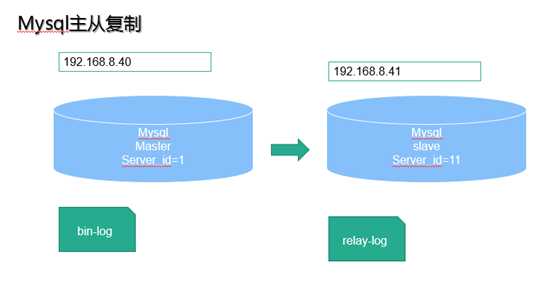
影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中。假设,实时的将变化了的日志系统中的数据库事件操作,在MYSQL-A的3306端口,通过网络发给MYSQL-B。 MYSQL-B收到后,写入本地日志系统B,然后一条条的将数据库事件在数据库中完成。 那么,MYSQL-A的变化,MYSQL-B也会变化,这样就是所谓的MYSQL的复制,即MYSQL replication。
在上面的模型中,MYSQL-A就是主服务器,即master,MYSQL-B就是从服务器,即slave。
日志系统A,其实它是MYSQL的日志类型中的二进制日志,也就是专门用来保存修改数据库表的所有动作,即bin log。【注意MYSQL会在执行语句之后,释放锁之前,写入二进制日志,确保事务安全】
日志系统B,并不是二进制日志,由于它是从MYSQL-A的二进制日志复制过来的,并不是自己的数据库变化产生的,有点接力的感觉,称为中继日志,即relay log。
可以发现,通过上面的机制,可以保证MYSQL-A和MYSQL-B的数据库数据一致,但是时间上肯定有延迟,即MYSQL-B的数据是滞后的。【即便不考虑什么网络的因素,MYSQL-A的数据库操作是可以并发的执行的,但是MYSQL-B只能从relay log中读一条,执行下。因此MYSQL-A的写操作很频繁,MYSQL-B很可能跟不上。】
1、准备环境:两台windows操作系统ip分别为: 172.27.185.1(主)、172.27.185.2(从)
2、连接到主服务(172.27.185.1)服务器上,给从节点分配账号权限。
GRANT REPLICATION SLAVE ON *.* TO ‘root‘@‘172.27.185.2‘ IDENTIFIED BY ‘root‘;
3、在主服务my.ini文件新增
|
server-id=200 log-bin=mysql-bin relay-log=relay-bin relay-log-index=relay-bin-index |
重启mysql服务
4、在从服务my.ini文件新增
|
server-id = 210 replicate-do-db =itmayiedu#需要同步数据库 |
重启mysql服务
5、从服务同步主数据库
|
# 需要先关闭所有连接,不允许多个连接 stop slave; # 建立主从管道 change master to master_host=‘172.27.185.1‘,master_user=‘root‘,master_password=‘root‘; # 开始同步 start slave; # 查看状态,日志 show slave status; |
在数据库集群架构中,让主库负责处理事务性查询,而从库只负责处理select查询,让两者分工明确达到提高数据库整体读写性能。当然,主数据库另外一个功能就是负责将事务性查询导致的数据变更同步到从库中,也就是写操作。
1)分摊服务器压力,提高机器的系统处理效率
读写分离适用于读远比写的场景,如果有一台服务器,当select很多时,update和delete会被这些select访问中的数据堵塞,等待select结束,并发性能并不高,而主从只负责各自的写和读,极大程度的缓解X锁和S锁争用;
假如我们有1主3从,不考虑上述1中提到的从库单方面设置,假设现在1分钟内有10条写入,150条读取。那么,1主3从相当于共计40条写入,而读取总数没变,因此平均下来每台服务器承担了10条写入和50条读取(主库不承担读取操作)。因此,虽然写入没变,但是读取大大分摊了,提高了系统性能。另外,当读取被分摊后,又间接提高了写入的性能。所以,总体性能提高了,其实就是拿机器和带宽换性能;
2)增加冗余,提高服务可用性,当一台数据库服务器宕机后可以调整另外一台从库以最快速度恢复服务
是一个开源的分布式数据库系统,但是因为数据库一般都有自己的数据库引擎,而Mycat并没有属于自己的独有数据库引擎,所有严格意义上说并不能算是一个完整的数据库系统,只能说是一个在应用和数据库之间起桥梁作用的中间件。
在Mycat中间件出现之前,MySQL主从复制集群,如果要实现读写分离,一般是在程序段实现,这样就带来了一个问题,即数据段和程序的耦合度太高,如果数据库的地址发生了改变,那么我的程序也要进行相应的修改,如果数据库不小心挂掉了,则同时也意味着程序的不可用,而对于很多应用来说,并不能接受;
引入Mycat中间件能很好地对程序和数据库进行解耦,这样,程序只需关注数据库中间件的地址,而无需知晓底层数据库是如何提供服务的,大量的通用数据聚合、事务、数据源切换等工作都由中间件来处理;
Mycat中间件的原理是对数据进行分片处理,从原有的一个库,被切分为多个分片数据库,所有的分片数据库集群构成完成的数据库存储,有点类似磁盘阵列中的RAID0.
配置server.xml:
<!-- 添加user --> <user name="mycat"> <property name="password">mycat</property> <property name="schemas">mycat</property> </user> <!-- 添加user --> <user name="mycat_red"> <property name="password">mycat_red</property> <property name="schemas">mycat</property> <property name="readOnly">true</property> </user>
配置schema.xml:
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://org.opencloudb/"> <!-- 与server.xml中user的schemas名一致 --> <schema name="mycat" checkSQLschema="true" sqlMaxLimit="100"> <table name="t_users" primaryKey="user_id" dataNode="dn1" rule="rule1"/> <table name="t_message" type="global" primaryKey="messages_id" dataNode="dn1" /> </schema> <dataNode name="dn1" dataHost="jdbchost" database="weibo_simple" /> <dataHost name="jdbchost" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostMaster" url="172.27.185.1:3306" user="root" password="root"> </writeHost> <writeHost host="hostSlave" url="172.27.185.2:3306" user="root" password="root"/> </dataHost> </mycat:schema>
标签:_id 好的 区别 native select hang sage replica 垂直
原文地址:https://www.cnblogs.com/woniusky/p/11077510.html