标签:inf 技术 str ESS 结构 提交 its data img
1.spark SQL简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程对象,叫DataFrame,并且作为分布式SQL查询引擎的作用
2.为什么要学习spark SQL
2.1 我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性
2.2 MapReduce这种计算模型效率慢,代码繁碎,很多开发者都习惯使用sql,所以Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快,而且Spark SQL也支持从Hive中读取数据
3.spark SQL特点

3.1 集成 3.2 同意的访问方式 3.3hive集成 3.4标准连接
4.DataFrame的概念
(1)DataFram是组成命名列的数据集,它在概念上等同于关系数据库中的表,,但在底层具有更丰富的优化
(2)DataFrame可以从各种来源构建,列如:结构化数据文件, hive中的表,外部数据库或现有RDD
(3)DataFrame API支持的语言有Scala,Java,Python和R
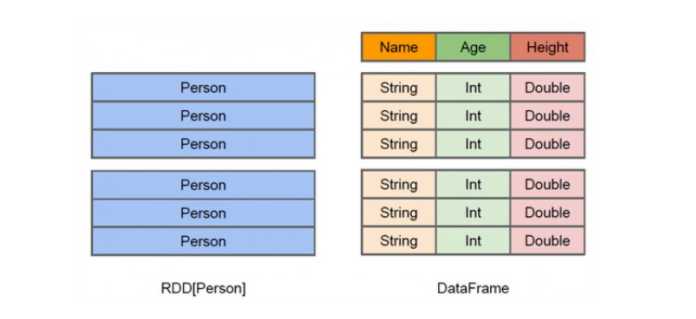
(4)从上图可以看出,DataFrame多了数据的结构信息,即schema(创建DataFrame的一种方式,后边详细介绍),RDD是分布式的 Java对象的集合
(5)DataFrame是分布式的Row对象的集合,DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化
val row = lines.map ( _.split ( "," )).map ( tp => Row ( tp ( 0 ).toInt, tp ( 1 ), tp ( 2 ), tp ( 3 ), tp ( 4 ).toDouble, tp ( 5 ).toDouble, tp ( 6 ).toInt ))
val frame: DataFrame = unit.map(tp=>{ val splits=tp.split(" ") val id=splits(0).toInt val name=splits(1) val age=splits(2).toInt val result=splits(3).toInt (id,name,age,result) }).toDF("id","name","age","address")
5.DataSet的概念
(1)Dataset是数据的分布式集合,Dataset是在Spark 1.6中添加的一个新接口,是DataFrame之上更高一级的抽象
(2)Dataset提供了RDD的优点(强类型化,使用强大的lambda函数的能力)以及Spark SQL优化后的执行引擎的优点
(3)一个Dataset 可以从JVM对象构造,然后使用函数转换(map, flatMap,filter等)去操作
(4)Dataset API 支持Scala和Java, Python不支持Dataset API
标签:inf 技术 str ESS 结构 提交 its data img
原文地址:https://www.cnblogs.com/wangshuang123/p/11089192.html