标签:条件 不能 show 有一个 并发 row 一对多 插入 min
CURD、约束、事务 相关
数据库连接:
MySQL本地数据库:mysql -u userName -ppassWord
MySQL远程数据库:mysql -h IP_Address -p 3306(port,默认3306) -u userName -ppassWord
-p后面的密码不要有空格,或者-p后直接连接,会提示输入密码
用来定义数据库对象:数据库,表,列等。关键字:create(创建) drop(删除) alter(修改) truncate(清空数据记录) show等
Create
创建
创建数据库的三种方式:
CREATE DATABASE databaseName
CREATE DATABASE IF NOT EXISTS databaseName
CREATE DATABASE databaseName character set 字符集
创建表(创建表时需要正在使用一个数据库):
CREATE TABLE 表名 (字段名 字段类型,字段名 字段类型,...);
快速创建一个结构相同的表:CREATE TABLE newTableName LIKE oldTableName
MySQL中常用数据类型:
类型 | 描述
| :-: | :-: |
| int | 整型|
| double | 浮点型 |
| varchar | 字符串 |
| date | 日期类型,格式为yyyy-MM-dd,只有年月日,没有时分秒 |
例子:
CREATE TABLE student (
id INT,
name VARCHAR(20),
birthday DATE
);Show
查看所有数据库:SHOW DATABASES
查看数据库创建信息:SHOW CREATE DATABASE databaseName
查看所有表:SHOW TABLES
查看表结构:DESC tableName
查看创建表的SQL语句:SHOW CREATE TABLE tableName
Desc
describe:形容,描述
查看表结构:DESC tableName
Alter
修改
修改表字符集:ALTER TABLE tableName character set utf8
修改数据库字符集:
ALTER DATABASE databaseName character set utf8;//修改字符编码为utf-8
注意不要写错单词!是Database不是Datebase,Data是数据,Date是日期,更新是update,新旧当然是和日期有关 --一个拼错却找不出bug的菜鸟的碎碎念
编码:
| 类型 | - | - | - | - |
|---|---|---|---|---|
| Java中的常用编码 | UTF-8 | GBK | GB2312 | ISO-8859-1 |
| 对应mysql数据库中的编码 | utf8 | gbk | gb2312 | latin1 |
修改表结构(不常用):
添加表列:ALTER TABLE tableName ADD 字段名 类型
修改列类型:ALTER TABLE tableName MODIFY 字段名 新类型
修改列名:ALTER TABLE tableName CHANGE 旧字段名 新字段名 类型
删除列:ALTER TABLE tableName DROP 字段名
Rename:修改表名:RENAME tableName TO newTableName
Drop
删除
删除数据库:DROP DATABASE databaseName
删除表:DROP TABLE tableName
判断表是否存在并删除表:DROP TABLE IF EXISTS tableName
删除所有数据:TRUNCATE TABLE tableName
Select
选择(查询)
查看正在使用的数据库:SELECT DATABASE();
Use
使用/切换数据库:USE databaseName
在数据库表中更新,增加和删除记录。如 update(更新), insert(插入), delete(删除) 不包含查询
Insert
插入数据:INSERT INTO tableName (字段名1,字段名2,...) VALUES (值1,值2,...)(可以添加部分字段,未添加数据的字段会用null默认)
或者不写字段名:INSERT INTO tableName VALUES ()
此时必须写出所有列的数据,没有可用null表示插入空,并且此时可以使用多个括号同时插入多条数据。
插入时数据需要符合其类型和长度,字符串、日期一般用单引号括起来。
蠕虫复制:
在已有表的基础上,将表2的数据复制到表1上:INSERT INTO tableName1 SELECT * FROM tableName2(复制所有数据)
复制特定字段数据:INSERT INTO tableName1(字段1, 字段2...) SELECT 字段1,字段2... FROM tableName2
可以配合创建相同结构表:CREATE TABLE tableName1 LIKE tableName2
Update
修改数据:UPDATE tableName SET 字段名=值
带条件修改:UPDATE tableName SET 字段名=值 WHERE 条件(正确的修改方式)
Delete
删除数据:DELETE FROM tableName
带条件删除:DELETE FROM tableName WHERE 条件(正确的删除方式)
清空数据:TRUNCATE TABLE tableName
数据表记录的查询。关键字select。
Select
查询列数据:SELECT 字段名1,字段名2... FROM tableName(一般不使用不加限定的查询列)
可使用“*”匹配所有列:SELECT * FROM tableName(一般不使用不加限定的查询列)
执行查询时一般使用别称方便阅读:SELECT name AS 姓名, age AS 年龄 FROM student;(不加AS貌似也可以)
去重查询:SELECT DISTINCT 列名 FROM tableName
运算查询:SELECT 列名 + 常量或列名 FROM tableName(参与预算的字段必须是数值类型)
是用来设置或更改数据库用户或角色权限的语句,如grant(设置权限),revoke(撤销权限),begin transaction等。这个比较少用到。
单行注释:#,或者--(注意--后面有个空格)
多行注释:/* */
# 这是单行注释
-- 这也是单行注释
/*
这是多行注释
*/查询时可使用一下比较运算符和逻辑运算符进行条件限制:
| 约束 | 符号 |
|---|---|
| 大于 | > |
| 小于 | < |
| 大于等于 | >= |
| 小于等于 | <= |
| 等于 | = |
| 不等于 | != , <> |
| 且 | and(&&) |
| 或 | or( |
| 非 | not(!) |
比如查询年龄大于20且性别为男的学生:
SELECT * FROM tableName WHERE age > 20 AND sex = ‘男‘;
In
IN可用作多个条件时的查询:
比如查询条件是id为1、3、5的:WHERE id IN (1,3,5)
Between ... And ...
Between and 和用作在一定范围之内的查询:
比如查询条件为English在60到100之间的数据:WHERE english BETWEEN 60 AND 100
Like
模糊查询,可以使用通配字符串:WHERE 字段名 LIKE ‘通配字符串‘
MySQL的通配符有两个:
%:匹配任意个字符_:匹配一个字符例如查询所有姓马的学员:SELECT * FROM tableName WHERE name LIKE ‘马%‘;
名字有马的:WHERE name LIKE ‘%马%‘
两个字的姓马的:WHERE name LIKE ‘马_‘
Order By
SELECT 字段 FROM 表名 ORDER BY 排序的字段1 ASC或者DESC, 排序的字段2 ASC或者DESC...
ASC:升序(默认),ascend:上升
DESC:降序,descend:下降
聚合函数为纵向查询,null不做统计
Count:计算指定列个数
Sum:计算指定列的数值和,如果不是数值类型,那么计算结果为0
Max:最大值
Min:最小值
avg:平均值
ifnull(列名, 默认值):null和任何值相加都为null,该关键字可以判断是否为null,若为null则返回默认值
例子:查询总数:SELECT COUNT(*) FROM tableName;
年龄大于20的数量:SELECT COUNT(*) FROM tableName WHERE age > 20;
查询最大年龄:SELECT MAX(age) FROM tableName
查询id=1的英语和数学分数的总和:select sum(ifnull(math, 0) + ifnull(english,0)) from tableName where id=1
Group By:对查询进行分组
例子:查询产品及其价格和,并以产品名分组,select product, sum(price) from ord group by product;
Having
where后面不允许添加聚合函数,因此可以使用having配合group by来进行约束。
例子:查询每一种商品的总价大于30的商品,并显示总价:select product ,sum(price) from ord group by product having sum(price) > 30;
注意:having 必须配合group by使用,并且和where 使用方法一样,具体区别为:
例子:select ... from ... where 条件1 ... group by ... having 条件2
执行顺序为从前至后,条件1过滤 -> 分组 -> 条件2过滤
一般遇到每种每个时都使用分组。
Limit
限制查询条数:select * from tableName limit offset, row_count;
查询下标从0开始,第二个参数为查询条数(若第一个参数为0则可以省略)。
备份命令:mysqldump -u root -p 数据库名 > d:\dir\A\1.sql
导入命令:mysql -u root -p 数据库名 < d:\dir\A\1.sql(恢复数据库需要手动创建数据库)
大于号小于号可以看做箭头
约束种类
PRIMARY KEY: 主键约束(主键不能为空不能重复)UNIQUE: 唯一约束(不能重复)NOT NULL: 非空约束(不能是null)DEFAULT: 默认值(添加默认值)FOREIGN KEY: 外键约束Auto_Increment
自增,一般设置为主键。
DELETE和TRUNCATE的区别:TRUNCATE可以重置自增,Delete不能。
添加外键约束:
constraint 外键约束名称 foreign key(当前表中的列名) references 被引用表名(被引用表的列名)
举例:constraint coder_project_id foreign key(coder_id) references coder(id);constraint: 添加约束,可以不写
foreign key(当前表中的列名): 将某个字段作为外键
references 被引用表名(被引用表的列名) : 外键一般引用主表的主键
添加外键约束的两种方式:
ALTER TABLE tableName FOREIGN KEY(被约束列) REFERENCES 引用表(引用列)CREATE TABLE tableName(
first_id int,
second_id int,
CONSTRAINT conName1 FOREIGN KEY(first_id) REFERENCES otherTable1(id),
CONSTRAINT conName2 FOREIGN KEY(second_id) REFERENCES otherTable2(id)
);ON UPDATE CASCADE:级联更新,主键发生更新时,外键也会更新
ON DELETE CASCADE:级联删除,主键发生删除时,外键也会删除
上例中就可以添加外间的级联操作:
CREATE TABLE tableName(
first_id int,
second_id int,
CONSTRAINT conName1 FOREIGN KEY(first_id) REFERENCES otherTable1(id) ON UPDATE CASCADE ON DELETE CASCADE,
CONSTRAINT conName2 FOREIGN KEY(second_id) REFERENCES otherTable2(id)ON UPDATE CASCADE ON DELETE CASCADE
);一对多:一对多的时候可以在多的表里添加一列,并使用少的表的主键作为约束。(例如作者与书籍,可以在书籍表里添加一列)
一对一:使用较少,在哪个表里添加都可以。
多对多:建立中间表
关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式),一般来说满足第三范式即可。(贴个简单易懂的博客)
简单来说:
多表查询方式:SELECT * FROM tableName1, tableName2
这种方法会产生笛卡尔积,一般限制主键=外键来得到有效结果。
例子:SELECT * FROM tableName1, tableName2 WHERE tableName1.id = tableName2.id
内连接
隐式内连接:看不到JOIN关键字,条件使用WHERE指定,如上例。
显式内连接(标准内连接):SELECT * FROM tableName1 INNER JOIN tableName2 ON 条件(INNER可以省略)
左外链接
无论表2有无都会查询表1的数据:SELECT * FROM tableName1 LEFT OUTER JOIN tableName2 ON 条件(OUTER可省略)
右外连接
无论表1有无都会查询表2的数据:SELECT * FROM tableName1 RIGHT OUTER JOIN tableName2 ON 条件(OUTER可省略)
一条查询语句结果作为另一条查询语法一部分,该查询即为子查询。
子查询结果是单行单列时:
查询工资最高的员工信息:SELECT * FROM employee WHERE salary=(SELECT MAX(salary) FROM employee);
该查询还有另外一种实现:SELECT * FROM employee ORDER BY salary DESC LIMIT 1;
两种查询性能孰优孰劣先不做讨论,但子查询可以实现更多需求:
查询工资高于平均工资的员工:SELECT * FROM employee WHERE salary > (SELECT AVG(salary) FROM employee);
子查询结果是多行单列时:
SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);
子查询结果是多行多列时:
SELECT 查询字段 FROM 表1 表1别名,(子查询) 子查询表别名 WHERE 条件;
例如:在员工表emp和部门表dept查询2011年以后入职的员工信息,包括部门名称:SELECT * FROM dept d, (SELECT * FROM emp WHERE join_date>‘2011-1-1‘) e WHERE d.id=e.dept_id;
另一种方式是使用表链接:SELECT d.*, e.* FROM dept d INNER JOIN emp e ON d.id = e.dept_id WHERE e.join_date > ‘2011-1-1‘;(d.*和e.*可以省略为*)
简单练习:
现在有四张表:学生表(student)、课程表(course)、学生课程表(studentCourse)、教师表(teacher),表关系如下:
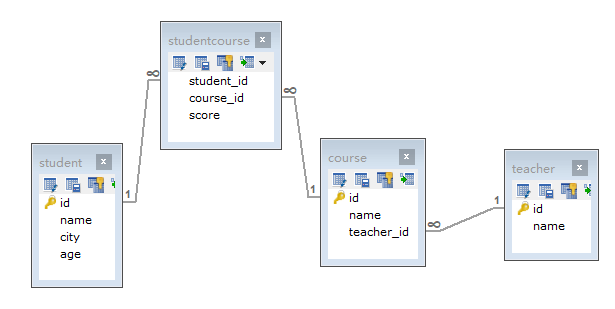
1、查询最高分的学生信息
-- 查询获得最高分的学生信息。
# 暴力三重查询
SELECT
*
FROM
student
WHERE id IN
(SELECT
`student_id`
FROM
`studentcourse`
WHERE score =
(SELECT
MAX(score)
FROM
`studentcourse`)) ;
# 内联加子查询
SELECT
s.*
FROM
student s
INNER JOIN `studentcourse` sc
ON s.`id` = sc.`student_id`
WHERE sc.`score` =
(SELECT
MAX(score)
FROM
`studentcourse`) ;
# 仅使用子查询
SELECT
*
FROM
student
WHERE id =
(SELECT
`student_id`
FROM
`studentcourse`
ORDER BY score DESC
LIMIT 1) ;
# 仅使用内联
SELECT
s.*
FROM
student s
INNER JOIN `studentcourse` sc
ON s.`id` = sc.`student_id`
ORDER BY sc.`score` DESC
LIMIT 1 ;2、查询编号2课程的成绩比编号1课程最高成绩还高的学生信息。
-- 查询编号2课程的成绩比编号1课程最高成绩还高的学生信息。
# 暴力三重
SELECT
*
FROM
student
WHERE id IN
(SELECT
`student_id`
FROM
`studentcourse` sc
WHERE sc.`course_id` = 2 && sc.`score` >
(SELECT
MAX(score)
FROM
`studentcourse`
WHERE `course_id` = 1)) ;
# 内联加子查询
SELECT
s.*
FROM
student s
INNER JOIN `studentcourse` sc
ON s.`id` = sc.`student_id`
WHERE `course_id` = 2 && sc.`score` >
(SELECT
MAX(score)
FROM
`studentcourse`
WHERE `course_id` = 1) ;3、查询编号2课程的成绩比编号1课程最高成绩还高的学生姓名和成绩。
-- 查询编号2课程的成绩比编号1课程最高成绩还高的学生姓名和成绩。
# 暴力三重
SELECT
s.`name`,
sc.`score`
FROM
student s,
(SELECT
`student_id`,
score
FROM
studentcourse
WHERE course_id = 2 && score >
(SELECT
MAX(score)
FROM
studentcourse
WHERE `course_id` = 1)) AS sc
WHERE s.`id` = sc.student_id ;
# 内联加子查询
SELECT
s.`name`,
sc.`score`
FROM
student s
INNER JOIN `studentcourse` sc
ON s.`id` = sc.`student_id`
WHERE `course_id` = 2 && sc.`score` >
(SELECT
MAX(score)
FROM
`studentcourse`
WHERE `course_id` = 1) ;4、查询每个同学的学号、姓名、选课数、总成绩。(想要使用子查询的聚合函数则需要给该聚合函数起别名)
-- 查询每个同学的学号、姓名、选课数、总成绩。
SELECT
s.`id`,
s.`name`,
sc.countcourse,
sc.sumscore
FROM
student s,
(SELECT
student_id,
COUNT(`course_id`) countcourse,
SUM(score) sumscore
FROM
`studentcourse`
GROUP BY `student_id`) sc
WHERE s.`id` = sc.student_id ;MYSQL中可以有两种方式进行事务的操作:
| 事务的操作 | MySQL操作事务的语句 |
|---|---|
| 开启事务 | start transaction |
| 提交事务 | commit |
| 回滚事务 | rollback |
| 查询事务的自动提交情况 | show variables like ‘%commit%‘ |
| 设置事务的自动提交方式 | set autocommit = 0 -- 关闭自动提交 |
ACID是指 Atomicity(原子性)、Consistensy(一致性)、Isolation(隔离型)和 Durability(持久性)。
| 事务特性 | 含义 |
|---|---|
| 原子性(Atomicity) | 事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 |
| 一致性(Consistency) | 事务前后数据的完整性必须保持一致。事务的成功与失败,最终数据库的数据都是符合实际生活的业务逻辑。一致性绝大多数依赖业务逻辑和原子性 |
| 隔离性(Isolation) | 是指多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间数据要相互隔离,不能相互影响。 |
| 持久性(Durability) | 指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响 |
| 并发访问的问题 | 含义 |
|---|---|
| 脏读 | 一个事务读取到了另一个事务中尚未提交的数据。最严重,杜绝发生。 |
| 不可重复读 | 一个事务中两次读取的数据内容不一致,要求的是一个事务中多次读取时数据是一致的,这是事务update时引发的问题。(强调数据内容不一致) |
| 幻读 | 一个事务内读取到了别的事务插入的数据,导致前后读取记录行数不同。这是insert或delete时引发的问题。(强调数据数量不一致) |
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复读 | 幻读 | 数据库默认隔离级别 |
|---|---|---|---|---|---|---|
| 1 | 读未提交 | read uncommitted | 是 | 是 | 是 | |
| 2 | 读已提交 | read committed | 否 | 是 | 是 | Oracle和SQL Server |
| 3 | 可重复读 | repeatable read | 否 | 否 | 是 | MySQL |
| 4 | 串行化 | serializable | 否 | 否 | 否 |
查询全局事务隔离级别:
show variables like '%isolation%';
-- 或
select @@tx_isolation;设置事务隔离级别,需要重新连接MySQL:set global transaction isolation level 隔离级别;
标签:条件 不能 show 有一个 并发 row 一对多 插入 min
原文地址:https://www.cnblogs.com/lixin-link/p/11099298.html