标签:info ble 大数 tran 就是 绿色 ldl 数组元素 hash
1. Java7中的HashMap:
大方向上HashMap是一个数组,每个数组元素是一个单向链表。
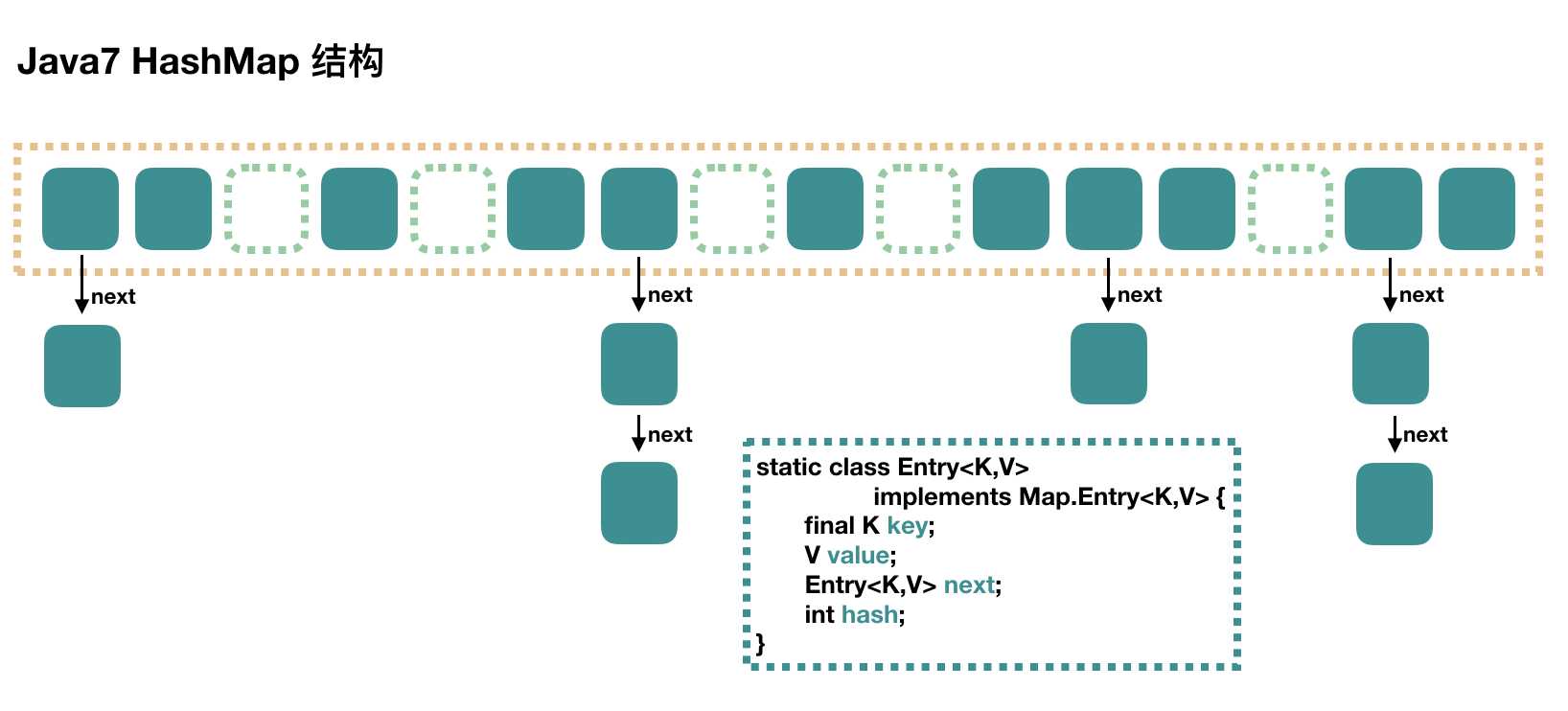
上图中每个绿色的实体是嵌套类Entry的实例,Entry包含4个属性:key,value,hash,和单链表的next。
capacity:数组的容量,始终保持在2^n,每次扩容后大小为扩容前的2倍。
loadfactor:扩容因子,始终保持在0.75。
threshold:扩容的阈值,大小为:capacity*loadfactor。
1.1put方法的过程:
总结:
当第一次插入时需要初始化数组的大小(threshold);
判断如果key为空就将这个Entry放入到table[ 0 ]中;
否则计算key的hash值,遍历单链表,若该位置已有元素,就进行覆盖,并返回旧值;
若不存在重复的值,就将该Entry放入到链表中。
1 public V put(K key, V value) { 2 // 当插入第一个元素的时候,需要先初始化数组大小 3 if (table == EMPTY_TABLE) { 4 inflateTable(threshold); 5 } 6 // 如果 key 为 null,感兴趣的可以往里看,最终会将这个 entry 放到 table[0] 中 7 if (key == null) 8 return putForNullKey(value); 9 // 1. 求 key 的 hash 值 10 int hash = hash(key); 11 // 2. 找到对应的数组下标 12 int i = indexFor(hash, table.length); 13 // 3. 遍历一下对应下标处的链表,看是否有重复的 key 已经存在, 14 // 如果有,直接覆盖,put 方法返回旧值就结束了 15 for (Entry<K,V> e = table[i]; e != null; e = e.next) { 16 Object k; 17 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 18 V oldValue = e.value; 19 e.value = value; 20 e.recordAccess(this); 21 return oldValue; 22 } 23 } 24 25 modCount++; 26 // 4. 不存在重复的 key,将此 entry 添加到链表中,细节后面说 27 addEntry(hash, key, value, i); 28 return null; 29 }
1.2数组(大小)的初始化:
当第一个数组元素放入HashMap时,就进行一次数组的初始化,就是先计算数组的大小,再计算阈值(threshold),并始终将数组内元素的数量保持在2^n个。
1 private void inflateTable(int toSize) { 2 // 保证数组大小一定是 2 的 n 次方。 3 // 比如这样初始化:new HashMap(20),那么处理成初始数组大小是 32 4 int capacity = roundUpToPowerOf2(toSize); 5 // 计算扩容阈值:capacity * loadFactor 6 threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); 7 // 算是初始化数组吧 8 table = new Entry[capacity]; 9 initHashSeedAsNeeded(capacity); //ignore 10 }
1.3计算数组的位置:
根据key的Hash值,来对数组长度进行取模。eg:当数组长度为32时,可以取key的hash值的后5位,来进行计算相应数组中位置。
1.4添加结点到链表中:
找到数组下标后,进行key判重,若没有重复,就将该元素放到链表的表头位置。
以下方法首先判断是否需要扩容,如果扩容后,就将元素放到相应数组位置上链表的表头处。
1 void addEntry(int hash, K key, V value, int bucketIndex) { 2 // 如果当前 HashMap 大小已经达到了阈值,并且新值要插入的数组位置已经有元素了,那么要扩容 3 if ((size >= threshold) && (null != table[bucketIndex])) { 4 // 扩容,后面会介绍一下 5 resize(2 * table.length); 6 // 扩容以后,重新计算 hash 值 7 hash = (null != key) ? hash(key) : 0; 8 // 重新计算扩容后的新的下标 9 bucketIndex = indexFor(hash, table.length); 10 } 11 // 往下看 12 createEntry(hash, key, value, bucketIndex); 13 } 14 // 这个很简单,其实就是将新值放到链表的表头,然后 size++ 15 void createEntry(int hash, K key, V value, int bucketIndex) { 16 Entry<K,V> e = table[bucketIndex]; 17 table[bucketIndex] = new Entry<>(hash, key, value, e); 18 size++; 19 }
1.5数组的扩容:
扩容就是将小数组扩大成大数组再将元素转移到大数组中。双倍扩容:比如原数组(每个数组中放的其实是一个链表)中old [ i]的元素,会放到新数组的new [ i] ,和new [ i+oldlength]的位置上。
1 void resize(int newCapacity) { 2 Entry[] oldTable = table; 3 int oldCapacity = oldTable.length; 4 if (oldCapacity == MAXIMUM_CAPACITY) { 5 threshold = Integer.MAX_VALUE; 6 return; 7 } 8 // 新的数组 9 Entry[] newTable = new Entry[newCapacity]; 10 // 将原来数组中的值迁移到新的更大的数组中 11 transfer(newTable, initHashSeedAsNeeded(newCapacity)); 12 table = newTable; 13 threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); 14 }
1.6 get过程的分析:
Java7/8中的HashMap和ConcurrentHashMap全解析
标签:info ble 大数 tran 就是 绿色 ldl 数组元素 hash
原文地址:https://www.cnblogs.com/xbfchder/p/11100468.html