标签:比较 必须 更新 阴影 理解 main 归并 循环 交换
了解和实现冒泡排序、选择排序、插入排序、希尔排序、归并排序、和快速排序。
1.冒泡排序
冒泡排序要对一个列表多次重复遍历。
它们的顺序是否正确。
def bubble_sort(alist):
n = len(alist)
# 外层循环控制比较几次
for i in range(n-1):
# 内存循环控制 第i次 交换 n-i 趟
# -i 是不再换前i次已经排好的
for j in range(n-i-1):
if alist[j] > alist[j+1]:
alist[j], alist[j+1] = alist[j+1], alist[j]
# print(alist)
由于冒泡排序要遍历整个未排好的部分,它可以做一些大多数排序方法做不到的事。
def shortBubbleSort(alist):
n = len(alist)
# 外层循环控制比较几次
for i in range(n-1):
# 假设已经完全排好序
sorted = True
# 内存循环控制 第i次 交换 n-i 趟
# -i 是不再换前i次已经排好的
for j in range(n-1-i):
if alist[j] > alist[j+1]:
alist[j], alist[j+1] = alist[j+1], alist[j]
# 未完全排好序
sorted = False
if sorted: # 发现列表已排好时立刻结束
return
print(alist)
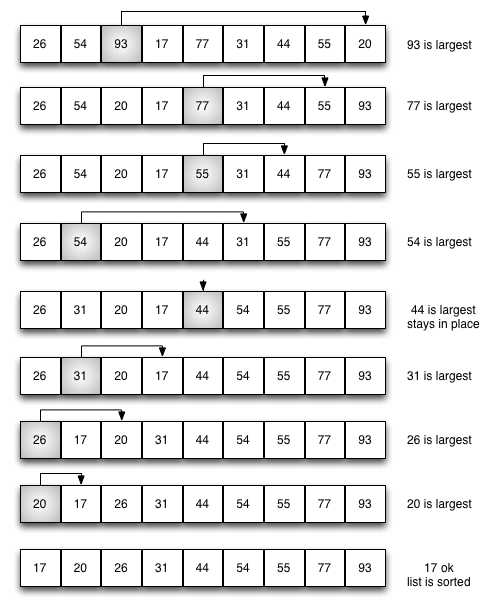
2.选择排序
选择排序提高了冒泡排序的性能,
def selectionSort(alist):
# 外层控制比较几次,一共需要 n-1 次遍历来排好 n 个数据
for fillslot in range(len(alist)-1, 0, -1):
# 假设第一次元素就是最大值
position_max = 0
# 内层控制元素比较和更新索引
for location in range(1, fillslot+1):
# 进行比较
if alist[location] > alist[position_max]:
# 更新索引
position_max = location
# 退出循环后,交换数据
alist[fillslot], alist[position_max] = alist[position_max], alist[fillslot]
测试:
if __name__ == "__main__":
alist = [54, 26, 93, 17, 77, 31, 44, 55, 20]
print(alist)
selectionSort(alist)
print(alist)
3.插入排序
插入排序的算法复杂度仍然是O(n2),但其工作原理稍有不同。
图4展示了插入排序的过程。阴影区域的数据代表了程序每运行一步后排好的子表。

def insertionSort(alist):
# 外层循环控制 从右边第二个元素开始 向前面排好序的子列表中插入
for index in range(1, len(alist)):
pos = index
# 内存循环 依次从子列表的最后一个最大的元素 和 你要插入的元素比较
# 如果你的当前要插入的元素小,两个元素交换位置
while pos > 0 and alist[pos-1] > alist[pos]:
alist[pos], alist[pos - 1] = alist[pos-1], alist[pos]
pos -= 1
测试:
if __name__ == ‘__main__‘:
lst = [54, 26, 93, 17, 77, 31, 44, 55, 20]
print(lst)
insertionSort(lst)
print(lst)
4. 希尔排序
希尔排序有时又叫做“缩小间隔排序”,它以插入排序为基础,将原来要排序的列表划分为一些子列表,再对每一个子列表执行插入排序,从而实现对插入排序性能的改进。划分子列的特定方法 是希尔排序的关键。我们并不是将原始列表分成含有连续元素的子列,而是确定一个划分列表的增量“i”,这个i更准确地说,是划分的间隔。然后把每间隔为i 的所有元素选出来组成子列表。
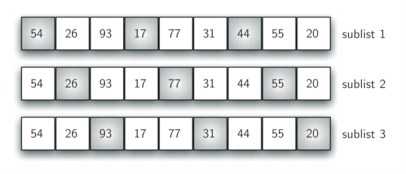
这里有一个含九个元素的列表。
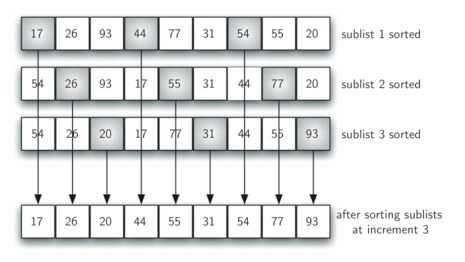
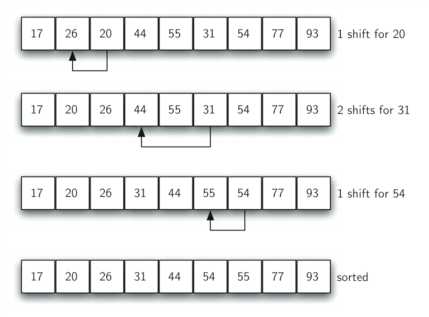
在这个例子中,我们仅需要再进行四次移动就可以完成排序。
def shellSort(alist):
# 我们从含2个元素的子列开始排序, 子列表的数目 就是列表长度的一半
sublistcount = len(alist)//2
while sublistcount > 0:
# 每个子列表执行插入排序
for startpostion in range(sublistcount):
# 间隔正好是 子列表的数量
print("alist: %s" % alist, "startpostion: %d" % startpostion, "sublistcount %d" % sublistcount)
gapInsertionSort(alist, startpostion, sublistcount)
print("After increments of size", sublistcount, "The list is", alist)
sublistcount = sublistcount // 2
def gapInsertionSort(alist, start, gap):
for i in range(start+gap, len(alist), gap):
pos = i
while pos >= gap and alist[pos-gap] > alist[pos]:
alist[pos], alist[pos-gap] = alist[pos-gap], alist[pos]
pos -= gap
测试:
if __name__ == ‘__main__‘:
# 奇数次第一组第一次是三个元素 [54,77,20]
# alist = [54, 26, 93, 17, 77, 31, 44, 55, 20]
# 偶数次比较好看
alist = [54, 26, 93, 17, 77, 31, 44, 55]
shellSort(alist)
print(alist)
缩减版:
def shell_sort(lst):
step = int(len(lst)/2)
while step > 0:
for i in range(step, len(lst)):
while i >= step and lst[i] < lst[i - step]:
lst[i], lst[i - step] = lst[i - step], lst[i]
i -= step
step = int(step/2)
print(lst)
alist = [54, 26, 93, 17, 77, 31, 44, 55, 20]
shell_sort(alist)
对希尔排序的综合算法分析已经远超出讨论范围,基于对该算法的描述,
5.归并排序
我们现在把注意力转移到用分而治之的策略来改进排序算法的表现。
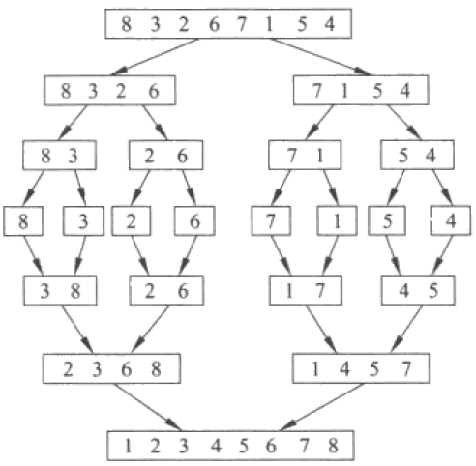
def merge_sort(alist):
n = len(alist)
# 递归结束条件
if n <= 1:
return alist
# 中间位置
mid = n // 2
# 递归拆分左侧
left_lst = merge_sort(alist[:mid])
# 递归拆分右侧
right_lst = merge_sort(alist[mid:])
return merge(left_lst, right_lst)
def merge(left, right):
print(left, right)
# 需要两个游标,分别指向左列表和右列表的第一个元素
left_point, right_point = 0, 0
# 定义最终返回的结果集
result = []
# 循环合并数据
while left_point < len(left) and right_point < len(right):
# 谁小放前面
if left[left_point] <= right[right_point]:
# 放入结果集
result.append(left[left_point])
# 游标移动
left_point += 1
else:
result.append(right[right_point])
right_point += 1
# print("合并数据后:", result)
# print(‘left: ‘, left[left_point:])
# print(‘right: ‘, right[right_point:])
# 退出循环时,形成左右两个序列
result += left[left_point:]
result += right[right_point:]
return result
if __name__ == ‘__main__‘:
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
lst = [8, 3, 2, 6, 7, 1, 5, 4]
print(lst)
sort_lst = merge_sort(lst)
print(lst)
print(sort_lst)
为了分析归并算法,我们需要考虑它实施的两个不同步骤。
6.快速排序
快速排序用了和归并排序一样分而治之的方法来获得同样的优势,但同时不需要使用额外的存储空间。
经过权衡之后,我们发现列表不分离成两半是可能的,当这发生的时候,我们可以看到,操作减少了。
快速排序算法的工作原理如下:
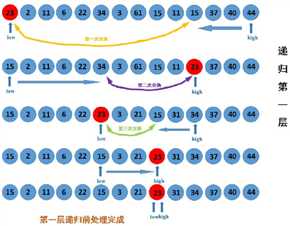
# first 理解为第一个位置的索引,last 是最后位置索引
def quick_sort(alist, first, last):
# 递归中止条件
if first >= last:
return
# 设置第一个元素为中间值
mid_value = alist[first]
# low 指向
low = first
# high
high = last
# 只要 low 小于 high 就一直走
flag = 0
while low < high:
# high 大于中间值,则进入循环
while low < high and alist[high] >= mid_value:
# high 往左走
high -= 1
# 出循环后,说明high小于中间值,low指向该值
alist[low] = alist[high]
# low 小于中间值,则进入循环
while low < high and alist[low] < mid_value:
# low 往右走
low += 1
# 出循环后,说明low 大于中间值,high 指向该值
alist[high] = alist[low]
if not flag:
print(alist)
# 退出整个循环后,low 和 high 相等
# 将中间值放到中间位置
alist[low] = mid_value
print(alist)
flag = 1
# 递归
# 先对左侧快排
quick_sort(alist, first, low-1)
# 对右侧快排
quick_sort(alist, low+1, last)
测试:
if __name__ == "__main__":
lst = [54, 26, 93, 17, 77, 31, 44, 55, 20]
print("原来的list:\n", lst)
quick_sort(lst, 0, len(lst) - 1)
print("快速排序后的list: \n", lst)
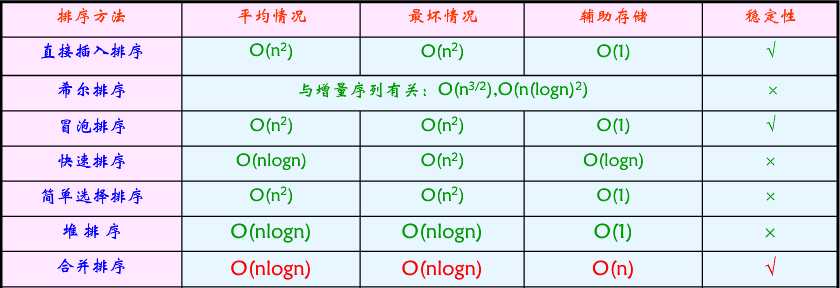
各种排序方法的比较:
标签:比较 必须 更新 阴影 理解 main 归并 循环 交换
原文地址:https://www.cnblogs.com/51try-again/p/11105230.html