标签:词向量 spl mic 数据 img 有一个 都差不多 就是 数字
神经网络中有各种归一化算法:Batch Normalization (BN)、Layer Normalization (LN)、Instance Normalization (IN)、Group Normalization (GN)。从公式看它们都差不多,如 (1) 所示:无非是减去均值,除以标准差,再施以线性映射。
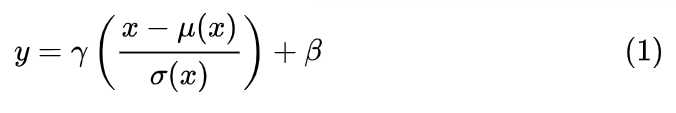
Batch Normalization
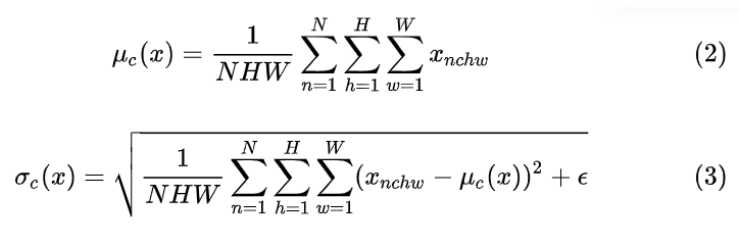
Batch Normalization (BN) 是最早出现的,也通常是效果最好的归一化方式。feature map:![]() 包含 N 个样本,每个样本通道数为 C(在NLP中为词向量长度),高为 H(在NLP中为时间长度),宽为 W(在NLP中为1)。对其求均值和方差时,将在 N、H、W上操作,而保留通道 C 的维度。具体来说,就是把第1个样本的第1个通道,加上第2个样本第1个通道 ...... 加上第 N 个样本第1个通道,求平均,得到通道 1 的均值(注意是除以 N×H×W 而不是单纯除以 N,最后得到的是一个代表这个 batch 第1个通道平均值的数字,而不是一个 H×W 的矩阵)。求通道 1 的方差也是同理。对所有通道都施加一遍这个操作,就得到了所有通道的均值和方差。具体公式为:
包含 N 个样本,每个样本通道数为 C(在NLP中为词向量长度),高为 H(在NLP中为时间长度),宽为 W(在NLP中为1)。对其求均值和方差时,将在 N、H、W上操作,而保留通道 C 的维度。具体来说,就是把第1个样本的第1个通道,加上第2个样本第1个通道 ...... 加上第 N 个样本第1个通道,求平均,得到通道 1 的均值(注意是除以 N×H×W 而不是单纯除以 N,最后得到的是一个代表这个 batch 第1个通道平均值的数字,而不是一个 H×W 的矩阵)。求通道 1 的方差也是同理。对所有通道都施加一遍这个操作,就得到了所有通道的均值和方差。具体公式为:
如果把![]() 类比为一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 W 个字符。BN 求均值时,相当于把这些书按页码一一对应地加起来(例如第1本书第36页,第2本书第36页......),再除以每个页码下的字符总数:N×H×W,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字),有C页,求标准差时也是同理。
类比为一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 W 个字符。BN 求均值时,相当于把这些书按页码一一对应地加起来(例如第1本书第36页,第2本书第36页......),再除以每个页码下的字符总数:N×H×W,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字),有C页,求标准差时也是同理。
Layer Normalization
BN 的一个缺点是需要较大的 batchsize 才能合理估训练数据的均值和方差,这导致内存很可能不够用,同时它也很难应用在训练数据长度不同的 RNN 模型上。Layer Normalization (LN) 的一个优势是不需要批训练,在单条数据内部就能归一化
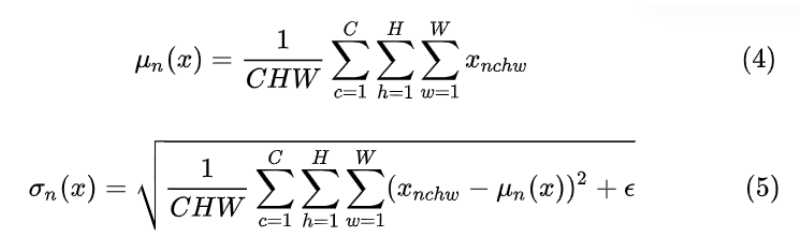
对于![]() LN 对每个样本的 C、H、W 维度上的数据求均值和标准差,保留 N 维度。其均值和标准差公式为:
LN 对每个样本的 C、H、W 维度上的数据求均值和标准差,保留 N 维度。其均值和标准差公式为:
继续采用上一节的类比,把一个 batch 的 feature 类比为一摞书。LN 求均值时,相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W,即求整本书的“平均字”,有N本书,求标准差时也是同理。
Instance Normalization
Instance Normalization (IN) 最初用于图像的风格迁移。作者发现,在生成模型中, feature map 的各个 channel 的均值和方差会影响到最终生成图像的风格,因此可以先把图像在 channel 层面归一化,然后再用目标风格图片对应 channel 的均值和标准差“去归一化”,以期获得目标图片的风格。IN 操作也在单个样本内部进行,不依赖 batch。
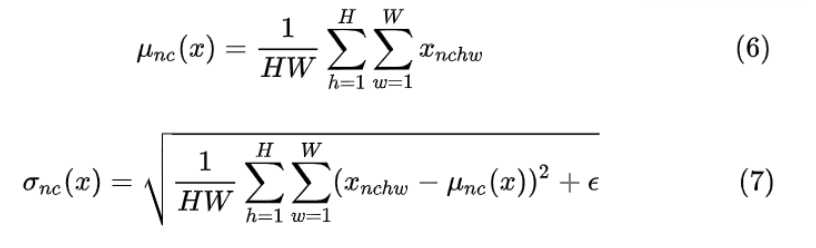
IN 求均值时,相当于把一页书中所有字加起来,再除以该页的总字数:H×W,即求每页书的“平均字”,求标准差时也是同理。
标签:词向量 spl mic 数据 img 有一个 都差不多 就是 数字
原文地址:https://www.cnblogs.com/callyblog/p/11108283.html