本文主要说明两个问题:JMM存在的意义是什么?JMM内部的工作原理是什么(重点讲一下并发编程模式下的数据访问一致性问题) 。
1.为什么要使用JMM?
当我们刚开始接触JAVA语言的时候,就会被告知JAVA程序是可以实现跨平台运行的(即同一份代码资源可运行在不同的硬件配置下,不同的操作系统下)。那么JAVA 是如何在不同的硬件和操作系统内存访问方式存在差异的情况下,实现 同一个Java 程序在各种平台下的运行结果都相同(达到一致的内存访问效果)的呢。靠的就是神奇的JMM。
在这里要牢记两个事实:
(1)我们平时所写的每一行程序代码其实就是对计算机发出的一个操作指令,而这些指令的运行空间是CPU。
(2)程序中不可避免的会涉及到对变量和临时数据的读取与写入。而这些变量和临时数据是存储在物理内存memory中的。
而CPU和内存两者之间存在一个很明显的速度不匹配问题:
CPU 执行速度很快,而从内存读取数据和向内存写入数据的过程跟 CPU 执行指令的速度比起来要差几个数量级,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。
为解决该矛盾,人们便在CPU和内存之间增加了高速缓存cache,如下图所示:
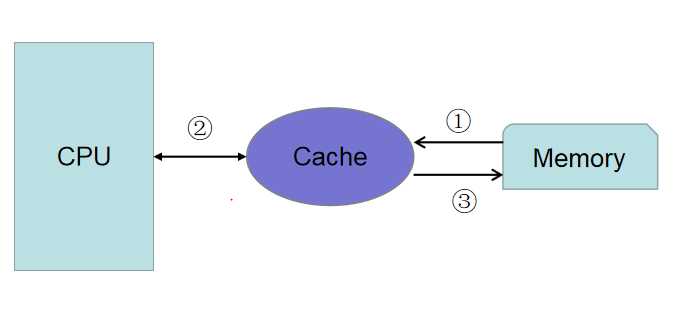
增加了cache后,程序的执行过程就变为:
(1)将运算需要的数据从主存复制一份到CPU的高速缓存当中
(2)CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据
(3)运算结束之后,再将高速缓存中的数据刷新到主存当中。
事实上,CPU上可能同时开多个线程,多个线程对同一份数据进行访问,很容易出现数据访问不一致的问题。如何保证数据访问的一致性是我们JMM要解决的关键问题。
2.JMM的内部工作机制
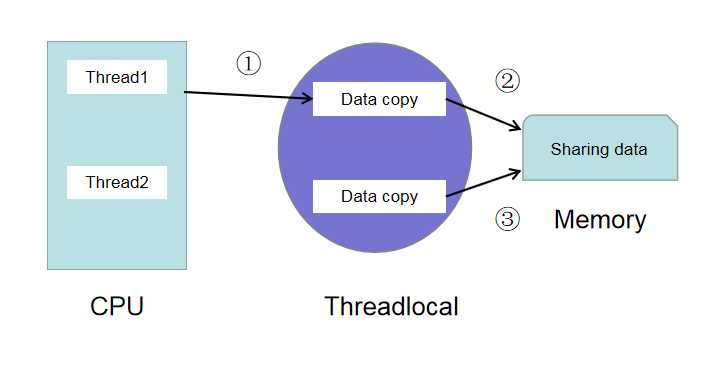
java内存模型和jvm内存模型是不一样,要区分开。如上图所示,多个线程对共享变量并没有直接采用加锁的方式,其中
(1)实际内存(也叫主内存)中存储的是待共享的变量值。
(2)CPU中每个线程可以保留共享变量的副本。其中保存共享副本的地方称为每一个线程的工作内存threadLocal。每一个线程只能直接操作对应工作内存中的变量。
而不同线程之间的变量值传递则需要通过主内存(memory)来完成。如何保证主内存和线程工作内存的数据一致性,是我们需要重点关注的地方:
事实上,JMM中使用volatile关键字保证主内存和线程工作内存的数据一致性.
其工作原理大致如下:
(1)线程A的工作内存中的变量一旦发生了变化,就会有监视器检测到该变化。
(2)检测器通知CPU将该变化值刷新到内存。
(3)其他线程B/C..,在使用同一个变量时,为保证访问到的数据确实是线程A修改过的新数据,其采用的是CAS乐观锁策略(简单理解就是,永远以主存中的内容为参考)。即,
1)拿自己工作内存中的变量值和主存中的变量值比较
2)如果相等,则使用工作内存threadLocal里的变量
3)如果不相等,则用主内存的变量替换本地的变量
而JMM的性能问题,则是通过指令重排的方式保证。