标签:c语言实现 标记 double 资源 trail getattr 数学 驼峰命名 维护
写在前面(自补):初听PEP8一头雾水,不知所谓.啥是PEP8?为啥叫PEP8?PEP8是干啥的?-先了解下PEP吧.
PEP的全称是Python Enhancement Proposals,其中Enhancement是增强改进的意思,Proposals则可译为提案或建议书,所以合起来,比较常见的翻译是Python增强提案或Python改进建议书。
我个人倾向于前一个翻译,因为它更贴切。Python核心开发者主要通过邮件列表讨论问题、提议、计划等,PEP通常是汇总了多方信息,经过了部分核心开发者review和认可,最终形成的正式文档,起到了对外公示的作用,所以我认为翻译成“提案”更恰当。
PEP的官网是:https://www.python.org/dev/peps/,这也就是PEP 0 的地址。其它PEP的地址是将编号拼接在后面,例如:https://www.python.org/dev/peps/pep-0020/ 就是PEP 20 的链接,以此类推。
第一个PEP诞生于2000年,现在正好是18岁成年。到目前为止,它拥有478个“兄弟姐妹”。
官方将PEP分成三类:
I - Informational PEP
P - Process PEP
S - Standards Track PEP
其含义如下:
信息类:这类PEP就是提供信息,有告知类信息,也有指导类信息等等。例如PEP 20(The Zen of Python,即著名的Python之禅)、PEP 404 (Python 2.8 Un-release Schedule,即宣告不会有Python2.8版本)。
流程类:这类PEP主要是Python本身之外的周边信息。例如PEP 1(PEP Purpose and Guidelines,即关于PEP的指南)、PEP 347(Migrating the Python CVS to Subversion,即关于迁移Python代码仓)。
标准类:这类PEP主要描述了Python的新功能和新实践(implementation),是数量最多的提案。。
每个PEP最初都是一个草案(Draft),随后会经历一个过程,因此也就出现了不同的状态。以下是一个流程图:
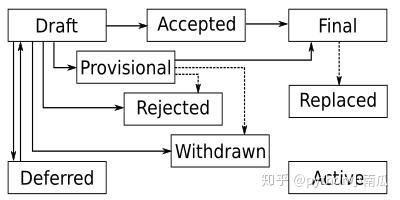
A – Accepted (Standards Track only) or Active proposal 已接受(仅限标准跟踪)或有效提案
D – Deferred proposal 延期提案
F – Final proposal 最终提案
P – Provisional proposal 暂定提案
R – Rejected proposal 被否决的提案
S – Superseded proposal 被取代的提案
W – Withdrawn proposal 撤回提案
在PEP 0(Index of Python Enhancement Proposals (PEPs))里,官方列举了所有的PEP,你可以按序号、按类型以及按状态进行检索。而在PEP 1(PEP Purpose and Guidelines)里,官方详细说明了PEP的意图、如何提交PEP、如何修复和更新PEP、以及PEP评审的机制等等。
为什么要读PEP?
无论你是刚入门Python的小白、有一定经验的从业人员,还是资深的黑客,都应该阅读Python增强提案。
阅读PEP至少有如下好处:
(1)了解Python有哪些特性,它们与其它语言特性的差异,为什么要设计这些特性,是怎么设计的,怎样更好地运用它们;
(2)跟进社区动态,获知业内的最佳实践方案,调整学习方向,改进工作业务的内容;
(3)参与热点议题讨论,或者提交新的PEP,为Python社区贡献力量。
说到底,学会用Python编程,只是掌握了皮毛。PEP提案是深入了解Python的途径,是真正掌握Python语言的一把钥匙,也是得心应手使用Python的一本指南。
哪些PEP是必读的?
如前所述,PEP提案已经累积产生了478个,我们并不需要对每个PEP都熟知,没有必要。下面,我列举了一些PEP,推荐大家一读:
PEP 0 – Index of Python Enhancement Proposals
PEP 7 – Style Guide for C Code,C扩展
PEP 8 – Style Guide for Python Code,编码规范(必读)
PEP 20 – The Zen of Python,Python之禅
PEP 202 – List Comprehensions,列表生成式
PEP 274 – Dict Comprehensions,字典生成式
PEP 234 – Iterators,迭代器
PEP 257 – Docstring Conventions,文档注释规范
PEP 279 – The enumerate() built-in function,enumerate枚举
PEP 282 – A Logging System,日志模块
PEP 285 – Adding a bool type,布尔值
PEP 289 – Generator Expressions,生成器表达式
PEP 318 – Decorators for Functions and Methods,装饰器
PEP 342 – Coroutines via Enhanced Generators,协程
PEP 343 – The “with” Statement,with语句
PEP 380 – Syntax for Delegating to a Subgenerator,yield from语法
PEP 405 – Python Virtual Environments,虚拟环境
PEP 471 – os.scandir() function,遍历目录
PEP 484 – Type Hints,类型约束
PEP 492 – Coroutines with async and await syntax,async/await语法
PEP 498 – Literal String Interpolation Python,字符串插值
PEP 525 – Asynchronous Generators,异步生成器
PEP 572 – Assignment Expressions,表达式内赋值(最争议)
PEP 3105 – Make print a function,print改为函数
PEP 3115 – Metaclasses in Python 3000,元类
PEP 3120 – Using UTF-8 as the default source encoding
PEP 3333 – Python Web Server Gateway Interface v1.0.1,Web开发
PEP 8000 – Python Language Governance Proposal Overview,GvR老爹推出决策层后,事关新决策方案
以下转自CSDN冒冒大虾.文章出处:原文链接:https://blog.csdn.net/ratsniper/article/details/78954852
本文提供的Python代码编码规范基于Python主要发行版本的标准库。Python的C语言实现的C代码规范请查看相应的PEP指南1。
这篇文档以及PEP 257(文档字符串的规范)改编自Guido原始的《Python Style Guide》一文,同时添加了一些来自Barry的风格指南2。
这篇规范指南随着时间的推移而逐渐演变,随着语言本身的变化,过去的约定也被淘汰了。
许多项目有自己的编码规范,在出现规范冲突时,项目自身的规范优先。
Guido的一条重要的见解是代码阅读比写更加频繁。这里提供的指导原则主要用于提升代码的可读性,使得在大量的Python代码中保持一致。就像PEP 20提到的,“Readability counts”。
这是一份关于一致性的风格指南。这份风格指南的风格一致性是非常重要的。更重要的是项目的风格一致性。在一个模块或函数的风格一致性是最重要的。
然而,应该知道什么时候应该不一致,有时候编码规范的建议并不适用。当存在模棱两可的情况时,使用自己的判断。看看其他的示例再决定哪一种是最好的,不要羞于发问。
特别是不要为了遵守PEP约定而破坏兼容性!
几个很好的理由去忽略特定的规则:
每一级缩进使用4个空格。
续行应该与其包裹元素对齐,要么使用圆括号、方括号和花括号内的隐式行连接来垂直对齐,要么使用挂行缩进对齐3。当使用挂行缩进时,应该考虑到第一行不应该有参数,以及使用缩进以区分自己是续行。
推荐:
# 与左括号对齐
foo = long_function_name(var_one, var_two,
var_three, var_four)
# 用更多的缩进来与其他行区分
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
# 挂行缩进应该再换一行
foo = long_function_name(
var_one, var_two,
var_three, var_four)1234567891011121314不推荐:
# 没有使用垂直对齐时,禁止把参数放在第一行
foo = long_function_name(var_one, var_two,
var_three, var_four)
# 当缩进没有与其他行区分时,要增加缩进
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)123456789四空格的规则对于续行是可选的。
可选:
# 挂行缩进不一定要用4个空格
foo = long_function_name(
var_one, var_two,
var_three, var_four)1234当if语句的条件部分长到需要换行写的时候,注意可以在两个字符关键字的连接处(比如if),增加一个空格,再增加一个左括号来创造一个4空格缩进的多行条件。这会与if语句内同样使用4空格缩进的代码产生视觉冲突。PEP没有明确指明要如何区分i发的条件代码和内嵌代码。可使用的选项包括但不限于下面几种情况:
# 没有额外的缩进
if (this_is_one_thing and
that_is_another_thing):
do_something()
# 增加一个注释,在能提供语法高亮的编辑器中可以有一些区分
if (this_is_one_thing and
that_is_another_thing):
# Since both conditions are true, we can frobnicate.
do_something()
# 在条件判断的语句添加额外的缩进
if (this_is_one_thing
and that_is_another_thing):
do_something()123456789101112131415(可以参考下面关于是否在二进制运算符之前或之后截断的讨论)
在多行结构中的大括号/中括号/小括号的右括号可以与内容对齐单独起一行作为最后一行的第一个字符,就像这样:
my_list = [
1, 2, 3,
4, 5, 6,
]
result = some_function_that_takes_arguments(
'a', 'b', 'c',
'd', 'e', 'f',
)123456789或者也可以与多行结构的第一行第一个字符对齐,就像这样:
my_list = [
1, 2, 3,
4, 5, 6,
]
result = some_function_that_takes_arguments(
'a', 'b', 'c',
'd', 'e', 'f',
)12345678空格是首选的缩进方式。
制表符只能用于与同样使用制表符缩进的代码保持一致。
Python3不允许同时使用空格和制表符的缩进。
混合使用制表符和空格缩进的Python2代码应该统一转成空格。
当在命令行加入-t选项执行Python2时,它会发出关于非法混用制表符与空格的警告。当使用–tt时,这些警告会变成错误。强烈建议使用这样的参数。
所有行限制的最大字符数为79。
没有结构化限制的大块文本(文档字符或者注释),每行的最大字符数限制在72。
限制编辑器窗口宽度可以使多个文件并行打开,并且在使用代码检查工具(在相邻列中显示这两个版本)时工作得很好。
大多数工具中的默认封装破坏了代码的可视化结构,使代码更难以理解。避免使用编辑器中默认配置的80窗口宽度,即使工具在帮你折行时在最后一列放了一个标记符。某些基于Web的工具可能根本不提供动态折行。
一些团队更喜欢较长的行宽。如果代码主要由一个团队维护,那这个问题就能达成一致,可以把行长度从80增加到100个字符(更有效的做法是将行最大长度增加到99个字符),前提是注释和文档字符串依然已72字符折行。
Python标准库比较保守,需要将行宽限制在79个字符(文档/注释限制在72)。
较长的代码行选择Python在小括号,中括号以及大括号中的隐式续行方式。通过小括号内表达式的换行方式将长串折成多行。这种方式应该优先使用,而不是使用反斜杠续行。
反斜杠有时依然很有用。比如,比较长的,多个with状态语句,不能使用隐式续行,所以反斜杠是可以接受的:
with open('/path/to/some/file/you/want/to/read') as file_1, open('/path/to/some/file/being/written', 'w') as file_2:
file_2.write(file_1.read())123(请参阅前面关于多行if-语句的讨论,以获得关于这种多行with-语句缩进的进一步想法。)
另一种类似情况是使用assert语句。
确保在续行进行适当的缩进。
几十年来,推荐的风格是在二元运算符之后中断。但是这回影响可读性,原因有二:操作符一般分布在屏幕上不同的列中,而且每个运算符被移到了操作数的上一行。下面例子这个情况就需要额外注意,那些变量是相加的,那些变量是相减的:
# 不推荐: 操作符离操作数太远
income = (gross_wages +
taxable_interest +
(dividends - qualified_dividends) -
ira_deduction -
student_loan_interest)123456为了解决这种可读性的问题,数学家和他们的出版商遵循了相反的约定。Donald Knuth在他的Computers and Typesetting系列中解释了传统规则:“尽管段落中的公式总是在二元运算符和关系之后中断,显示出来的公式总是要在二元运算符之前中断”4。
遵循数学的传统能产出更多可读性高的代码:
# 推荐:运算符和操作数很容易进行匹配
income = (gross_wages
+ taxable_interest
+ (dividends - qualified_dividends)
- ira_deduction
- student_loan_interest)123456在Python代码中,允许在二元运算符之前或之后中断,只要本地的约定是一致的。对于新代码,建议使用Knuth的样式。
顶层函数和类的定义,前后用两个空行隔开。
类里的方法定义用一个空行隔开。
相关的功能组可以用额外的空行(谨慎使用)隔开。一堆相关的单行代码之间的空白行可以省略(例如,一组虚拟实现 dummy implementations)。
在函数中使用空行来区分逻辑段(谨慎使用)。
Python接受control-L(即^L)换页符作为空格;许多工具把这些字符当作页面分隔符,所以你可以在文件中使用它们来分隔相关段落。请注意,一些编辑器和基于Web的代码阅读器可能无法识别control-L为换页,将在其位置显示另一个字形。
Python核心发布版本中的代码总是以UTF-8格式编码(或者在Python2中用ASCII编码)。
使用ASCII(在Python2中)或UTF-8(在Python3中)编码的文件不应具有编码声明。
在标准库中,非默认的编码应该只用于测试,或者当一个注释或者文档字符串需要提及一个包含内ASCII字符编码的作者名字的时候;否则,使用\x,\u,\U , 或者 \N 进行转义来包含非ASCII字符。
对于Python 3和更高版本,标准库规定了以下策略(参见 PEP 3131):Python标准库中的所有标识符必须使用ASCII标识符,并在可行的情况下使用英语单词(在许多情况下,缩写和技术术语是非英语的)。此外,字符串文字和注释也必须是ASCII。唯一的例外是(a)测试非ASCII特征的测试用例,以及(b)作者的名称。作者的名字如果不使用拉丁字母拼写,必须提供一个拉丁字母的音译。
鼓励具有全球受众的开放源码项目采取类似的政策。
推荐: import os
import sys
不推荐: import sys, os1234但是可以这样:
from subprocess import Popen, PIPE1import mypkg.sibling
from mypkg import sibling
from mypkg.sibling import example123然而,显示的指定相对导入路径是使用绝对路径的一个可接受的替代方案,特别是在处理使用绝对路径导入不必要冗长的复杂包布局时:
from . import sibling
from .sibling import example12标准库要避免使用复杂的包引入结构,而总是使用绝对路径。
不应该使用隐式相对路径导入,并且在Python 3中删除了它。
from myclass import MyClass
from foo.bar.yourclass import YourClass12如果上述的写法导致名字的冲突,那么这么写:
import myclass
import foo.bar.yourclass12然后使用“myclass.MyClass”和“foo.bar.yourclass.YourClass”。
像__all__ , __author__ , __version__ 等这样的模块级“呆名“(也就是名字里有两个前缀下划线和两个后缀下划线),应该放在文档字符串的后面,以及除from __future__ 之外的import表达式前面。Python要求将来在模块中的导入,必须出现在除文档字符串之外的其他代码之前。
比如:
"""This is the example module.
This module does stuff.
"""
from __future__ import barry_as_FLUFL
__all__ = ['a', 'b', 'c']
__version__ = '0.1'
__author__ = 'Cardinal Biggles'
import os
import sys12345678910111213在Python中,单引号和双引号字符串是相同的。PEP不会为这个给出建议。选择一条规则并坚持使用下去。当一个字符串中包含单引号或者双引号字符的时候,使用和最外层不同的符号来避免使用反斜杠,从而提高可读性。
对于三引号字符串,总是使用双引号字符来与PEP 257中的文档字符串约定保持一致。
在下列情况下,避免使用无关的空格:
Yes: spam(ham[1], {eggs: 2})
No: spam( ham[ 1 ], { eggs: 2 } )12Yes: if x == 4: print x, y; x, y = y, x
No: if x == 4 : print x , y ; x , y = y , x12ham[1:9], ham[1:9:3], ham[:9:3], ham[1::3], ham[1:9:]
ham[lower:upper], ham[lower:upper:], ham[lower::step]
ham[lower+offset : upper+offset]
ham[: upper_fn(x) : step_fn(x)], ham[:: step_fn(x)]
ham[lower + offset : upper + offset]12345不推荐:
ham[lower + offset:upper + offset]
ham[1: 9], ham[1 :9], ham[1:9 :3]
ham[lower : : upper]
ham[ : upper]1234Yes: spam(1)
No: spam (1)12Yes: dct['key'] = lst[index]
No: dct ['key'] = lst [index]12x = 1
y = 2
long_variable = 3123不推荐:
x = 1
y = 2
long_variable = 3123i = i + 1
submitted += 1
x = x*2 - 1
hypot2 = x*x + y*y
c = (a+b) * (a-b)12345不推荐:
i=i+1
submitted +=1
x = x * 2 - 1
hypot2 = x * x + y * y
c = (a + b) * (a - b)12345def complex(real, imag=0.0):
return magic(r=real, i=imag)12不推荐:
def complex(real, imag = 0.0):
return magic(r = real, i = imag)12def munge(input: AnyStr): ...
def munge() -> AnyStr: ...12不推荐:
def munge(input:AnyStr): ...
def munge()->PosInt: ...12def munge(sep: AnyStr = None): ...
def munge(input: AnyStr, sep: AnyStr = None, limit=1000): ...12不推荐:
def munge(input: AnyStr=None): ...
def munge(input: AnyStr, limit = 1000): ...12if foo == 'blah':
do_blah_thing()
do_one()
do_two()
do_three()12345最好别这样:
if foo == 'blah': do_blah_thing()
do_one(); do_two(); do_three()12if foo == 'blah': do_blah_thing()
for x in lst: total += x
while t < 10: t = delay()123绝对别这样:
if foo == 'blah': do_blah_thing()
else: do_non_blah_thing()
try: something()
finally: cleanup()
do_one(); do_two(); do_three(long, argument,
list, like, this)
if foo == 'blah': one(); two(); three()12345678910与代码相矛盾的注释比没有注释还糟,当代码更改时,优先更新对应的注释!
注释应该是完整的句子。如果一个注释是一个短语或句子,它的第一个单词应该大写,除非它是以小写字母开头的标识符(永远不要改变标识符的大小写!)。
如果注释很短,结尾的句号可以省略。块注释一般由完整句子的一个或多个段落组成,并且每句话结束有个句号。
在句尾结束的时候应该使用两个空格。
当用英文书写时,遵循Strunk and White (译注:《Strunk and White, The Elements of Style》)的书写风格。
在非英语国家的Python程序员,请使用英文写注释,除非你120%的确信你的代码不会被使用其他语言的人阅读。
块注释通常适用于跟随它们的某些(或全部)代码,并缩进到与代码相同的级别。块注释的每一行开头使用一个#和一个空格(除非块注释内部缩进文本)。
块注释内部的段落通过只有一个#的空行分隔。
有节制地使用行内注释。
行内注释是与代码语句同行的注释。行内注释和代码至少要有两个空格分隔。注释由#和一个空格开始。
事实上,如果状态明显的话,行内注释是不必要的,反而会分散注意力。比如说下面这样就不需要:
x = x + 1 # Increment x1但有时,这样做很有用:
x = x + 1 # Compensate for border1编写好的文档说明(也叫“docstrings”)的约定在PEP 257中永恒不变。
"""Return a foobang
Optional plotz says to frobnicate the bizbaz first.
"""1234Python库的命名规范很乱,从来没能做到完全一致。但是目前有一些推荐的命名标准。新的模块和包(包括第三方框架)应该用这套标准,但当一个已有库采用了不同的风格,推荐保持内部一致性。
那些暴露给用户的API接口的命名,应该遵循反映使用场景而不是实现的原则。
有许多不同的命名风格。这里能够帮助大家识别正在使用什么样的命名风格,而不考虑他们为什么使用。
以下是常见的命名方式:
也有用唯一的短前缀把相关命名组织在一起的方法。这在Python中不常用,但还是提一下。比如,os.stat()函数中包含类似以st_mode,st_size,st_mtime这种传统命名方式命名的变量。(这么做是为了与 POSIX 系统的调用一致,以帮助程序员熟悉它。)
X11库的所有公共函数都加了前缀X。在Python里面没必要这么做,因为属性和方法在调用的时候都会用类名做前缀,函数名用模块名做前缀。
另外,下面这种用前缀或结尾下划线的特殊格式是被认可的(通常和一些约定相结合):
__double_leading_underscore:(双下划线开头)当这样命名一个类的属性时,调用它的时候名字会做矫正(在类FooBar中,__boo变成了_FooBar__boo;见下文)。__double_leading_and_trailing_underscore__:(双下划线开头,双下划线结尾)“magic”对象或者存在于用户控制的命名空间内的属性,例如:__init__,__import__或者__file__。除了作为文档之外,永远不要命这样的名。永远不要使用字母‘l’(小写的L),‘O’(大写的O),或者‘I’(大写的I)作为单字符变量名。
在有些字体里,这些字符无法和数字0和1区分,如果想用‘l’,用‘L’代替。
模块应该用简短全小写的名字,如果为了提升可读性,下划线也是可以用的。Python包名也应该使用简短全小写的名字,但不建议用下划线。
当使用C或者C++编写了一个依赖于提供高级(更面向对象)接口的Python模块的扩展模块,这个C/C++模块需要一个下划线前缀(例如:_socket)
类名一般使用首字母大写的约定。
在接口被文档化并且主要被用于调用的情况下,可以使用函数的命名风格代替。
注意,对于内置的变量命名有一个单独的约定:大部分内置变量是单个单词(或者两个单词连接在一起),首字母大写的命名法只用于异常名或者内部的常量。
因为异常一般都是类,所有类的命名方法在这里也适用。然而,你需要在异常名后面加上“Error”后缀(如果异常确实是一个错误)。
(我们希望这一类变量只在模块内部使用。)约定和函数命名规则一样。
通过 from M import * 导入的模块应该使用all机制去防止内部的接口对外暴露,或者使用在全局变量前加下划线的方式(表明这些全局变量是模块内非公有)。
函数名应该小写,如果想提高可读性可以用下划线分隔。
大小写混合仅在为了兼容原来主要以大小写混合风格的情况下使用(比如 threading.py),保持向后兼容性。
始终要将 self 作为实例方法的的第一个参数。
始终要将 cls 作为类静态方法的第一个参数。
如果函数的参数名和已有的关键词冲突,在最后加单一下划线比缩写或随意拼写更好。因此 class_ 比 clss 更好。(也许最好用同义词来避免这种冲突)
遵循这样的函数命名规则:使用下划线分隔小写单词以提高可读性。
在非共有方法和实例变量前使用单下划线。
通过双下划线前缀触发Python的命名转换规则来避免和子类的命名冲突。
Python通过类名对这些命名进行转换:如果类 Foo 有一个叫 __a 的成员变量, 它无法通过 Foo.__a 访问。(执着的用户可以通过 Foo._Foo__a 访问。)一般来说,前缀双下划线用来避免类中的属性命名与子类冲突的情况。
注意:关于__names的用法存在争论(见下文)。
常量通常定义在模块级,通过下划线分隔的全大写字母命名。例如: MAX_OVERFLOW 和 TOTAL。
始终要考虑到一个类的方法和实例变量(统称:属性)应该是共有还是非共有。如果存在疑问,那就选非共有;因为将一个非共有变量转为共有比反过来更容易。
公共属性是那些与类无关的客户使用的属性,并承诺避免向后不兼容的更改。非共有属性是那些不打算让第三方使用的属性;你不需要承诺非共有属性不会被修改或被删除。
我们不使用“私有(private)”这个说法,是因为在Python中目前还没有真正的私有属性(为了避免大量不必要的常规工作)。
另一种属性作为子类API的一部分(在其他语言中通常被称为“protected”)。有些类是专为继承设计的,用来扩展或者修改类的一部分行为。当设计这样的类时,要谨慎决定哪些属性时公开的,哪些是作为子类的API,哪些只能在基类中使用。
贯彻这样的思想,一下是一些让代码Pythonic的准则:
__getattr__()。然而命名转换的算法有很好的文档说明并且很好操作。任何向后兼容保证只适用于公共接口,因此,用户清晰地区分公共接口和内部接口非常重要。
文档化的接口被认为是公开的,除非文档明确声明它们是临时或内部接口,不受通常的向后兼容性保证。所有未记录的接口都应该是内部的。
为了更好地支持内省(introspection),模块应该使用__all__属性显式地在它们的公共API中声明名称。将__all__设置为空列表表示模块没有公共API。
即使通过__all__设置过,内部接口(包,模块,类,方法,属性或其他名字)依然需要单个下划线前缀。
如果一个命名空间(包,模块,类)被认为是内部的,那么包含它的接口也应该被认为是内部的。
导入的名称应该始终被视作是一个实现的细节。其他模块必须不能间接访问这样的名称,除非它是包含它的模块中有明确的文档说明的API,例如 os.path 或者是一个包里从子模块公开函数接口的 __init__ 模块。
if foo is not None:1不推荐:
if not foo is None:1__eq__, __ne__, __lt__, __gt__, __ge__)而不是依靠其他的代码去实现特定的比较。def f(x): return 2*x1不推荐:
f = lambda x: 2*x1第一个形式意味着生成的函数对象的名称是“f”而不是泛型“< lambda >”。这在回溯和字符串显示的时候更有用。赋值语句的使用消除了lambda表达式优于显式def表达式的唯一优势(即lambda表达式可以内嵌到更大的表达式中)。
try:
import platform_specific_module
except ImportError:
platform_specific_module = None1234如果只有一个except: 块将会捕获到SystemExit和KeyboardInterrupt异常,这样会很难通过Control-C中断程序,而且会掩盖掉其他问题。如果你想捕获所有指示程序出错的异常,使用 except Exception: (只有except等价于 except BaseException:)。
两种情况不应该只使用‘excpet’块:
try:
process_data()
except Exception as exc:
raise DataProcessingFailedError(str(exc))1234为了避免和原来基于逗号分隔的语法出现歧义,Python3只支持这一种语法。
try:
value = collection[key]
except KeyError:
return key_not_found(key)
else:
return handle_value(value)123456不推荐:
try:
# Too broad!
return handle_value(collection[key])
except KeyError:
# Will also catch KeyError raised by handle_value()
return key_not_found(key)123456with conn.begin_transaction():
do_stuff_in_transaction(conn)12不推荐:
with conn:
do_stuff_in_transaction(conn)12第二个例子没有提供任何信息去指明__enter__和__exit__方法在事务之后做出了关闭连接之外的其他事情。这种情况下,明确指明非常重要。
def foo(x):
if x >= 0:
return math.sqrt(x)
else:
return None
def bar(x):
if x < 0:
return None
return math.sqrt(x)12345678910不推荐:
def foo(x):
if x >= 0:
return math.sqrt(x)
def bar(x):
if x < 0:
return
return math.sqrt(x)12345678推荐: if foo.startswith('bar'):
糟糕: if foo[:3] == 'bar':12正确: if isinstance(obj, int):
糟糕: if type(obj) is type(1):123当检查一个对象是否为string类型时,记住,它也有可能是unicode string!在Python2中,str和unicode都有相同的基类:basestring,所以你可以这样:
if isinstance(obj, basestring):1注意,在Python3中,unicode和basestring都不存在了(只有str)并且bytes类型的对象不再是string类型的一种(它是整数序列)
正确: if not seq:
if seq:
糟糕: if len(seq):
if not len(seq):12345正确: if greeting:
糟糕: if greeting == True:
更糟: if greeting is True:123随着PEP 484的引入,功能型注释的风格规范有些变化。
# type: ignore1这会告诉检查器忽略所有的注释。(在 PEP 484中可以找到从类型检查器禁用投诉的更细粒度的方法。)
标签:c语言实现 标记 double 资源 trail getattr 数学 驼峰命名 维护
原文地址:https://www.cnblogs.com/wanshizidiao/p/11111979.html