标签:权限 err 配置环境 文件中 issues database tar 第三方 pat
开发调试spark程序时,因为要访问开启kerberos认证的hive/hbase/hdfs等组件,每次调试都需要打jar包,上传到服务器执行特别影响工作效率,所以调研了下如何在windows环境用idea直接跑spark任务的方法,本文旨在记录配置本地调试环境中遇到的问题及解决方案。
Jdk 1.8.0
Spark 2.1.0
Scala 2.11.8
Hadoop 2.6.0-cdh5.12.1
Hive 1.1.0-cdh5.12.1
环境搭建略,直接看本地调试spark程序遇到的问题。
注意:若要访问远端hadoop集群服务,需将hosts配置到windows本地。
测试主类,功能spark sql读取开启Kerberos认证的远端hive数据
import org.apache.spark.sql.SparkSession
object SparkTest{
def main(args: Array[String]): Unit = {
//kerberos认证
initKerberos()
val spark = SparkSession.builder().master("local[2]").appName("SparkTest")
.enableHiveSupport()
.getOrCreate()
spark.sql("show databases").show()
spark.sql("use testdb")
spark.sql("show tables").show()
val sql = "select * from infodata.sq_dim_balance where dt=20180625 limit 10"
spark.sql(sql).show()
spark.stop()
}
def initKerberos(): Unit ={
//kerberos权限认证
val path = RiskControlUtil.getClass.getClassLoader.getResource("").getPath
val principal = PropertiesUtil.getProperty("kerberos.principal")
val keytab = PropertiesUtil.getProperty("kerberos.keytab")
val conf = new Configuration
System.setProperty("java.security.krb5.conf", path + "krb5.conf")
conf.addResource(new Path(path + "hbase-site.xml"))
conf.addResource(new Path(path + "hdfs-site.xml"))
conf.addResource(new Path(path + "hive-site.xml"))
conf.set("hadoop.security.authentication", "Kerberos")
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem")
UserGroupInformation.setConfiguration(conf)
UserGroupInformation.loginUserFromKeytab(principal, path + keytab)
println("login user: "+UserGroupInformation.getLoginUser())
}
}java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.winutils.exe是在Windows系统上需要的hadoop调试环境工具,里面包含一些在Windows系统下调试hadoop、spark所需要的基本的工具类
出现上面的问题,可能是因为windows环境下缺少winutils.exe文件或者版本不兼容的原因。
解决办法:
(1)下载winutils,注意需要与hadoop的版本相对应。
hadoop2.6版本可以在这里下载https://github.com/amihalik/hadoop-common-2.6.0-bin
由于配置的测试集群是hadoop2.6,所以我在这里下载的是2.6.0版本的。下载后,将其解压,包括:hadoop.dll和winutils.exe
(2)配置环境变量
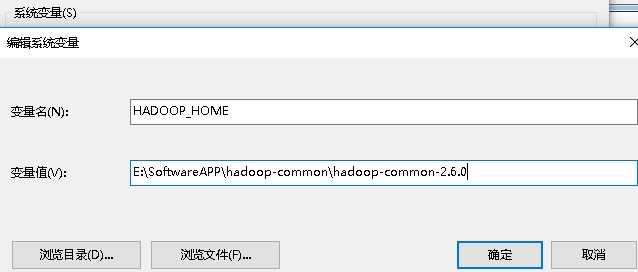
①增加系统变量HADOOP_HOME,值是下载的zip包解压的目录,我这里解压后将其重命名为hadoop-common-2.6.0
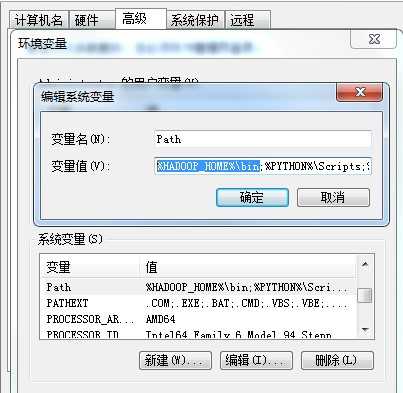
②在系统变量path里增加%HADOOP_HOME%\bin
③重启电脑,使环境变量配置生效,上述问题即可解决。
添加系统变量HADOOP_HOME
编辑系统变量Path,添加%HADOOP_HOME%\bin;
如果hadoop集群开启了kerberos认证,本地调试也需要进行认证,否则会报权限错误;
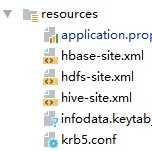
将权限相关配置文件放入工程的resource目录,如下所示
认证代码如下:
def initKerberos(): Unit ={
//kerberos权限认证
val path = RiskControlUtil.getClass.getClassLoader.getResource("").getPath
val principal = PropertiesUtil.getProperty("kerberos.principal")
val keytab = PropertiesUtil.getProperty("kerberos.keytab")
val conf = new Configuration
System.setProperty("java.security.krb5.conf", path + "krb5.conf")
conf.addResource(new Path(path + "hbase-site.xml"))
conf.addResource(new Path(path + "hdfs-site.xml"))
conf.addResource(new Path(path + "hive-site.xml"))
conf.set("hadoop.security.authentication", "Kerberos")
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem")
UserGroupInformation.setConfiguration(conf)
UserGroupInformation.loginUserFromKeytab(principal, path + keytab)
println("login user: "+UserGroupInformation.getLoginUser())
}Caused by: java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V网上说目前错误的解决办法还没有解决,采用一种临时的方式来解决,解决的办法是:通过下载你的CDH的版本的源码(http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.12.1-src.tar.gz),
在对应的文件下,hadoop2.6.0-cdh5.12.1-src\hadoop-common-project\hadoop- common\src\main\java\org\apache\hadoop\io\nativeio下NativeIO.java 复制到对应的Eclipse的project(复制的过程中需要注意一点,就是在当前的工程下创建相同的包路径,这里的包路径org.apache.hadoop.io.nativeio再将对应NativeIO.java文件复制到对应的包路径下即可。)
Windows的唯一方法用于检查当前进程的请求,在给定的路径的访问权限,所以我们先给以能进行访问,我们自己先修改源代码,return true 时允许访问。修改NativeIO.java文件中的557行的代码,如下所示:
源代码如下:
public static boolean access(String path, AccessRight desiredAccess)
throws IOException {
return access0(path, desiredAccess.accessRight());
}修改后的代码如下:
public static boolean access(String path, AccessRight desiredAccess)
throws IOException {
return true;
//return access0(path, desiredAccess.accessRight());
}再次执行,这个错误修复。
Caused by: java.io.FileNotFoundException: File /tmp/hive does not exist这个错误是说临时目录/tmp/hive需要有全部权限,即777权限,创建/tmp/hive 目录,用winutils.exe对目录赋权,如下
C:\>D:\spark_hadoop\hadoop-common\hadoop-common-2.6.0\bin\winutils.exe chmod -R 777 D:\tmp\hive
C:\>D:\spark_hadoop\hadoop-common\hadoop-common-2.6.0\bin\winutils.exe chmod -R 777 \tmp\hiveException in thread "main" java.lang.NoSuchFieldError: METASTORE_CLIENT_SOCKET_LIFETIMEOR
Exception in thread "main" java.lang.IllegalArgumentException: Unable to instantiate SparkSession with Hive support because Hive classes are not found原因是spark sql 读取hive元数据需要的字段METASTORE_CLIENT_SOCKET_LIFETIME hive1.2.0开始才有,而我们引用的cdh版本的hive为1.1.0-cdh5.12.1,没有该字段,故报错。
Spark SQL when configured with a Hive version lower than 1.2.0 throws a java.lang.NoSuchFieldError for the field METASTORE_CLIENT_SOCKET_LIFETIME because this field was introduced in Hive 1.2.0 so its not possible to use Hive metastore version lower than 1.2.0 with Spark. The details of the Hive changes can be found here: https://issues.apache.org/jira/browse/HIVE-9508解决方法,引入第三方依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.0</version>
</dependency>Exception in thread "main" java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.ql.security.authorization.StorageBasedAuthorizationProvider,org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory解决方法,将window idea引入的hive-site.xml进行如下修改
<!--<property>-->
<!--<name>hive.security.authorization.manager</name>-->
<!--<value>org.apache.hadoop.hive.ql.security.authorization.StorageBasedAuthorizationProvider,org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory</value>-->
<!--</property>-->
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.hadoop.hive.ql.security.authorization.DefaultHiveAuthorizationProvider</value>
</property>总结重要的几点就是:
(1) 配置HADOOP_HOME,内带winutils.exe 和 hadoop.dll 工具;
(2) 引入hive-site.xml等配置文件,开发kerberos认证逻辑;
(3) 本地重写NativeIO.java类;
(4) 给临时目录/tmp/hive赋予777权限;
(5) 引入第三方依赖spark-hive_2.11,要与spark版本对应;
(6) 本地hive-site.xml将hive.security.authorization.manager改为默认manager
最后提醒一点,本地调试只是问了开发阶段提高效率,避免每次修改都要打包提交到服务器运行,但调试完,还是要打包到服务器环境运行测试,没问题才能上线。
至此,spark本地调试程序配置完成,以后就可以愉快地在本地调试spark on hadoop程序了。
https://abgoswam.wordpress.com/2016/09/16/getting-started-with-spark-on-windows-10-part-2/
spark 2.x在windows环境使用idea本地调试启动了kerberos认证的hive
标签:权限 err 配置环境 文件中 issues database tar 第三方 pat
原文地址:https://www.cnblogs.com/xiaodf/p/11115843.html