标签:恢复 ane 需要 自动 body publish zh-cn alt author
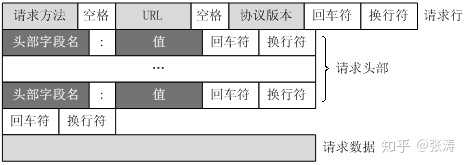
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:
**请求行(request line)、请求头部(header)、空行
和请求数据四个部分组成。**
GET /562f25980001b1b106000338.jpg HTTP/1.1
Host img.mukewang.com
User-Agent Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept image/webp,image/*,*/*;q=0.8 Referer http://www.imooc.com/ Accept-Encoding gzip, deflate, sdch
Accept-Language zh-CN,zh;q=0.8
空行---------------------------------第一部分:请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本.
GET说明请求类型为GET,[/562f25980001b1b106000338.jpg]为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。
第二部分:请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息
从第二行起为请求头部,HOST将指出请求的目的地.User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等
第三部分:空行,请求头部后面的空行是必须的
即使第四部分的请求数据为空,也必须有空行。
第四部分:请求数据也叫主体,可以添加任意的其他数据。
这个例子的请求数据为空。
POST / HTTP1.1
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley第一部分:请求行,第一行明了是post请求,以及http1.1版本。
第二部分:请求头部,第二行至第六行。
第三部分:空行,第七行的空行。
第四部分:请求数据,第八行。
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
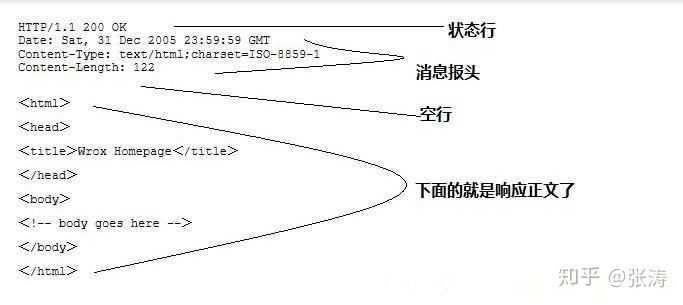
例子
HTTP/1.1 200 OK
Date: Fri, 22 May 2009 06:07:21 GMT
Content-Type: text/html;
charset=UTF-8
<html> <head></head> <body> <!--body goes here--> </body> </html>第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)
第二部分:消息报头,用来说明客户端要使用的一些附加信息
第二行和第三行为消息报头,
Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8
第三部分:空行,消息报头后面的空行是必须的
第四部分:响应正文,服务器返回给客户端的文本信息。
空行后面的html部分为响应正文。
Date: Fri, 22 May 2009 06:07:21 GMT Content-Type: text/html; charset=UTF-8
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
常见状态码:
会话跟踪常用方法:
我们知道 HTTP 协议采用“请求-应答”模式,当使用普通模式,即非 Keep-Alive 模式时,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接(HTTP协议为无连接的协议);当使用 Keep-Alive 模式(又称持久连接、连接重用)时,Keep-Alive 功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive 功能避免了建立或者重新建立连接。
在 HTTP 1.0 版本中,并没有官方的标准来规定 Keep-Alive 如何工作,因此实际上它是被附加到 HTTP 1.0协议上,如果客户端浏览器支持 Keep-Alive ,那么就在HTTP请求头中添加一个字段 Connection: Keep-Alive,当服务器收到附带有 Connection: Keep-Alive 的请求时,它也会在响应头中添加一个同样的字段来使用 Keep-Alive 。这样一来,客户端和服务器之间的HTTP连接就会被保持,不会断开(超过 Keep-Alive 规定的时间,意外断电等情况除外),当客户端发送另外一个请求时,就使用这条已经建立的连接。
在 HTTP 1.1 版本中,默认情况下所有连接都被保持,如果加入 "Connection: close" 才关闭。目前大部分浏览器都使用 HTTP 1.1 协议,也就是说默认都会发起 Keep-Alive 的连接请求了,所以是否能完成一个完整的 Keep-Alive 连接就看服务器设置情况。
由于 HTTP 1.0 没有官方的 Keep-Alive 规范,并且也已经基本被淘汰。
HTTP Keep-Alive 简单说就是保持当前的TCP连接,避免了重新建立连接。HTTP 是一个无状态无连接的协议,那么这是不是与 Keep-Alive 冲突?
HTTP 条件 GET 是 HTTP 协议为了减少不必要的带宽浪费,提出的一种方案:
下面是一个具体的发送接受报文示例:

第一次请求时,服务器端返回请求数据,之后的请求,服务器根据请求中的 If-Modified-Since 字段判断响应文件没有更新,如果没有更新,服务器返回一个 304 Not Modified响应,告诉浏览器请求的资源在浏览器上没有更新,可以使用已缓存的上次获取的文件。
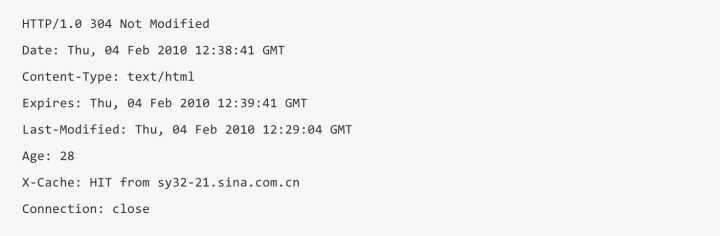
如果服务器端资源已经更新的话,就返回正常的响应。
标签:恢复 ane 需要 自动 body publish zh-cn alt author
原文地址:https://www.cnblogs.com/GaryZz/p/11130192.html