标签:集合 方便 线程 ati 具体步骤 eem array png mic
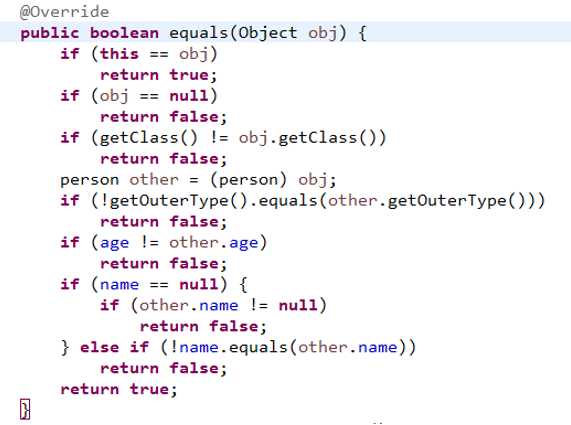
向集合添加自定义的对象,则一定要重写equals方法,
向set或map的key中添加自定义的对象,则一定要重写hashcode()方法。
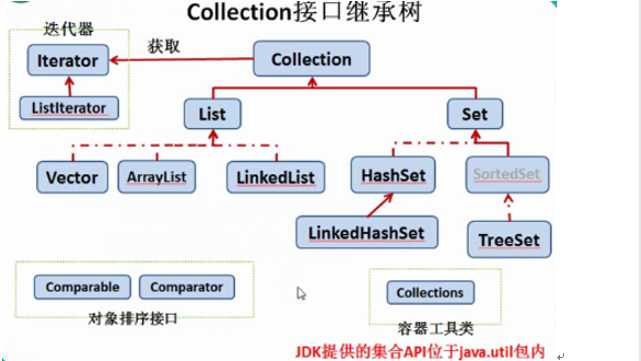
1.迭代器
接口 Iterator<E>
Iterator i=new Iterator ();
遍历解析:
首先i指向集合开头的上一个位置。调用hasNext()判断下一个位置是否为空,如果不为空则调用next() 将i指向下一个位置,并输出下一个位置上的值。
2.list:存储有序的 可以有重复值。
*添加进List集合中的元素或对象所在的类一定要重写equels()。如果指向同一个堆,可以用object的equels()达到删除目的,但如果是两个不同的堆,且是同一个类的实例对象,有着相同的属性,要想用remove删除,就要你重写的equels()来实现了。
(1) Arraylist 顺序链表,对于遍历很方便。
(2) linkedlist 单链表,对于平凡的插入与删除很快捷。
(3) vector 线性安全,什么是线程安全?
存储无序的!=随机的无序,真正的无序性是指元素在底层无序存储。不可重复的数据。
怎么实现数据的不重复性呢?
*添加进set集合中的元素或对象所在的类一定要重写equels()与hashCode()才能保证元素的不重复性。
Set中的元素如何存储的呢?使用了哈希算法
当向set中添加对象时,首先调用此对象所在类的hashCode()方法,计算此对象的哈希值,此哈希值确定了此对象在set中的存储位置。若此位置上没有值,则直接存入,如果此位置上有值,再调用equals()比较两个对象是否相同。如果相同,后一个值就不再添加。

(1) HashSet:可以添加null
(2) LinkedHashSet:使用链表维护了添加数据入集合的顺序。导致当我们遍历LinkedHashSet是,是按照添加进去的顺序遍历的。

(3) TreeSet:

1.向treeset中添加的元素必须是同一个类型的。
2. 可以按照添加进集合的元素的指定的遍历顺序遍历。String,包装类等默认按照从小到大的顺序遍历。
3.当向TreeSet中添加自定义的对象时,有两种排序方式:自然排序,定制排序。
4.自然排序:要求自定义的类实现java.lang.Comparable接口并重写其compareTo(obiect o)在此方法中,按照自定义类的哪个属性进行排序。
5.定制排序:跟自然排序差不多,只是重新写一个类来实现java.util.Comparator接口,并重写compare(Object o1, Object o2)方法。
具体步骤:
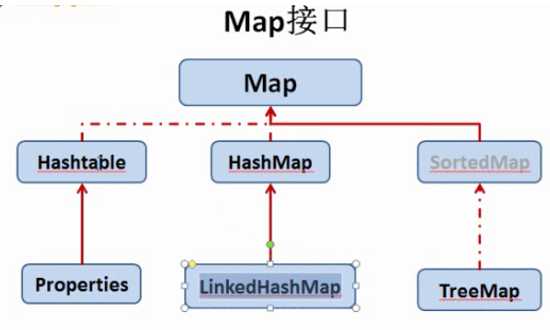
(1) HashMap:主要实现类,Key是用Set来存放的,不可重复。Value是用Collection来存放的,可重复。一对key—value,是一个Entry,所有的Entry是用set存放的,也是不可重复的。向hashMap中添加元素时,会调用Key所在类的equals()方法,判断两个Key是否相同,相同则会添加第二个元素。
常用方法:

(2)LinkedHashMap:使用链表维护添加进Map中的顺序,故遍历map时,是按添加进来的顺序遍历的。添加删除慢,但遍历快。
(1) TreeMap:按照添加进map中的元素的Key的指定属性进行排序。要求:Key必须是同一个类的对象!
针对Key的指定属性排序:
自然排序:实现Complareble接口且重写comparato()方法。如果有相同的就覆盖上去。
定制排序:跟自然排序差不多,只是重新写一个类来实现java.util.Comparator接口,并重写compare(Object o1, Object o2)方法。
标签:集合 方便 线程 ati 具体步骤 eem array png mic
原文地址:https://www.cnblogs.com/insist-bin/p/11143293.html