标签:struct 通过 有序 使用率 cpu 单点 ali 大数 sage
什么是Apache Storm
Apache Storm是一个分布式实时大数据处理系统。Storm设计用于在容错和水平可扩展方法中处理大量数据。它是一个流数据框架,具有最高的摄取率。虽然Storm是无状态的,它通过Apache ZooKeeper管理分布式环境和集群状态。通过Storm可以并行地对实时数据执行各种操作。Storm易于部署和操作,并且它可以保证每个消息将通过拓扑至少处理一次。
Apache Storm核心概念
Apache Storm从一端读取??实时数据的原始流,并将其传递通过一系列小处理单元,并在另一端输出处理/有用的信息。
下图描述了Apache Storm的核心概念。
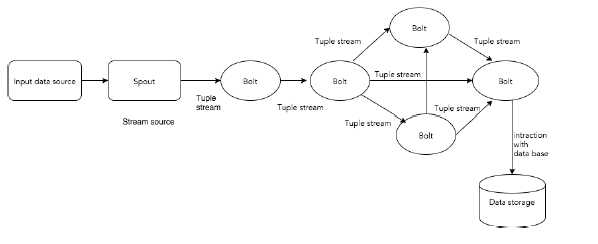
Apache Storm的组件
Tuple
Tuple是Storm中的主要数据结构。它是有序元素的列表。默认情况下,Tuple支持所有数据类型。通常,它被建模为一组逗号分隔的值,并传递到Storm集群。
Stream
流是元组的无序序列。
Spouts
流的源。通常,Storm从原始数据源(如Twitter Streaming API,Apache Kafka队列,Kestrel队列等)接受输入数据。否则,您可以编写spouts以从数据源读取数据。“ISpout”是实现spouts的核心接口,一些特定的接口是IRichSpout,BaseRichSpout,KafkaSpout等。
Bolts
Bolts是逻辑处理单元。Spouts将数据传递到Bolts和Bolts过程,并产生新的输出流。Bolts可以执行过滤,聚合,加入,与数据源和数据库交互的操作。Bolts接收数据并发射到一个或多个Bolts。 “IBolt”是实现Bolts的核心接口。一些常见的接口是IRichBolt,IBasicBolt等。
拓扑
Spouts和Bolts连接在一起,形成拓扑结构。实时应用程序逻辑在Storm拓扑中指定。简单地说,拓扑是有向图,其中顶点是计算,边缘是数据流。
简单拓扑从spouts开始。Spouts将数据发射到一个或多个Bolts。Bolt表示拓扑中具有最小处理逻辑的节点,并且Bolts的输出可以发射到另一个Bolts作为输入。
Storm保持拓扑始终运行,直到您终止拓扑。Apache Storm的主要工作是运行拓扑,并在给定时间运行任意数量的拓扑。
任务
现在你有一个关于Spouts和Bolts的基本想法。它们是拓扑的最小逻辑单元,并且使用单个Spout和Bolt阵列构建拓扑。应以特定顺序正确执行它们,以使拓扑成功运行。Storm执行的每个Spout和Bolt称为“任务”。简单来说,任务是Spouts或Bolts的执行。
进程
拓扑在多个工作节点上以分布式方式运行。Storm将所有工作节点上的任务均匀分布。工作节点的角色是监听作业,并在新作业到达时启动或停止进程。
流分组
数据流从Spouts流到Bolts,或从一个Bolts流到另一个Bolts。流分组控制元组在拓扑中的路由方式,并帮助我们了解拓扑中的元组流。有如下分组:
emit method in OutputCollector (which returns the task ids that the tuple was sent to).Apache Storm集群架构
Apache Storm的主要亮点是,它是一个容错,快速,没有“单点故障”(SPOF)分布式应用程序。我们可以根据需要在多个系统中安装Apache Storm,以增加应用程序的容量。
让我们看看Apache Storm集群如何设计和其内部架构。下图描述了集群设计。
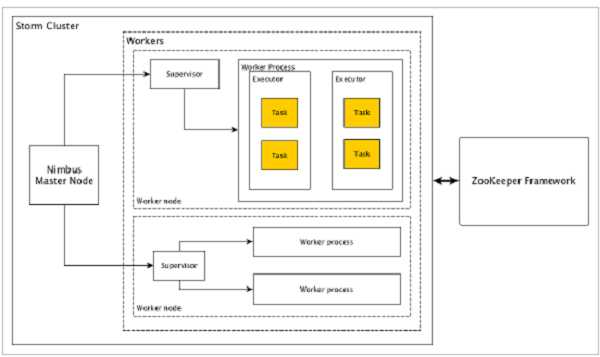
Apache Storm有两种类型的节点,Nimbus(主节点)和Supervisor(工作节点)。Nimbus是Apache Storm的核心组件。Nimbus的主要工作是运行Storm拓扑。Nimbus分析拓扑并收集要执行的任务。然后,它将任务分配给可用的supervisor。
Supervisor将有一个或多个工作进程。Supervisor将任务委派给工作进程。工作进程将根据需要产生尽可能多的执行器并运行任务。Apache Storm使用内部分布式消息传递系统来进行Nimbus和管理程序之间的通信。Storm广泛使用Thrift协议进行内部通信和数据定义。Storm拓扑只是Thrift Structs。在Apache Storm中运行拓扑的Storm Nimbus是一个Thrift服务。
Nimbus(主节点)
Nimbus是Storm集群的主节点。集群中的所有其他节点称为工作节点。主节点负责在所有工作节点之间分发数据,向工作节点分配任务和监视故障。
Supervisor(工作节点)
遵循指令的节点被称为Supervisors。Supervisor有多个工作进程,它管理工作进程以完成由nimbus分配的任务。
Worker process(工作进程)
工作进程将执行与特定拓扑相关的任务。工作进程不会自己运行任务,而是创建执行者(Executor)并要求他们执行特定的任务。工作进程将有多个执行者。
Executor(执行者)
执行者只是工作进程产生的单个线程。执行者运行一个或多个任务,但仅用于特定的spout或bolt。
Task(任务)
任务执行实际的数据处理。所以,它是一个spout或bolt。
ZooKeeper framework(ZooKeeper框架)
Apache的ZooKeeper的是使用群集(节点组)自己和维护具有强大的同步技术共享数据之间进行协调的服务。Nimbus是无状态的,所以它依赖于ZooKeeper来监视工作节点的状态。
ZooKeeper帮助supervisor与nimbus交互,它负责维持nimbus,supervisor的状态。
Storm是无状态的。即使无状态性质有它自己的缺点,它实际上帮助Storm以最好的可能和最快的方式处理实时数据。
Storm虽然不是完全无状态的。它将其状态存储在Apache ZooKeeper中。由于状态在Apache ZooKeeper中可用,故障的网络可以重新启动,并从它离开的地方工作。通常,像monitor这样的服务监视工具将监视Nimbus,并在出现任何故障时重新启动它。
Apache Storm工作流程
一个工作的Storm集群应该有一个Nimbus和一个或多个supervisors。另一个重要的节点是Apache ZooKeeper,它将用于nimbus和supervisors之间的协调。
现在让我们仔细看看Apache Storm的工作流程 −
默认情况下,Storm集群中有两种模式:
Storm使用经验分享
1.使用组件的并行度代替线程池或额外的线程
Storm自身是一个分布式、多线程的框架,对每个Spout和Bolt,我们都可以设置其并发度;它也支持通过rebalance命令来动态调整并发度,把负载分摊到多个Worker上。
如果自己在组件内部采用线程池做一些计算密集型的任务,比如JSON解析,有可能使得某些组件的资源消耗特别高,其他组件又很低,导致Worker之间资源消耗不均衡,这种情况在组件并行度比较低的时候更明显。
比如某个Bolt设置了1个并行度,但在Bolt中又启动了线程池,这样导致的一种后果就是,集群中分配了这个Bolt的Worker进程可能会把机器的资源都给消耗光了,影响到其他Topology在这台机器上的任务的运行。如果真有计算密集型的任务,我们可以把组件的并发度设大,Worker的数量也相应提高,让计算分配到多个节点上。
为了避免某个Topology的某些组件把整个机器的资源都消耗光的情况,除了不在组件内部启动线程池来做计算以外,也可以通过CGroup控制每个Worker的资源使用量。
不要在组件内部使用使用额外的线程,比如启动了额外的线程或Timer去处理逻辑,Storm并不保证额外的线程中处理数据的线程安全。
2.不要用DRPC批量处理大数据
RPC提供了应用程序和Storm Topology之间交互的接口,可供其他应用直接调用,使用Storm的并发性来处理数据,然后将结果返回给调用的客户端。这种方式在数据量不大的情况下,通常不会有问题,而当需要处理批量大数据的时候,问题就比较明显了。
(1)处理数据的Topology在超时之前可能无法返回计算的结果。
(2)批量处理数据,可能使得集群的负载短暂偏高,处理完毕后,又降低回来,负载均衡性差。
批量处理大数据不是Storm设计的初衷,Storm考虑的是时效性和批量之间的均衡,更多地看中前者。需要准实时地处理大数据量,可以考虑Spark等批量框架。
3.不要在Spout中处理耗时的操作
Spout中nextTuple方法会发射数据流,在启用Ack的情况下,fail方法和ack方法会被触发。需要明确一点,在Storm中Spout是单线程(JStorm的Spout分了3个线程,分别执行nextTuple方法、fail方法和ack方法)。如果nextTuple方法非常耗时,某个消息被成功执行完毕后,Acker会给Spout发送消息,Spout若无法及时消费,可能造成ACK消息超时后被丢弃,然后Spout反而认为这个消息执行失败了,造成逻辑错误。反之若fail方法或者ack方法的操作耗时较多,则会影响Spout发射数据的量,造成Topology吞吐量降低。
4.注意fieldsGrouping的数据均衡性
fieldsGrouping是根据一个或者多个Field对数据进行分组,不同的目标Task收到不同的数据,而同一个Task收到的数据会相同。假设某个Bolt根据用户ID对数据进行fieldsGrouping,如果某一些用户的数据特别多,而另外一些用户的数据又比较少,那么就可能使得下一级处理Bolt收到的数据不均衡,整个处理的性能就会受制于某些数据量大的节点。可以加入更多的分组条件或者更换分组策略,使得数据具有均衡性。
5.优先使用localOrShuffleGrouping
localOrShuffleGrouping是指如果目标Bolt中的一个或者多个Task和当前产生数据的Task在同一个Worker进程里面,那么就走内部的线程间通信,将Tuple直接发给在当前Worker进程的目的Task。否则,同shuffleGrouping。
localOrShuffleGrouping的数据传输性能优于shuffleGrouping,因为在Worker内部传输,只需要通过Disruptor队列就可以完成,没有网络开销和序列化开销。因此在数据处理的复杂度不高,而网络开销和序列化开销占主要地位的情况下,可以优先使用localOrShuffleGrouping来代替shuffleGrouping。
6.设置合理的MaxSpoutPending值
在启用Ack的情况下,Spout中有个RotatingMap用来保存Spout已经发送出去,但还没有等到Ack结果的消息。RotatingMap的最大个数是有限制的,为p*num-tasks。其中p是topology.max.spout.pending值,也就是MaxSpoutPending(也可以由TopologyBuilder在setSpout通过setMaxSpoutPending方法来设定),num-tasks是Spout的Task数。如果不设置MaxSpoutPending的大小或者设置得太大,可能消耗掉过多的内存导致内存溢出,设置太小则会影响Spout发射Tuple的速度。
7.设置合理的Worker数
Worker数越多,性能越好?并不是!
这是由于一方面,每新增加一个Worker进程,都会将一些原本线程间的内存通信变为进程间的网络通信,这些进程间的网络通信还需要进行序列化与反序列化操作,这些降低了吞吐率。
另一方面,每新增加一个Worker进程,都会额外地增加多个线程(Netty发送和接收线程、心跳线程、System Bolt线程以及其他系统组件对应的线程等),这些线程切换消耗了不少CPU,sys 系统CPU消耗占比增加,在CPU总使用率受限的情况下,降低了业务线程的使用效率。
8.平衡吞吐量和时效性
Storm的数据传输默认使用Netty。在数据传输性能方面,有如下的参数可以调整:
storm.messaging.netty.server_worker_threads和storm.messaging.netty.client_worker_threads分别为接收消息线程和发送消息线程的数量。
netty.transfer.batch.size是指每次 Netty Client向 Netty Server发送的数据的大小,如果需要发送的Tuple消息大于netty.transfer.batch.size,则Tuple消息会按照netty.transfer.batch.size进行切分,然后多次发送。
storm.messaging.netty.buffer_size为每次批量发送的Tuple序列化之后的TaskMessage消息的大小。
storm.messaging.netty.flush.check.interval.ms表示当有TaskMessage需要发送的时候, Netty Client检查可以发送数据的频率。降低storm.messaging.netty.flush.check.interval.ms的值,可以提高时效性。增加netty.transfer.batch.size和storm.messaging.netty.buffer_size的值,可以提升网络传输的吐吞量,使得网络的有效载荷提升(减少TCP包的数量,并且TCP包中的有效数据量增加),通常时效性就会降低一些。因此需要根据自身的业务情况,合理在吞吐量和时效性直接的平衡。
除了这些参数,我们怎么找到Storm中性能的瓶颈,可以通过如下的一些途径来进行:
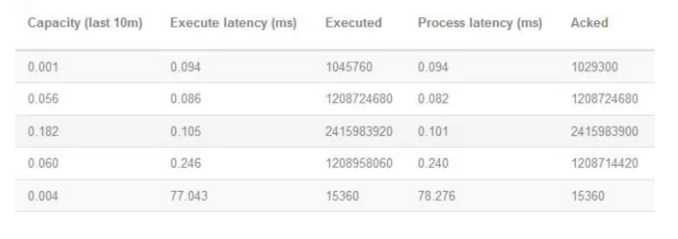
在Storm的UI中,对每个Topology都提供了相应的统计信息,其中有3个参数对性能来说参考意义比较明显,包括Execute latency、Process latency和Capacity。
分别看一下这3个参数的含义和作用。
(1)Execute latency:消息的平均处理时间,单位为毫秒。
(2)Process latency:消息从收到到被ack掉所花的时间,单位为毫秒。如果没有启用Acker机制,那么Process latency的值为0。
(3)Capacity:计算公式为Capacity = Bolt或者Executor调用execute方法处理的消息数量 * 消息平均执行时间 / 时间区间。这个值越接近1,说明Bolt或者Executor基本一直在调用execute方法,因此并行度不够,需要扩展这个组件的Executor数量。
为了在Storm中达到高性能,我们在设计和开发Topology的时候,需要注意以下原则:
(1)模块和模块之间解耦,模块之间的层次清晰,每个模块可以独立扩展,并且符合流水线的原则。
(2)无状态设计,无锁设计,水平扩展支持。
(3)为了达到高的吞吐量,延迟会加大;为了低延迟,吞吐量可能降低,需要在二者之间平衡。
(4)性能的瓶颈永远在热点,解决热点问题。
(5)优化的前提是测量,而不是主观臆测。收集相关数据,再动手,事半功倍。
参考:
https://www.w3cschool.cn/apache_storm/apache_storm_introduction.html
https://zhuanlan.zhihu.com/p/20504669
http://storm.apache.org/index.html
标签:struct 通过 有序 使用率 cpu 单点 ali 大数 sage
原文地址:https://www.cnblogs.com/luxiaoxun/p/11146109.html