标签:默认参数 次数 mil list pow 指标 its str min
经典段子——“啤酒与尿布”,即很多年轻父亲在购买孩子尿布的时候,顺便为自己购买啤酒。关联分析中,最经典的算法Apriori算法在关联规则分析领域具有很大的影响力。
这是一个集合的概念,每个事件即一个项,如啤酒是一个项,尿布是一个项,若干项的集合称为项集,如{尿布,啤酒}是一个二元项集。
关联规则一般记为 \(X\rightarrow Y\) 的形式,X称为先决条件,右侧为相应的关联结果,用于表示出数据内隐含的关联性。如:关联规则 尿布 \(\rightarrow\) 啤酒成立,则表示购买尿布的消费者往往会购买啤酒,即两个商品的购买之间具有一定的关联性。
关联性的强度,由关联分析中的三个核心概念——支持度、置信度和提升度来控制和评价。
以例子说明:假设有10000个消费者,购买尿布的有1000人,购买啤酒的有2000人,购买面包的有500人,其中同时购买了尿布和啤酒的有800人,同时购买了尿布和面包的有100人。
支持度(Support)指在所有项集中{X,Y}出现的可能性,即项集中同时包含X和Y的概率,。
我们通过设定一个最小阈值来判断关联是否有意义,当概率大于或等于该最小阈值时有意义(有关联)。
在上面例子中P{尿布,啤酒} = 800/10000=8%,P{尿布,面包} = 100/10000=1%。我们设定最小阈值5%,即大于5%说明有关联。则尿布和啤酒有关联,而尿布和面包无关联。
置信度(Confidence)表示,在关联规则的先决条件X发生的条件下,关联结果Y发生的概率 \(P(Y|X)=\frac{P(XY)}{P(X)}\) 。
相似的我们也需要设定一个最小阈值,来判断概率关联是否有意义
上述例子中,即在购买尿布后,购买啤酒的概率。P(啤酒|尿布) = (800/10000)/(1000/10000) = 800/1000=80%。而在购买啤酒后再去购买尿布的概率为P(尿布|啤酒)=(800/10000)/(2000/10000)=800/2000=40%。假设我们以70%作为最小阈值,即强相关规则:尿布 \(\rightarrow\) 啤酒
提升度(lift),表示在含有X的条件下同时含有Y的可能性与没有X的条件下项集中含有Y的可能性之比 \(\frac{P(Y|X)}{P(Y)}\) 。提升度可以看作是置信度的一种互补指标。
如1000个消费者,购买茶叶的500人,这500人中有450人同时购买了咖啡,则 P(咖啡|茶叶) = (450/1000)/(500/1000)=450/500=90%,很高的置信度。而另外500个没有购买茶叶的人中,也有450人购买了咖啡,即1000人中有900人购买了咖啡。则P(咖啡|未购买茶叶)=(450/1000)/(500/1000)=450/500=90%。同样也是90%的置信度,所以购买咖啡和与购买茶叶之间,无关联相互独立。其提升度 \(\frac{P(咖啡|茶叶)}{P(咖啡)} = \frac{90\%}{900/1000} = 1\) 。同样的,上面例子中,\(\frac{P(啤酒|尿布)}{P(啤酒)} = \frac{80\%}{2000/10000} = 4\) 。
当提升度的值为1时表示X和Y相互独立,X对Y的发生没有提升作用。提升度的值>1时,且提升度值越大,表示X对Y的发生的提升作用越大,即关联性越大。
R中有两个专用于关联分析的包—— arules 和 arulesViz
apriori(data, parameter = NULL, appearance = NULL, control = NULL)参数:
arules包中的inspect函数以可读形式显示关联规则和事务型数据,这里我们查看该事务数据中的前10条数据
library(arules) # 导入arules包
data("Groceries") # 导入arules包中的Groceries数据集
inspect(Groceries[1:10])
# 结果,可以看到每次交易的相信情况
items
[1] {citrus fruit,semi-finished bread,margarine,ready soups}
[2] {tropical fruit,yogurt,coffee}
[3] {whole milk}
[4] {pip fruit,yogurt,cream cheese ,meat spreads}
[5] {other vegetables,whole milk,condensed milk,long life bakery product}
[6] {whole milk,butter,yogurt,rice,abrasive cleaner}
[7] {rolls/buns}
[8] {other vegetables,UHT-milk,rolls/buns,bottled beer,liquor (appetizer)}
[9] {pot plants}
[10] {whole milk,cereals}summary(Groceries) # 查看Groceries数据集基本信息结果:
transactions as itemMatrix in sparse format with
9835 rows (elements/itemsets/transactions) and
169 columns (items) and a density of 0.02609146
most frequent items:
whole milk other vegetables rolls/buns soda yogurt (Other)
2513 1903 1809 1715 1372 34055
element (itemset/transaction) length distribution:
sizes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 26 27
2159 1643 1299 1005 855 645 545 438 350 246 182 117 78 77 55 46 29 14 14 9 11 4 6 1 1 1
28 29 32
1 3 1
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 2.000 3.000 4.409 6.000 32.000
includes extended item information - examples:
labels level2 level1
1 frankfurter sausage meat and sausage
2 sausage sausage meat and sausage
3 liver loaf sausage meat and sausage结果解读:
arules包中的image函数可以可视化itemmatrix,即商品(169列),交易9835行构成的矩阵。该矩阵为稀疏矩阵,即元素为0(单次交易中未被购买的商品)远远多于1,且1分布不规律。选取Groceries数据集中的前10条作图
image(Groceries[1:10])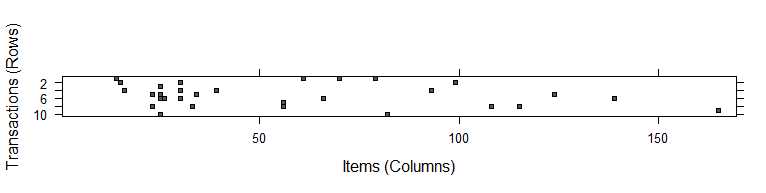
arules包中的itemFrequencyPlot函数可以画出item的频率图,以卖出频率最高的前20种商品作图
itemFrequencyPlot(Groceries,topN = 20)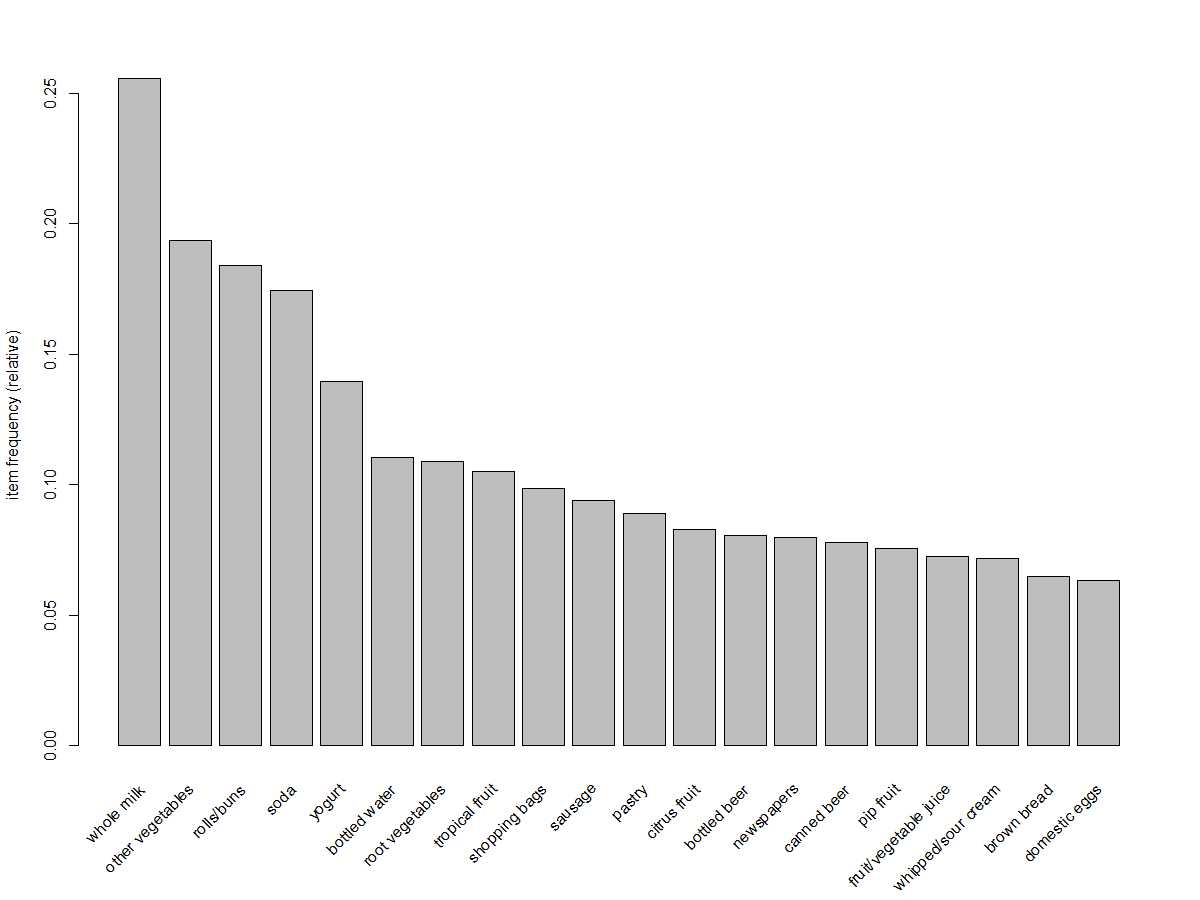
arules包中的apriori函数,可以实现Apriori算法,生成符合条件的关联规则
rules1 <- apriori(Groceries) # 使用默认参数,即最小支持度0.1,最小置信度0.8...
summary(rules1) # 结果:set of 0 rules,即没有符合该条件的关联规则调整参数,生成符合为最小支持度(minsup):0.001,最小置信度(mincon):0.5的关联规则。函数在生成关联规则时,还将输出函数生成关联规则时的各个细节。
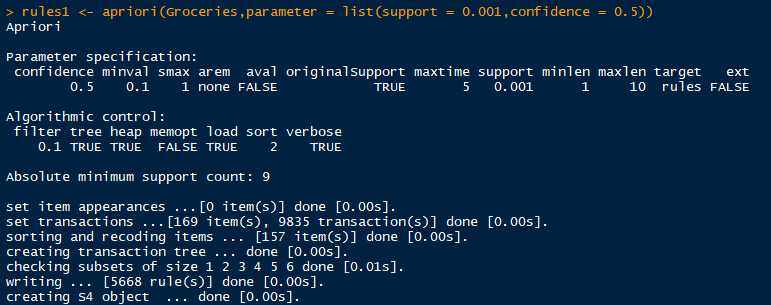
查看生成的规则的基本情况
summary(rules1)
# 结果:
set of 5668 rules # 总共生成了5668条关联规则
rule length distribution (lhs + rhs):sizes # 关联规则item频数分布,lhs个数+rhs个数为3的规则有11条。这个用inspect函数查看生成的规则就特别明了
2 3 4 5 6
11 1461 3211 939 46
Min. 1st Qu. Median Mean 3rd Qu. Max. # lhs个数+rhs个数的和最小为2,最大为6
2.00 3.00 4.00 3.92 4.00 6.00
summary of quality measures: # 生成的关联规则中支持度、置信度、提升度等信息
support confidence lift count
Min. :0.001017 Min. :0.5000 Min. : 1.957 Min. : 10.0
1st Qu.:0.001118 1st Qu.:0.5455 1st Qu.: 2.464 1st Qu.: 11.0
Median :0.001322 Median :0.6000 Median : 2.899 Median : 13.0
Mean :0.001668 Mean :0.6250 Mean : 3.262 Mean : 16.4
3rd Qu.:0.001729 3rd Qu.:0.6842 3rd Qu.: 3.691 3rd Qu.: 17.0
Max. :0.022267 Max. :1.0000 Max. :18.996 Max. :219.0
mining info:
data ntransactions support confidence
Groceries 9835 0.001 0.5查看生成的规则中的前20条规则
inspect(rules1[1:20])
# 结果
lhs rhs support confidence lift count
[1] {honey} => {whole milk} 0.001118454 0.7333333 2.870009 11
[2] {tidbits} => {rolls/buns} 0.001220132 0.5217391 2.836542 12
[3] {cocoa drinks} => {whole milk} 0.001321810 0.5909091 2.312611 13
[4] {pudding powder} => {whole milk} 0.001321810 0.5652174 2.212062 13
[5] {cooking chocolate} => {whole milk} 0.001321810 0.5200000 2.035097 13
[6] {cereals} => {whole milk} 0.003660397 0.6428571 2.515917 36
[7] {jam} => {whole milk} 0.002948653 0.5471698 2.141431 29
[8] {specialty cheese} => {other vegetables} 0.004270463 0.5000000 2.584078 42
[9] {rice} => {other vegetables} 0.003965430 0.5200000 2.687441 39
[10] {rice} => {whole milk} 0.004677173 0.6133333 2.400371 46
[11] {baking powder} => {whole milk} 0.009252669 0.5229885 2.046793 91
[12] {liver loaf,yogurt} => {whole milk} 0.001016777 0.6666667 2.609099 10
[13] {tropical fruit,curd cheese} => {other vegetables} 0.001016777 0.6666667 3.445437 10
[14] {curd cheese,rolls/buns} => {whole milk} 0.001016777 0.6250000 2.446031 10
[15] {other vegetables,curd cheese} => {whole milk} 0.001220132 0.5714286 2.236371 12
[16] {whole milk,curd cheese} => {other vegetables} 0.001220132 0.5217391 2.696429 12
[17] {other vegetables,cleaner} => {whole milk} 0.001016777 0.6250000 2.446031 10
[18] {liquor,red/blush wine} => {bottled beer} 0.001931876 0.9047619 11.235269 19
[19] {soda,liquor} => {bottled beer} 0.001220132 0.5714286 7.095960 12
[20] {curd,cereals} => {whole milk} 0.001016777 0.9090909 3.557863 10 因为生成的关联规则太多了,所以可以通过调整参数,如提高支持度(减少频繁项集的数量)/置信度(规则本身的可靠度)。这些参数调整过程:阈值调整太低,生成的关联规则数量会特别大。阈值调整太高,将会丢失一些有意义的关联规则。
rules1 <- apriori(Groceries,parameter = list(support = 0.005,confidence = 0.64)) # 提高minsup和mincon,只剩下4条满足条件的关联规则
inspect(rules1)
# 结果:
lhs rhs support confidence lift count
[1] {butter,whipped/sour cream} => {whole milk} 0.006710727 0.6600000 2.583008 66
[2] {pip fruit,whipped/sour cream} => {whole milk} 0.005998983 0.6483516 2.537421 59
[3] {pip fruit,root vegetables,other vegetables} => {whole milk} 0.005490595 0.6750000 2.641713 54
[4] {tropical fruit,root vegetables,yogurt} => {whole milk} 0.005693950 0.7000000 2.739554 56 标签:默认参数 次数 mil list pow 指标 its str min
原文地址:https://www.cnblogs.com/sakura-d/p/11150656.html