标签:star 搭建 做了 com UNC targe 备份还原 异常 日志
本文基于伪分布式搭建 hadoop+zookeeper+hbase+opentsdb之后,文章链接:https://www.cnblogs.com/yybrhr/p/11128149.html,对于Hbase数据备份和恢复的几种方法已经有很多大神说明了很多(https://www.cnblogs.com/ballwql/p/hbase_data_transfer.html对hbase迁移数据的4种机制都做了说明),我就不做过多描述。本文主要实战Export 本地备份还原opentsdb数据,以及数据的迁移。
opentsdb在hbase中生成4个表(tsdb, tsdb-meta, tsdb-tree, tsdb-uid),其中tsdb这个表最重要,数据迁移时,备份还原此表即可。
本文测试本地备份服务器hostname:hbase3,ip为192.168.0.214。
# 备份表:tsdb,本地存放路径/opt/soft/hbase/hbase_bak/hbase_bak_1562252298 hbase org.apache.hadoop.hbase.mapreduce.Export -Dhbase.export.scanner.batch=2000 -D mapred.output.compress=true tsdb file:///opt/soft/hbase/hbase_bak/hbase_bak_1562252298
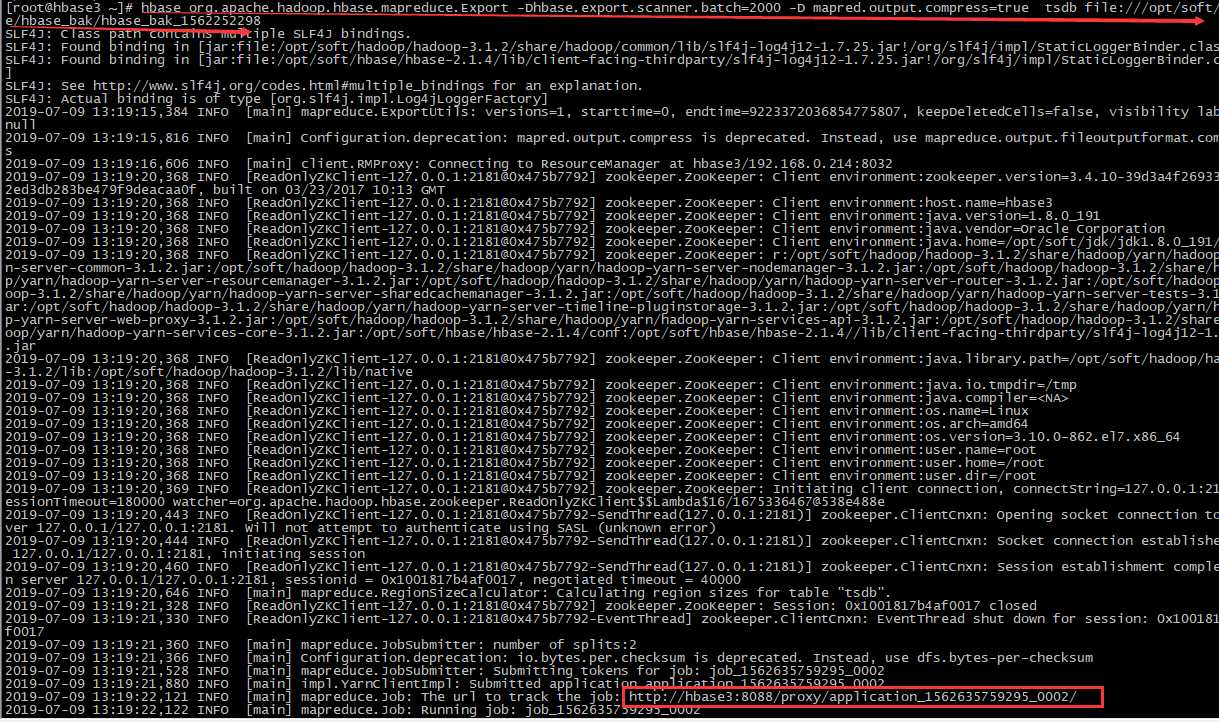
#根据提示:可以通过 http://hbase3:8088 跟踪进度
http://hbase3:8088
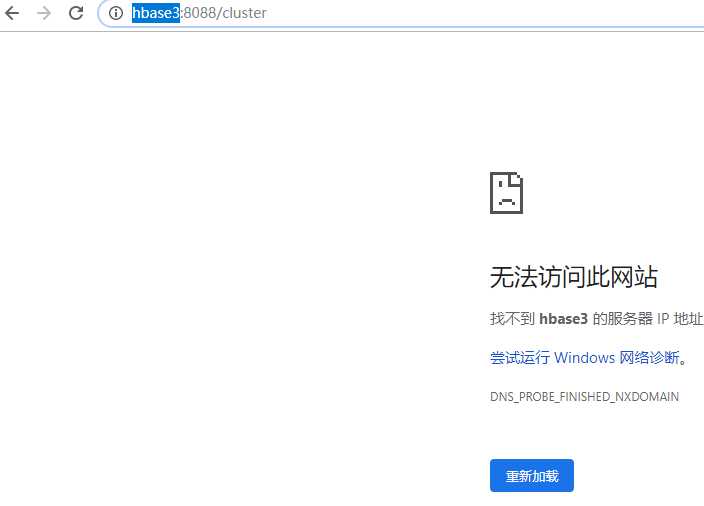
#问题:但是无法访问 http://hbase3:8088,但http://192.168.0.214:8088/cluster则访问
http://192.168.0.214:8088
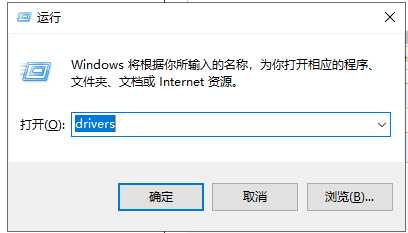
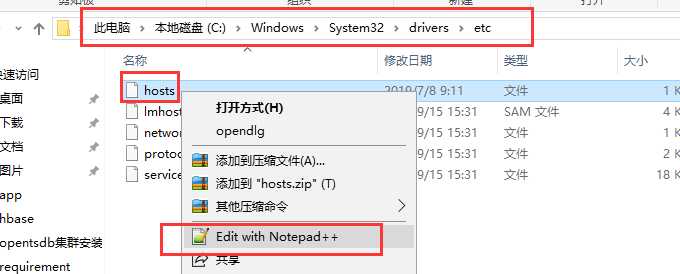
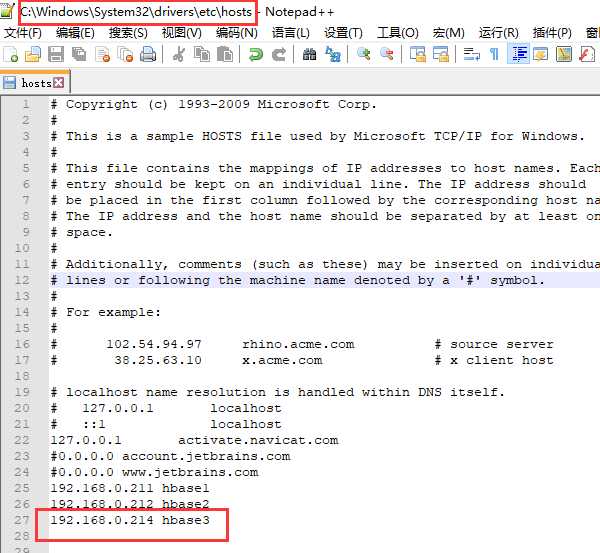
#解决:配置hosts,映射hbase3(WIN+R——>输入:drivers——>进入子路径:/etc/hosts——>添加 192.168.0.214 hbase3)
192.168.0.214 hbase3
# 问题
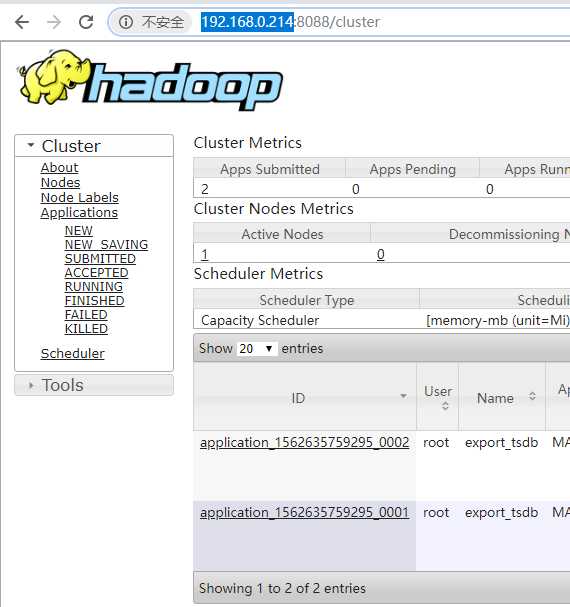
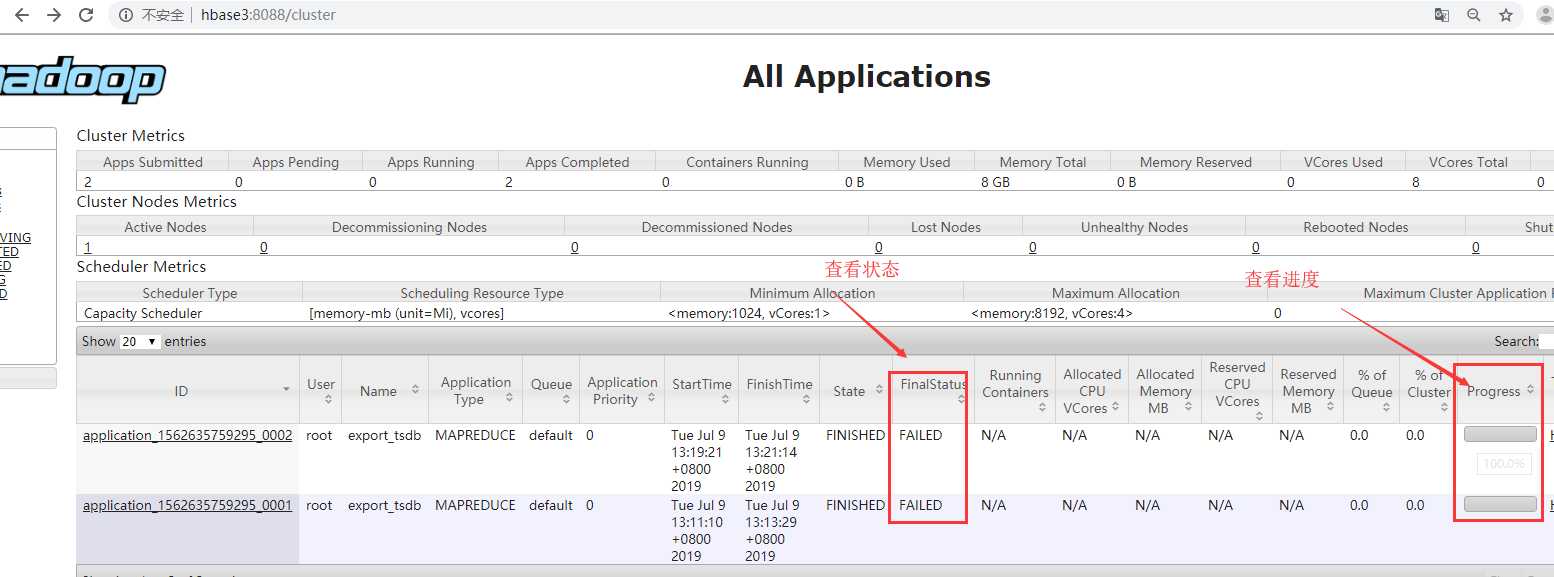
# 解決:状态与进度跟踪
# 验证
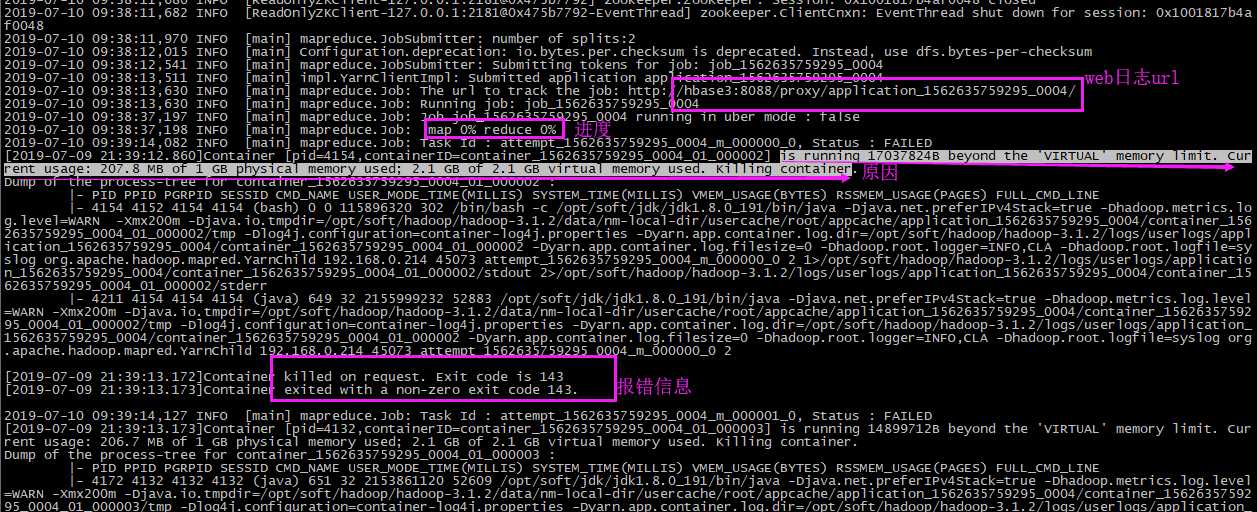
is running 17037824B beyond the ‘VIRTUAL‘ memory limit. Current usage: 207.8 MB of 1 GB physical memory used; 2.1 GB of 2.1 GB virtual memory used. Killing container
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
后台日志:提示可以在web上查看
web日志:
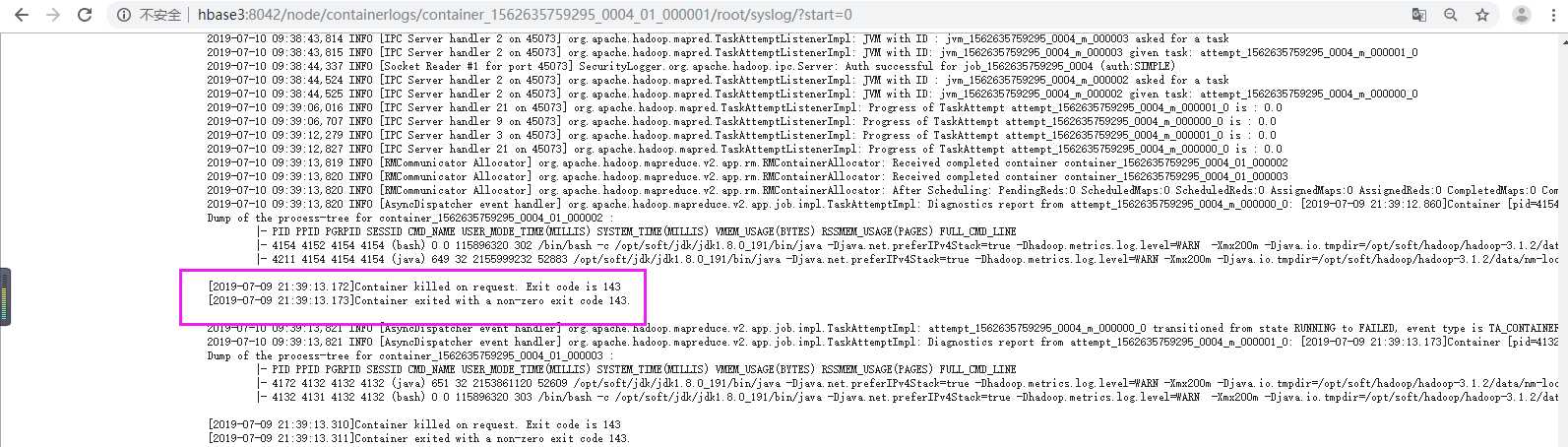
我们在后台日志可以看到,is running 17037824B beyond the ‘VIRTUAL‘ memory limit. Current usage: 207.8 MB of 1 GB physical memory used; 2.1 GB of 2.1 GB virtual memory used. Killing container.这句话其实就告诉了原因:
207.8 MB: 任务所占的物理内存
1 GB : 是hadoop的mapred-site.xml配置文件中设置的mapreduce.map.memory.mb 的值。
2.1 GB : 第一个2.1GB是程序占用的虚拟内存
2.1 GB : 是hadoop的mapred-site.xml配置文件中设置的mapreduce.map.memory.mb 的值 乘以 yarn.nodemanager.vmem-pmem-ratio 的值得到的。
其中yarn.nodemanager.vmem-pmem-ratio 是 虚拟内存和物理内存比例,在yarn-site.xml中设置,默认是2.1GB,
很明显,这句话的意思是:分配给container虚拟内存只有2.1GB,但是目前container已经占用了2.1GB。所以kill掉了这个container。
上面只是map中产生的报错,当然也有可能在reduce中报错,如果是reduce中,那么就是对应mapreduce.reduce.memory.mb 和 yarn.nodemanager.vmem-pmem-ratio。
参考网址:
https://blog.csdn.net/T1DMzks/article/details/78818874
https://www.cnblogs.com/missie/p/4370135.html
# 进入目录 cd /opt/soft/hadoop/hadoop-3.1.2/etc/hadoop/ # 进入编辑 vim mapred-site.xml # 添加以下内容 <!--任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1。--> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2048</value> </property>
# 添加重启hadoop、hbase:注意先停habse,并且不要要kill,因为hadoop在不断的切割,用stop停止,它会记录下来,下次启动继续切割
stop-hbase.sh
stop-all.sh
start-all.sh
start-hbase.sh
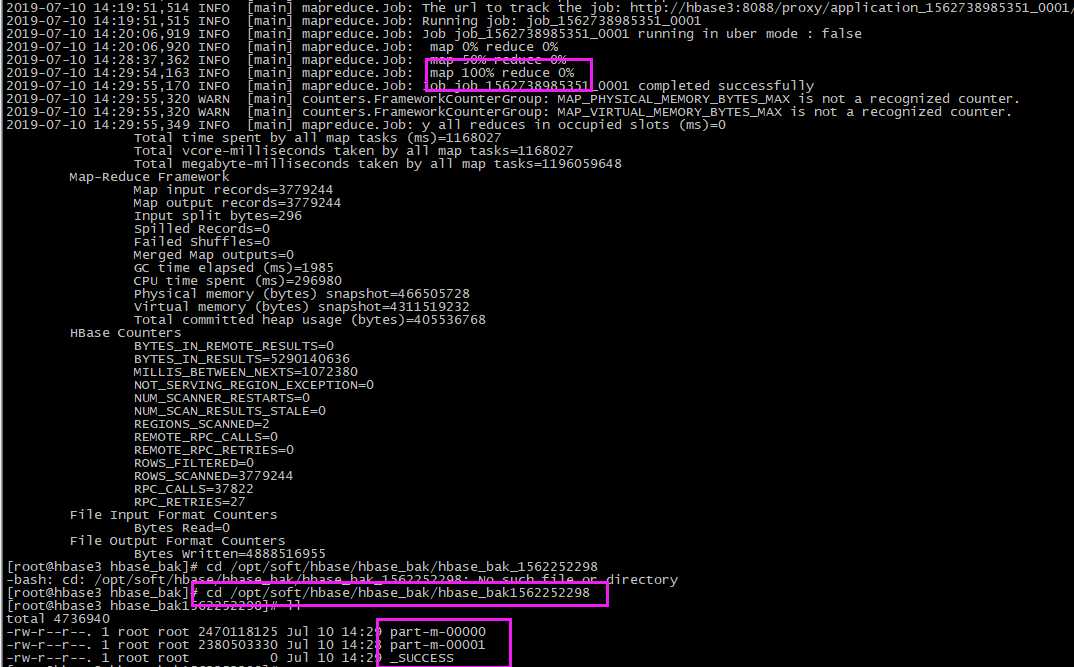
## 验证: # 1、先删除本地之前的备份文件 rm -fr /opt/soft/hbase/hbase_bak/hbase_bak1562252298 # 2、再次备份 hbase org.apache.hadoop.hbase.mapreduce.Export -Dhbase.export.scanner.batch=2000 -D mapred.output.compress=true tsdb file:///opt/soft/hbase/hbase_bak/hbase_bak1562252298 # 3、结果查看:进入备份文件路径查看内容(一般成功会生成_SUCCESS和若干part-m-文件) cd /opt/soft/hbase/hbase_bak/hbase_bak1562252298 ll
在web上可以查看进度和状态:
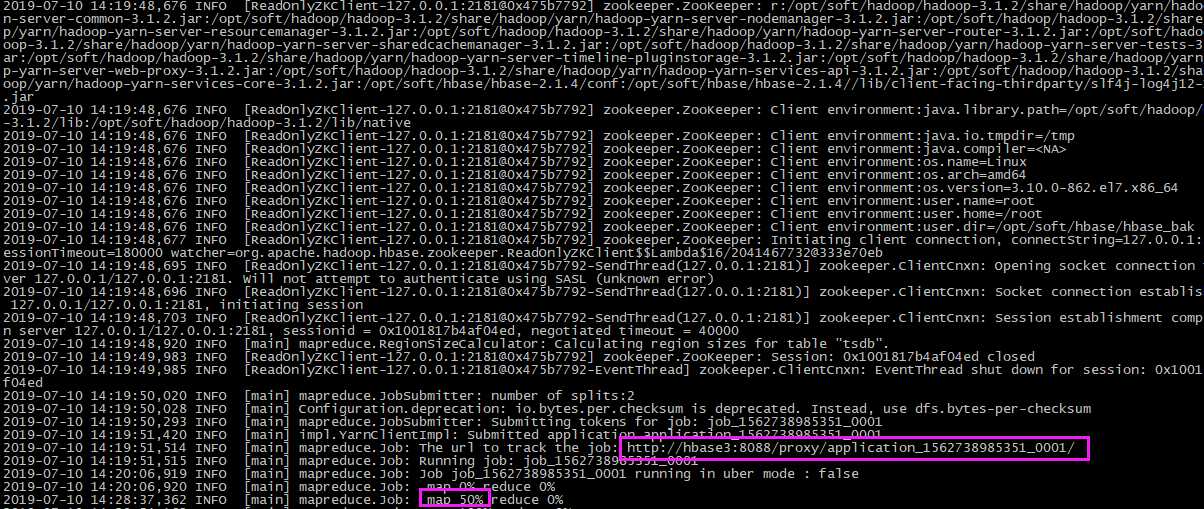

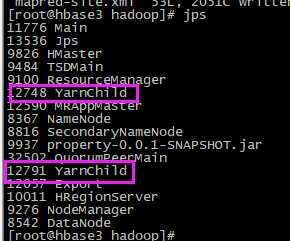
在运行的时候会生成两个YarnChild进程
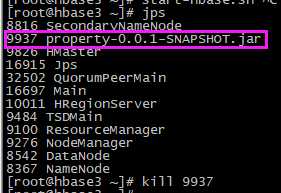
# 进入到shell命令 hbase shell # 清空要还原的表,只留表结构 truncate ‘tsdb‘ # 查看表 scan ‘tsdb‘
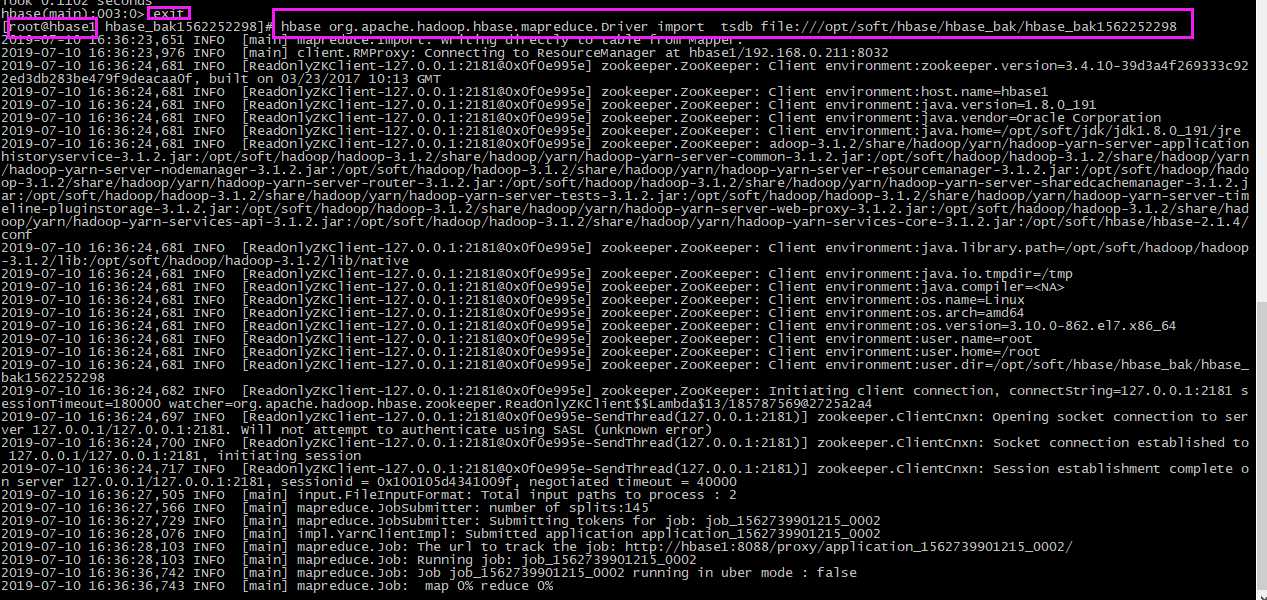
# 此步骤在非shell命令下执行,因此需要exit退出shell命令,我这里重开一个窗口做 hbase org.apache.hadoop.hbase.mapreduce.Driver import tsdb file:///opt/soft/hbase/hbase_bak/hbase_bak1562252298
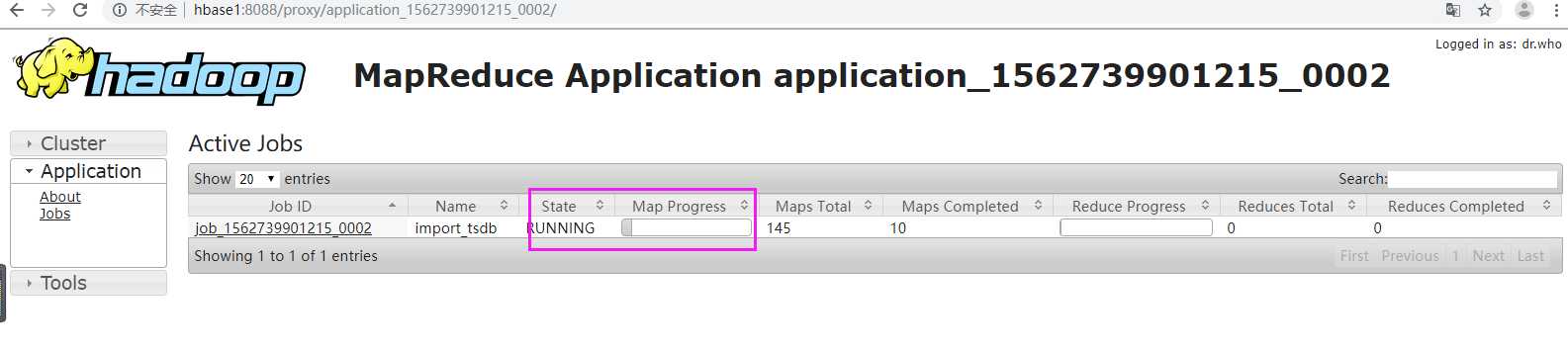
查看进度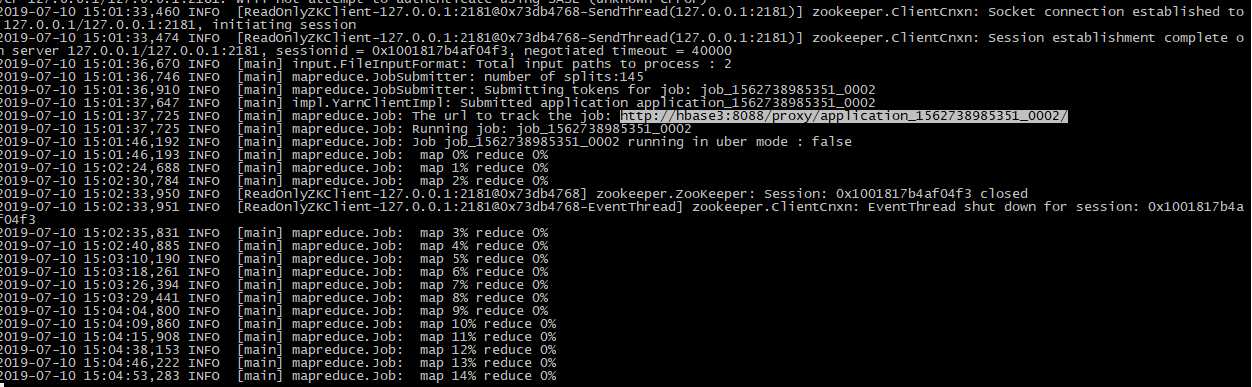

当进度达到100%时,检查数据。
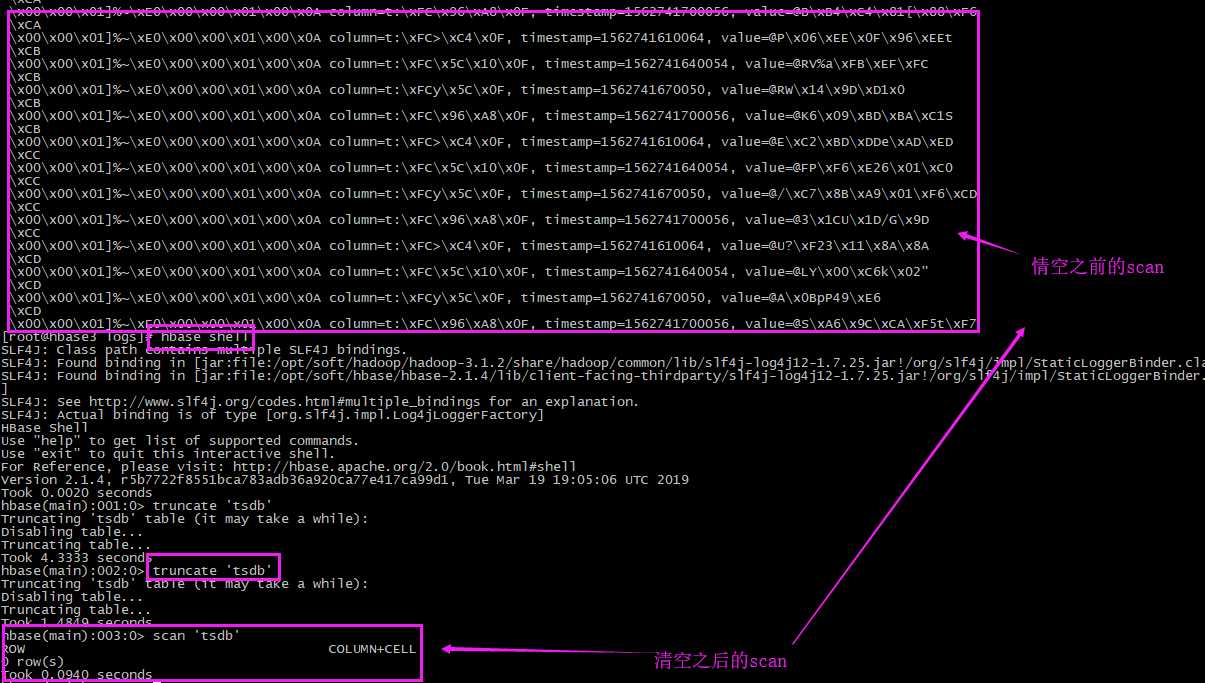
# 进入shell命令 hbase shell # 查看数据 scan ‘tsdb‘

本文从hbase3(ip:192.168.0.214)迁移到hbase1(ip:192.168.0.211),这两台服务器搭建的环境一样,并且做了互相免密登录。
scp -r hbase3:/opt/soft/hbase/hbase_bak/hbase_bak1562252298/ hbase1:/opt/soft/hbase/hbase_bak/
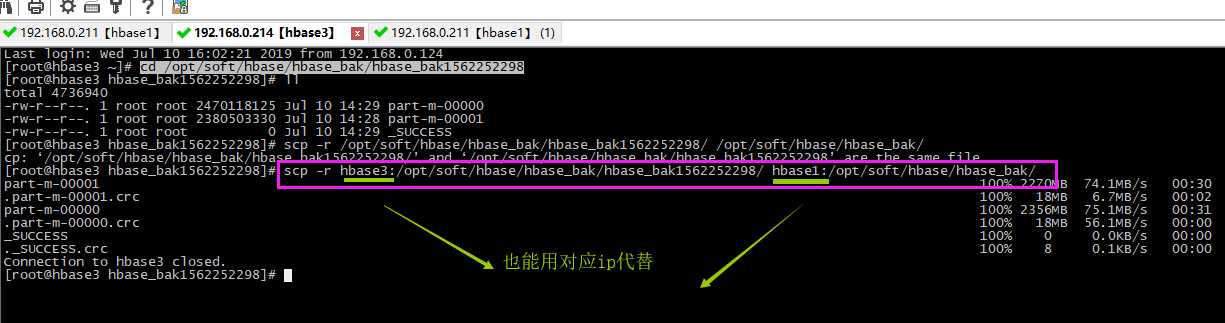
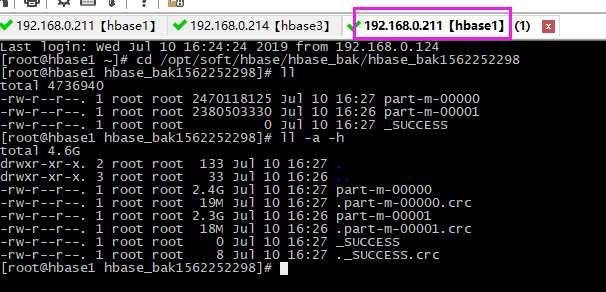
hbase1原本数据
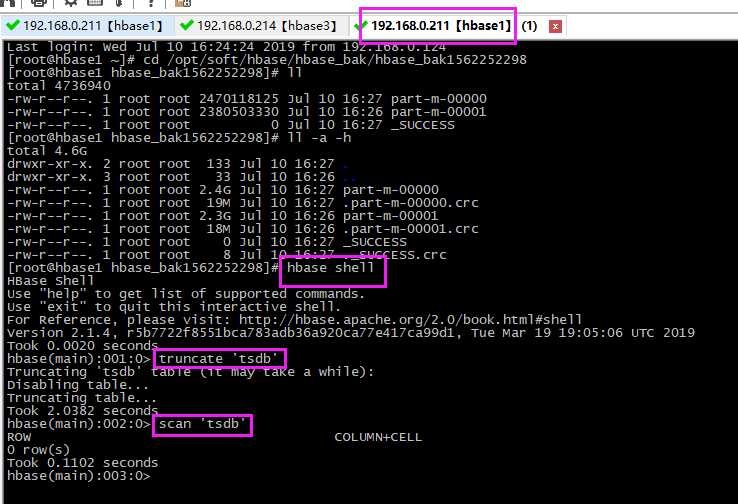
清空
# 进入到shell命令 hbase shell # 清空要还原的表,只留表结构 truncate ‘tsdb‘ # 查看表 scan ‘tsdb‘
增量备份跟全量备份操作差不多,只不过要在后面加上时间戳。需要借助时间戳转换工具http://tool.chinaz.com/Tools/unixtime.aspx。
开始时间:2019-07-10 00:00:00 对应时间戳:1562616000
结束时间:2019-07-10 14:00:00 对应时间戳:1562652000
hbase org.apache.hadoop.hbase.mapreduce.Export -Dhbase.export.scanner.batch=2000 -D mapred.output.compress=true tsdb file:///opt/soft/hbase/hbase_bak/hbase_bak_1562601600-1562652000 1562601600 1562652000
hbase备份还原opentsdb数据之Export/Import(增量+全量)
标签:star 搭建 做了 com UNC targe 备份还原 异常 日志
原文地址:https://www.cnblogs.com/yybrhr/p/11156792.html