标签:远程服务 nec 测试 lib 布尔 netcat 参数 sdn 数据源
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.atlxl</groupId> <artifactId>flink_class</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.11.8</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-core</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_2.11</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_2.11</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_2.11</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.1</version> </dependency> </dependencies> </project>
StreamExecutionEnvironment.getExecutionEnvironment
StreamExecutionEnvironment.createLocalEnvironment
StreamExecutionEnvironment.createRemoteEnvironment
val env = StreamExecutionEnvironment.getExecutionEnvironment
val env = StreamExecutionEnvironment.createLocalEnvironment(1)
val env = StreamExecutionEnvironment.createRemoteEnvironment(1)
val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.readTextFile("/opt/modules/test.txt") stream.print() env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment val path = new Path("/opt/modules/test.txt") val stream = env.readFile(new TextInputFormat(path), "/opt/modules/test.txt") stream.print() env.execute("FirstJob")
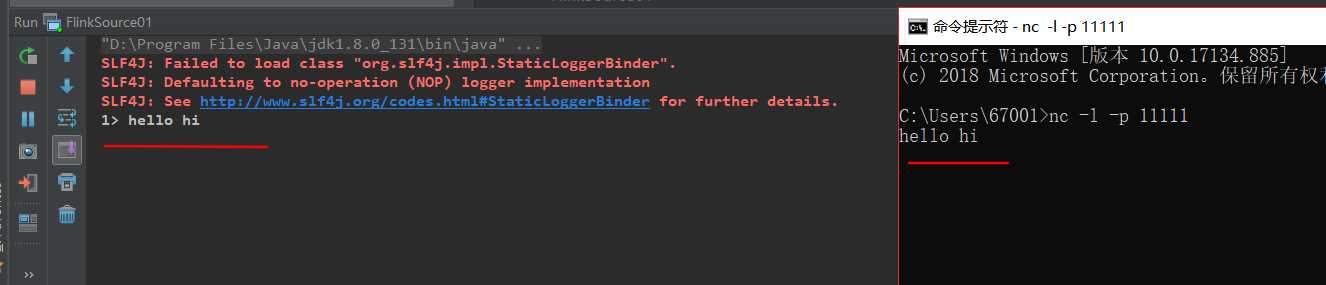
val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.socketTextStream("localhost", 11111) stream.print() env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment val list = List(1,2,3,4) val stream = env.fromCollection(list) stream.print() env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment val iterator = Iterator(1,2,3,4) val stream = env.fromCollection(iterator) stream.print() env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment val list = List(1,2,3,4) val stream = env.fromElement(list) stream.print() env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.generateSequence(1,10) stream.print() env.execute("FirstJob")
测试代码:
package source import org.apache.flink.streaming.api.scala._ object FlinkSource01 { def main(args: Array[String]): Unit = { //1. 创建环境 val env = StreamExecutionEnvironment.getExecutionEnvironment // //2. 获取数据源(Source) // val stream = env.readTextFile("test00.txt") // //基于 Socket 获取数据源 // val stream = env.socketTextStream("localhost", 11111) // //基于集合(Collection)的数据源 // val list = List(1,2,3,4) // val stream = env.fromCollection(list) fromCollection(seq) // val iterator = Iterator(1,2,3,4) // val stream = env.fromCollection(iterator) //fromCollection(Iterator) val stream = env.generateSequence(1,10) //generateSequence(from, to) //3. 打印数据(Sink) stream.print() //4. 执行任务 env.execute("FristJob") } }
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10) val streamMap = stream.map { x => x * 2 } streamFilter.print()
env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("test.txt") val streamFlatMap = stream.flatMap{ x => x.split(" ") } streamFilter.print()
env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10) val streamFilter = stream.filter{ x => x == 1 } streamFilter.print()
env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("test.txt")
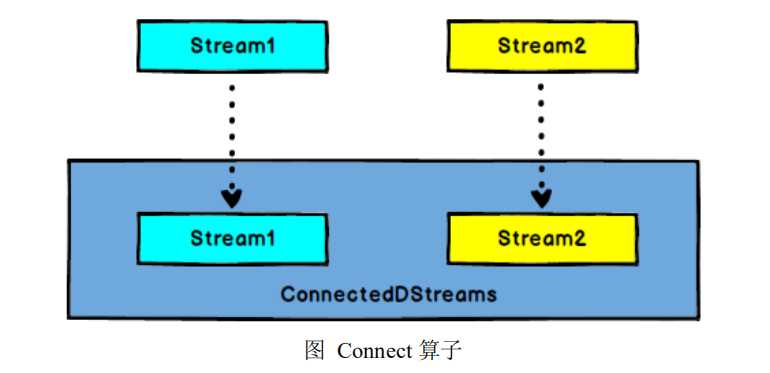
val streamMap = stream.flatMap(item => item.split(" ")).filter(item => item.equals("hadoop")) val streamCollect = env.fromCollection(List(1,2,3,4))
val streamConnect = streamMap.connect(streamCollect)
streamConnect.map(item=>println(item), item=>println(item))
env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment
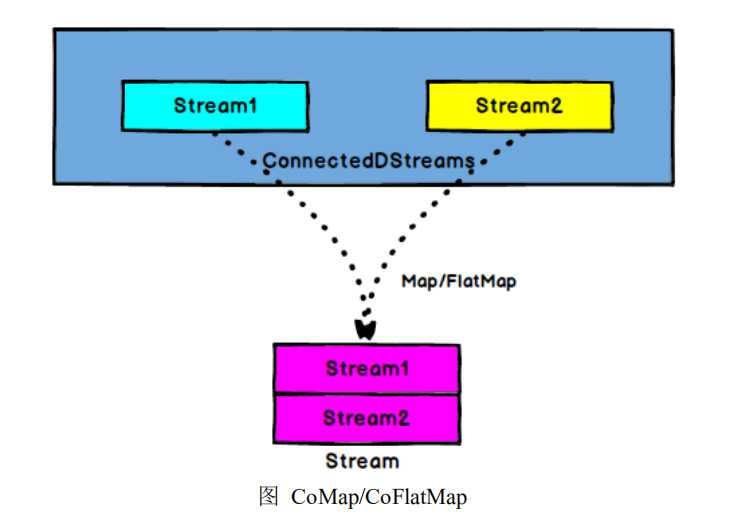
val stream1 = env.readTextFile("test.txt") val streamFlatMap = stream1.flatMap(x => x.split(" ")) val stream2 = env.fromCollection(List(1,2,3,4)) val streamConnect = streamFlatMap.connect(stream2) val streamCoMap = streamConnect.map( (str) => str + "connect", (in) => in + 100 )
env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1 = env.readTextFile("test.txt") val stream2 = env.readTextFile("test1.txt") val streamConnect = stream1.connect(stream2) val streamCoMap = streamConnect.flatMap( (str1) => str1.split(" "), (str2) => str2.split(" ") ) streamConnect.map(item=>println(item), item=>println(item))
env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment
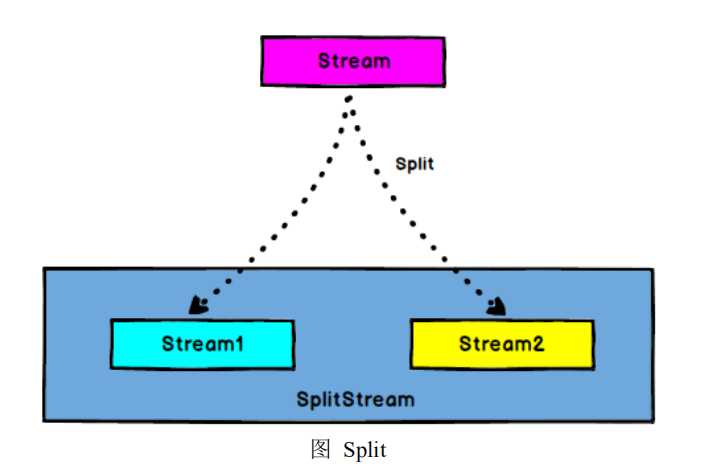
val stream = env.readTextFile("test.txt") val streamFlatMap = stream.flatMap(x => x.split(" ")) val streamSplit = streamFlatMap.split( num => # 字符串内容为 hadoop 的组成一个 DataStream,其余的组成一个 DataStream (num.equals("hadoop")) match{ case true => List("hadoop") case false => List("other") } )
env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment
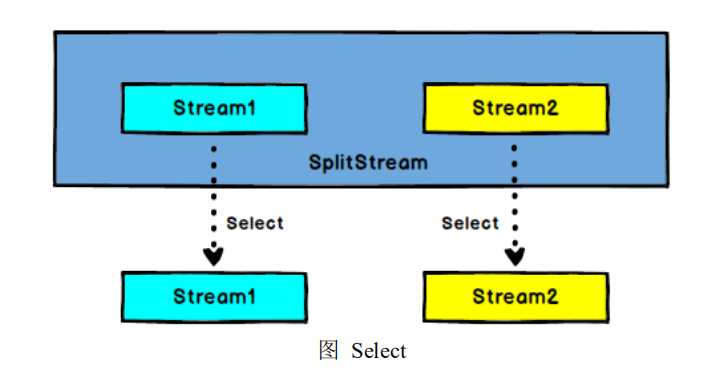
val stream = env.readTextFile("test.txt") val streamFlatMap = stream.flatMap(x => x.split(" ")) val streamSplit = streamFlatMap.split( num => (num.equals("hadoop")) match{ case true => List("hadoop") case false => List("other") } )
val hadoop = streamSplit.select("hadoop") val other = streamSplit.select("other") hadoop.print()
env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment
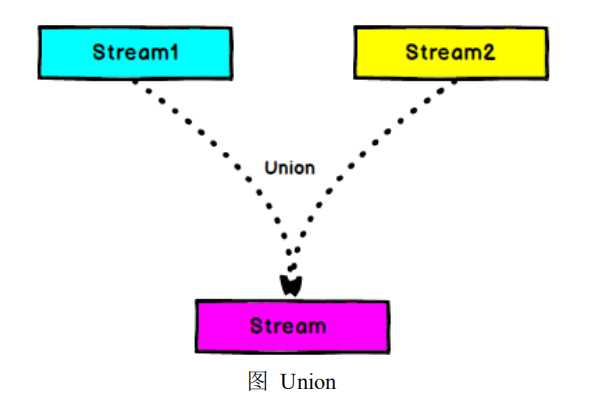
val stream1 = env.readTextFile("test.txt") val streamFlatMap1 = stream1.flatMap(x => x.split(" ")) val stream2 = env.readTextFile("test1.txt") val streamFlatMap2 = stream2.flatMap(x => x.split(" ")) val streamConnect = streamFlatMap1.union(streamFlatMap2)
env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.readTextFile("test.txt") val streamFlatMap = stream.flatMap{ x => x.split(" ") } val streamMap = streamFlatMap.map{ x => (x,1) } val streamKeyBy = streamMap.keyBy(0) env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("test.txt").flatMap(item => item.split(" ")).map(item => (item, 1)).keyBy(0)
val streamReduce = stream.reduce( (item1, item2) => (item1._1, item1._2 + item2._2) )
streamReduce.print()
env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("test.txt").flatMap(item => item.split(" ")).map(item => (item, 1)).keyBy(0) val streamReduce = stream.fold(100)( (begin, item) => (begin + item._2) ) streamReduce.print()
env.execute("FirstJob")
keyedStream.sum(0) keyedStream.sum("key") keyedStream.min(0) keyedStream.min("key") keyedStream.max(0) keyedStream.max("key") keyedStream.minBy(0) keyedStream.minBy("key") keyedStream.maxBy(0) keyedStream.maxBy("key")
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("test02.txt").map(item => (item.split(" ")(0), item.split(" ")(1).toLong)).keyBy(0)
val streamReduce = stream.sum(1)
streamReduce.print()
env.execute("FirstJob")
标签:远程服务 nec 测试 lib 布尔 netcat 参数 sdn 数据源
原文地址:https://www.cnblogs.com/LXL616/p/11179226.html