标签:电话号码 生成 strong keep 分析 大量 举例 记录 time
通信运营商每时每刻会产生大量的通信数据,例如通话记录,短信记录,彩信记录,
第三方服务资费等等繁多信息。数据量如此巨大,除了要满足用户的实时查询和展示之外,
还需要定时定期的对已有数据进行离线的分析处理。例如,当日话单,月度话单,季度话单,
年度话单,通话详情,通话记录等等+。我们以此为背景,寻找一个切入点,学习其中的方法论。
当前我们的需求是:统计每天、每月以及每年的每个人的通话次数及时长。
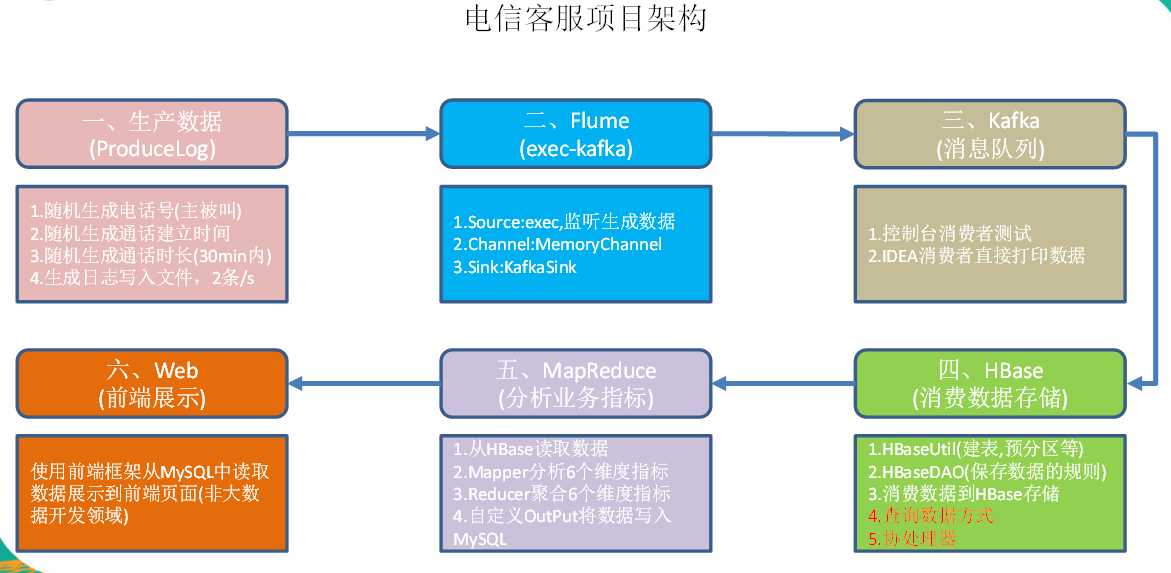
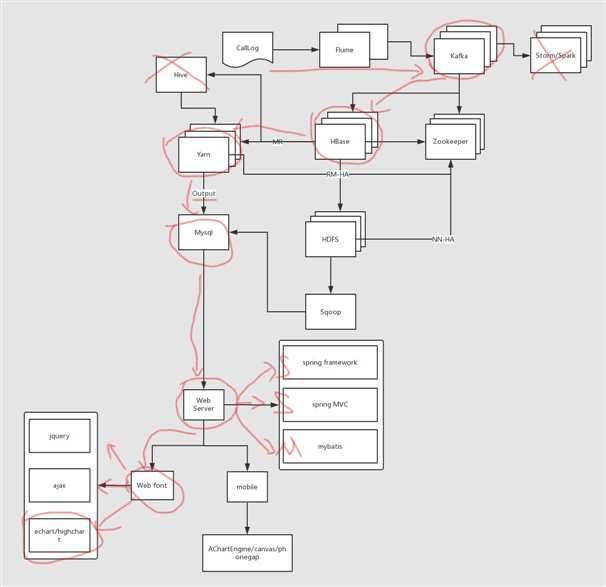
系统环境:
表1
|
系统 |
版本 |
|
windows |
10 专业版 |
|
linux |
CentOS 6.8 |
开发工具:
表2
|
工具 |
版本 |
|
idea |
2017.2.5旗舰版 |
|
maven |
3.3.9 |
|
JDK |
1.8+ |
提示:idea2017.2.5必须使用maven3.3.9,不要使用maven3.5,有部分兼容性问题
集群环境:
表3
|
框架 |
版本 |
|
hadoop |
2.7.2 |
|
zookeeper |
3.4.10 |
|
hbase |
1.3.1 |
|
flume |
1.7.0 |
|
kafka |
2.11-0.11.0.0 |
硬件环境:
表4
|
|
hadoop102 |
hadoop103 |
hadoop104 |
|
内存 |
4G |
2G |
2G |
|
CPU |
2核 |
1核 |
1核 |
|
硬盘 |
50G |
50G |
50G |
此情此景,对于该模块的业务,即数据生产过程,一般并不会让你来进行操作,
数据生产是一套完整且严密的体系,这样可以保证数据的鲁棒性。但是如果涉及到
项目的一体化方案的设计(数据的产生、存储、分析、展示),则必须清楚每一个
环节是如何处理的,包括其中每个环境可能隐藏的问题;数据结构,数据内容可能出现的问题。
我们将在HBase中存储两个电话号码,以及通话建立的时间和通话持续时间,
最后再加上一个flag作为判断第一个电话号码是否为主叫。
姓名字段的存储我们可以放置于另外一张表做关联查询,当然也可以插入到当前表中。
表5
|
列名 |
解释 |
举例 |
|
call1 |
第一个手机号码 |
15369468720 |
|
call1_name |
第一个手机号码人姓名(非必须) |
李雁 |
|
call2 |
第二个手机号码 |
19920860202 |
|
call2_name |
第二个手机号码人姓名(非必须) |
卫艺 |
|
date_time |
建立通话的时间 |
20171017081520 |
|
date_time_ts |
建立通话的时间(时间戳形式) |
|
|
duration |
通话持续时间(秒) |
0600 |
思路:
a) 创建Java集合类存放模拟的电话号码和联系人;
b) 随机选取两个手机号码当作“主叫”与“被叫”(注意判断两个手机号不能重复),产出call1与call2字段数据;
c) 创建随机生成通话建立时间的方法,可指定随机范围,最后生成通话建立时间,产出date_time字段数据;
d) 随机一个通话时长,单位:秒,产出duration字段数据;
e)、将产出的一条数据拼接封装到一个字符串中;
f)、使用IO操作将产出的一条通话数据写入到本地文件中;
新建module项目:ct_producer
标签:电话号码 生成 strong keep 分析 大量 举例 记录 time
原文地址:https://www.cnblogs.com/LXL616/p/11186443.html