标签:ict creat idt 简单 日期时间 讲解 分配 lse dha
Python第十六课(模块3) >>>思维导图>>>中二青年
模块与包
模块
""" 三种来源 1.内置的 2.第三方的 3.自定义的 四种表示形式 1.py文件(******) 2.共享库 3.文件夹(一系列模块的结合体)(******) 4.C++编译的连接到python内置的 """
导入模块
""" 先产生一个执行文件的名称空间 1.创建模块文件的名称空间 2.执行模块文件中的代码 将产生的名字放入模块的名称空间中 3.在执行文件中拿到一个指向模块名称空间的名字 """
什么是包
""" 什么是包? 它是一系列模块文件的结合体,表示形式就是一个文件夹 该文件夹内部通常会有一个__init__.py文件 包的本质还是一个模块 """
导入包
先产生一个执行文件的名称空间 1.创建包下面的__init__.py文件的名称空间 2.执行包下面的__init__.py文件中的代码 将产生的名字放入包下面的__init__.py文件名称空间中 3.在执行文件中拿到一个指向包下面的__init__.py文件名称空间的名字 在导入语句中 .号的左边肯定是一个包(文件夹)
当你作为包的设计者来说
1.当模块的功能特别多的情况下 应该分文件管理 2.每个模块之间为了避免后期模块改名的问题 你可以使用相对导入(包里面的文件都应该是被导入的模块) # 研究模块与包 还可以站另外两个角度分析不同的问题 # 1.模块的开发者 # 2.模块的使用者
研究模块与包还可以站另外两个角度分析不同的问题
1.站在包的开发者 如果使用绝对路径来管理的自己的模块 那么它只需要永远以包的路径为基准依次导入模块 2.站在包的使用者 你必须得将包所在的那个文件夹路径添加到system
注意
python2如果要导入包 包下面必须要有__init__.py文件
python3如果要导入包 包下面没有__init__.py文件也不会报错
当你在删程序不必要的文件的时候 千万不要随意删除__init__.py文件
相对导入与绝对导入
# 绝对导入: 以执行文件的sys.path为起始点开始导入,称之为绝对导入 # 优点: 执行文件与被导入的模块中都可以使用 # 缺点: 所有导入都是以sys.path为起始点,导入麻烦 # 相对导入: 参照当前所在文件的文件夹为起始开始查找,称之为相对导入 # 符号: .代表当前所在文件的文件加,..代表上一级文件夹,...代表上一级的上一级文件夹 # 优点: 导入更加简单 # 缺点: 只能在导入包中的模块时才能使用 #注意: 1. 相对导入只能用于包内部模块之间的相互导入,导入者与被导入者都必须存在于一个包内 2. attempted relative import beyond top-level package # 试图在顶级包之外使用相对导入是错误的,言外之意,必须在顶级包内使用相对导入,每增加一个.代表跳到上一级文件夹,而上一级不应该超出顶级包
logging模块(日志模块:记录)
日志级别
CRITICAL = 50 #FATAL = CRITICAL ERROR = 40 WARNING = 30 #WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0 #不设置
默认级别为warning,默认打印到终端
import logging logging.debug(‘调试debug‘) logging.info(‘消息info‘) logging.warning(‘警告warn‘) logging.error(‘错误error‘) logging.critical(‘严重critical‘) ‘‘‘ WARNING:root:警告warn ERROR:root:错误error CRITICAL:root:严重critical ‘‘‘
为logging模块指定全局配置,针对所有logger有效,控制打印到文件中

#======介绍 可在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有 filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息 #========使用 import logging logging.basicConfig(filename=‘access.log‘, format=‘%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s‘, datefmt=‘%Y-%m-%d %H:%M:%S %p‘, level=10) logging.debug(‘调试debug‘) logging.info(‘消息info‘) logging.warning(‘警告warn‘) logging.error(‘错误error‘) logging.critical(‘严重critical‘) #========结果 access.log内容: 2017-07-28 20:32:17 PM - root - DEBUG -test: 调试debug 2017-07-28 20:32:17 PM - root - INFO -test: 消息info 2017-07-28 20:32:17 PM - root - WARNING -test: 警告warn 2017-07-28 20:32:17 PM - root - ERROR -test: 错误error 2017-07-28 20:32:17 PM - root - CRITICAL -test: 严重critical part2: 可以为logging模块指定模块级的配置,即所有logger的配置
Formatter,Handler,Logger,Filter对象
#logger:产生日志的对象 #Filter:过滤日志的对象 #Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端 #Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式 ‘‘‘ critical=50 error =40 warning =30 info = 20 debug =10 ‘‘‘ import logging # 1.logger对象:负责产生日志 logger = logging.getLogger(‘转账记录‘) # 2.filter对象:过滤日志(了解) # 3.handler对象:控制日志输出的位置(文件/终端) hd1 = logging.FileHandler(‘a1.log‘,encoding=‘utf-8‘) # 输出到文件中 hd2 = logging.FileHandler(‘a2.log‘,encoding=‘utf-8‘) # 输出到文件中 hd3 = logging.StreamHandler() # 输出到终端 # 4.formmater对象:规定日志内容的格式 fm1 = logging.Formatter( fmt=‘%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s‘, datefmt=‘%Y-%m-%d %H:%M:%S %p‘, ) fm2 = logging.Formatter( fmt=‘%(asctime)s - %(name)s: %(message)s‘, datefmt=‘%Y-%m-%d‘, ) # 5.给logger对象绑定handler对象 logger.addHandler(hd1) logger.addHandler(hd2) logger.addHandler(hd3) # 6.给handler绑定formmate对象 hd1.setFormatter(fm1) hd2.setFormatter(fm2) hd3.setFormatter(fm1) # 7.设置日志等级 logger.setLevel(20) # 8.记录日志 logger.debug(‘写了半天 好累啊 好热啊 好想释放‘)
logging配置字典
import os import logging.config # 定义三种日志输出格式 开始 standard_format = ‘[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]‘ ‘[%(levelname)s][%(message)s]‘ #其中name为getlogger指定的名字 simple_format = ‘[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s‘ # 定义日志输出格式 结束 """ 下面的两个变量对应的值 需要你手动修改 """ logfile_dir = os.path.dirname(__file__) # log文件的目录 logfile_name = ‘a3.log‘ # log文件名 # 如果不存在定义的日志目录就创建一个 if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir) # log文件的全路径 logfile_path = os.path.join(logfile_dir, logfile_name) # log配置字典 LOGGING_DIC = { ‘version‘: 1, ‘disable_existing_loggers‘: False, ‘formatters‘: { ‘standard‘: { ‘format‘: standard_format }, ‘simple‘: { ‘format‘: simple_format }, }, ‘filters‘: {}, # 过滤日志 ‘handlers‘: { #打印到终端的日志 ‘console‘: { ‘level‘: ‘DEBUG‘, ‘class‘: ‘logging.StreamHandler‘, # 打印到屏幕 ‘formatter‘: ‘simple‘ }, #打印到文件的日志,收集info及以上的日志 ‘default‘: { ‘level‘: ‘DEBUG‘, ‘class‘: ‘logging.handlers.RotatingFileHandler‘, # 保存到文件 ‘formatter‘: ‘standard‘, ‘filename‘: logfile_path, # 日志文件 ‘maxBytes‘: 1024*1024*5, # 日志大小 5M ‘backupCount‘: 5, ‘encoding‘: ‘utf-8‘, # 日志文件的编码,再也不用担心中文log乱码了 }, }, ‘loggers‘: { #logging.getLogger(__name__)拿到的logger配置 ‘‘: { ‘handlers‘: [‘default‘, ‘console‘], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 ‘level‘: ‘DEBUG‘, ‘propagate‘: True, # 向上(更高level的logger)传递 }, # 当键不存在的情况下 默认都会使用该k:v配置 }, } # 使用日志字典配置 logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置 logger1 = logging.getLogger(‘asajdjdskaj‘) logger1.debug(‘好好的 不要浮躁 努力就有收获‘)
hashlib模块(加密模块)
hash是什么? hash是一种算法(3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法),该算法接受传入的内容,经过运算得到一串hash值 hash值的特点是什么? 1 只要传入的内容一样,得到的hash值必然一样=====>要用明文传输密码文件完整性校验 2 不能由hash值返解成内容=======》把密码做成hash值,不应该在网络传输明文密码 3 只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的
基本调用 import hashlib new_md5 = hashlib.md5() # 创建hashlib的md5对象 new_md5.update(‘字符串‘) # 将字符串载入到md5对象中,获得md5算法加密。 print(new_md5.hexdigest()) # 通过hexdigest()方法,获得new_md5对象的16进制md5显示。 简单调用 new_md5 = hashlib.new(‘md5‘,b‘字符串‘).hexdigest() # 或者 new_md5 = hashlib.md5(str(time.time().encode(‘utf-8‘)).hexdigest() 注意:向对象中传入字符串时,必须为编码类型。可以使用字符串前b‘ ‘的方法或使用.encode(‘UTF-8‘)的方法,使字符串变为bytes类型。
加盐
import hashlib yan = ‘!任#意%字^符@‘ # 定义加盐字符串 pwd = input(‘>>>‘) md5_pwd = hashlib.md5() md5_pwd.update((pwd+yan).encode(‘UTF-8‘)) # 加盐 pwd = md5_pwd.hexdigest() # pwd = hashlib.new(‘md5‘,(pwd+yan).encode(‘UTF-8‘)).hexdigest() # 也可以这样简写
openpyxl模块
安装 pip install openpyxl
打开文件
# 创建 from openpyxl import Workbook # 实例化 wb = Workbook() # 激活 worksheet ws = wb.active # 打开已有 >>> from openpyxl import load_workbook >>> wb2 = load_workbook(‘文件名称.xlsx‘)
存储数据
# 方式一:数据可以直接分配到单元格中(可以输入公式) ws[‘A1‘] = 42 # 方式二:可以附加行,从第一列开始附加(从最下方空白处,最左开始)(可以输入多行) ws.append([1, 2, 3]) # 方式三:Python 类型会被自动转换 ws[‘A3‘] = datetime.datetime.now().strftime("%Y-%m-%d")
创建表
# 方式一:插入到最后(default) >>> ws1 = wb.create_sheet("Mysheet") # 方式二:插入到最开始的位置 >>> ws2 = wb.create_sheet("Mysheet", 0)
选择表
# sheet 名称可以作为 key 进行索引 >>> ws3 = wb["New Title"] >>> ws4 = wb.get_sheet_by_name("New Title") >>> ws is ws3 is ws4 True
查看表名
# 显示所有表名 >>> print(wb.sheetnames) [‘Sheet2‘, ‘New Title‘, ‘Sheet1‘] # 遍历所有表 >>> for sheet in wb: ... print(sheet.title)
访问单元格cell
# 单一单元格访问 # 方法一 >>> c = ws[‘A4‘] # 方法二:row 行;column 列 >>> d = ws.cell(row=4, column=2, value=10) # 方法三:只要访问就创建 >>> for i in range(1,101): ... for j in range(1,101): ... ws.cell(row=i, column=j) # 多单元格访问 # 通过切片 >>> cell_range = ws[‘A1‘:‘C2‘] # 通过行(列) >>> colC = ws[‘C‘] >>> col_range = ws[‘C:D‘] >>> row10 = ws[10] >>> row_range = ws[5:10] # 通过指定范围(行 → 行) >>> for row in ws.iter_rows(min_row=1, max_col=3, max_row=2): ... for cell in row: ... print(cell) <Cell Sheet1.A1> <Cell Sheet1.B1> <Cell Sheet1.C1> <Cell Sheet1.A2> <Cell Sheet1.B2> <Cell Sheet1.C2> # 通过指定范围(列 → 列) >>> for row in ws.iter_rows(min_row=1, max_col=3, max_row=2): ... for cell in row: ... print(cell) <Cell Sheet1.A1> <Cell Sheet1.B1> <Cell Sheet1.C1> <Cell Sheet1.A2> <Cell Sheet1.B2> <Cell Sheet1.C2> # 遍历所有 方法一 >>> ws = wb.active >>> ws[‘C9‘] = ‘hello world‘ >>> tuple(ws.rows) ((<Cell Sheet.A1>, <Cell Sheet.B1>, <Cell Sheet.C1>), (<Cell Sheet.A2>, <Cell Sheet.B2>, <Cell Sheet.C2>), ... (<Cell Sheet.A8>, <Cell Sheet.B8>, <Cell Sheet.C8>), (<Cell Sheet.A9>, <Cell Sheet.B9>, <Cell Sheet.C9>)) # 遍历所有 方法二 >>> tuple(ws.columns) ((<Cell Sheet.A1>, <Cell Sheet.A2>, <Cell Sheet.A3>, ... <Cell Sheet.B7>, <Cell Sheet.B8>, <Cell Sheet.B9>), (<Cell Sheet.C1>, ... <Cell Sheet.C8>, <Cell Sheet.C9>))
保存数据 >>> wb.save(‘文件名称.xlsx‘)
其他
# 改变 sheet 标签按钮颜色 ws.sheet_properties.tabColor = "1072BA"? ? ?# 获得最大列和最大行 print(sheet.max_row) print(sheet.max_column) ?? # ?获取每一行,每一列 # ?sheet.rows为生成器, 里面是每一行的数据,每一行又由一个tuple包裹。 # sheet.columns类似,不过里面是每个tuple是每一列的单元格。 ?# 因为按行,所以返回A1, B1, C1这样的顺序 for row in sheet.rows: for cell in row: print(cell.value) # A1, A2, A3这样的顺序 for column in sheet.columns: for cell in column: print(cell.value) ? # 根据数字得到字母,根据字母得到数字?? ?from openpyxl.utils import get_column_letter, column_index_from_string # 根据列的数字返回字母 print(get_column_letter(2)) # B # 根据字母返回列的数字 print(column_index_from_string(‘D‘)) # 4 ??# 删除工作表 # 方式一 wb.remove(sheet) # 方式二 del wb[sheet]??? ?# ??矩阵置换(行 → 列) ?rows = [ [‘Number‘, ‘data1‘, ‘data2‘], [2, 40, 30], [3, 40, 25], [4, 50, 30], [5, 30, 10], [6, 25, 5], [7, 50, 10]] list(zip(*rows)) # out [(‘Number‘, 2, 3, 4, 5, 6, 7), (‘data1‘, 40, 40, 50, 30, 25, 50), (‘data2‘, 30, 25, 30, 10, 5, 10)] # 注意 方法会舍弃缺少数据的列(行) rows = [ [‘Number‘, ‘data1‘, ‘data2‘], [2, 40 ], # 这里少一个数据 [3, 40, 25], [4, 50, 30], [5, 30, 10], [6, 25, 5], [7, 50, 10], ] # out [(‘Number‘, 2, 3, 4, 5, 6, 7), (‘data1‘, 40, 40, 50, 30, 25, 50)]
深浅拷贝
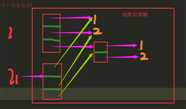
浅拷贝
深拷贝
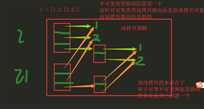
import copy l = [1,2,[1,2]] l1 = l print(id(l),id(l1)) l1 = copy.copy(l) # 浅拷贝 print(id(l),id(l1)) l[0] = 222 print(l,l1) l[2].append(666) print(l,l1) l1 = copy.deepcopy(l) # 深拷贝 l[2].append(666) print(l,l1)
标签:ict creat idt 简单 日期时间 讲解 分配 lse dha
原文地址:https://www.cnblogs.com/renvip/p/11216191.html
