标签:put list for 忽略 地址 输入 分类 bsp 方便
如果 a+b+c=1000,且 a^2+b^2=c^2(a,b,c 为自然数),如何求出所有a、b、c可能的组合?
(可以考虑到百钱白鸡) 枚举法
# 注意是三重循环
import time
start_time = time.time()
for a in range(0, 1001):
for b in range(0, 1001):
for c in range(0, 1001):
if a**2 + b**2 == c**2 and a+b+c == 1000:
print("a, b, c: %d, %d, %d" % (a, b, c))
end_time = time.time()
print("elapsed: %f" % (end_time - start_time))
print("complete!")
时间复杂度为T(n) = O(n*n*n) = O(n3)
算法是计算机处理信息的本质,因为计算机程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务。一般地,当算法在处理信息时,会从输入设备或数据的存储地址读取数据,把结果写入输出设备或某个存储地址供以后再调用。
算法(Algorithm):一个计算过程,解决问题的方法。
对于算法而言,实现的语言并不重要,重要的是思想。
算法可以有不同的语言描述实现版本(如C描述、C++描述、Python描述等),我们现在是在用Python语言进行描述实现。
确切性(Definiteness):
算法的每一步骤必须有确切的定义;
输入(Input):
一个算法有0个或多个输入,以刻画运算对象的初始情况,所谓0个输入是指算法本身定出了初始条件;
输出(Output):
一个算法有一个或多个输出,以反映对输入数据加工后的结果。没有输出的算法是毫无意义的;
可行性(Effectiveness):
算法中执行的任何计算步骤都是可以被分解为基本的可执行的操作步,即每个计算步都可以在有限时间内完成(也称之为有效性)。

import time start_time = time.time() # 注意是两重循环for a in range(0, 1001): for b in range(0, 1001-a): c = 1000 - a - b if a**2 + b**2 == c**2: print("a, b, c: %d, %d, %d" % (a, b, c)) end_time = time.time() print("elapsed: %f" % (end_time - start_time)) print("complete!")
时间复杂度为O(n*n*(1+1)) = O(n*n) = O(n^2)
算法的时间复杂度是一个函数,它定量描述了该算法的运行时间,时间复杂度常用大O符号(大O符号(Big O notation)是用于描述函数渐进行为的数学符号。更确切地说,它是用另一个(通常更简单的)函数来描述一个函数数量级的渐近上界。使用这种方式时,时间复杂度可被称为是渐近的,它考察当输入值大小趋近无穷时的情况。
对于算法的时间效率,我们可以用“大O记法”来表示。大O,简而言之可以认为它的含义是“order of”(大约是)。
无穷大渐近
“大O记法”:对于单调的整数函数f,如果存在一个整数函数g和实常数c>0,使得对于充分大的n总有f(n)<=c*g(n),就说函数g是f的一个渐近函数(忽略常数),记为f(n)=O(g(n))。也就是说,在趋向无穷的极限意义下,函数f的增长速度受到函数g的约束,亦即函数f与函数g的特征相似。
时间复杂度:假设存在函数g,使得算法A处理规模为n的问题示例所用时间为T(n)=O(g(n)),则称O(g(n))为算法A的渐近时间复杂度,简称时间复杂度,记为T(n)。
大O,简而言之可以认为它的含义是“order of”(大约是)。无穷大渐近。
大O符号在分析算法效率的时候非常有用。举个例子,解决一个规模为 n 的问题所花费的时间(或者所需步骤的数目)可以被求得:T(n) = 4n^2 - 2n + 2。
当 n 增大时,n^2; 项将开始占主导地位,而其他各项可以被忽略——举例说明:当 n = 500,4n^2; 项是 2n 项的1000倍大,因此在大多数场合下,省略后者对表达式的值的影响将是可以忽略不计的。
(1)常数阶O(1)
常数又称定数,是指一个数值不变的常量,与之相反的是变量
为什么下面算法的时间复杂度不是O(3),而是O(1)。
int sum = 0,n = 100; /*执行一次*/
sum = (1+n)*n/2; /*执行一次*/
printf("%d", sum); /*行次*/
这个算法的运行次数函数是f(n)=3。根据我们推导大O阶的方法,第一步就是把常数项3改为1。在保留最高阶项时发现,它根本没有最高阶项,所以这个算法的时间复杂度为O(1)。
另外,我们试想一下,如果这个算法当中的语句sum=(1+n)*n/2有10句,即:
int sum = 0, n = 100; /*执行1次*/
sum = (1+n)*n/2; /*执行第1次*/
sum = (1+n)*n/2; /*执行第2次*/
sum = (1+n)*n/2; /*执行第3次*/
sum = (1+n)*n/2; /*执行第4次*/
sum = (1+n)*n/2; /*执行第5次*/
sum = (1+n)*n/2; /*执行第6次*/
sum = (1+n)*n/2; /*执行第7次*/
sum = (1+n)*n/2; /*执行第8次*/
sum = (1+n)*n/2; /*执行第9次*/
sum = (1+n)*n/2; /*执行第10次*/
printf("%d",sum); /*执行1次*/
事实上无论n为多少,上面的两段代码就是3次和12次执行的差异。这种与问题的大小无关(n的多少),执行时间恒定的算法,我们称之为具有O(1)的时间复杂度,又叫常数阶。
注意:不管这个常数是多少,我们都记作O(1),而不能是O(3)、O(12)等其他任何数字,这是初学者常常犯的错误。
推导大O阶方法
1.用常数1取代运行时间中的所有加法常数
2.在修改后的运行次数函数中,只保留最高阶项
3.如果最高阶项存在且不是1,则去除与这个项相乘的常数
(2)对数阶O(log2n)
对数
如果a的x次方等于N(a>0,且a不等于1),那么数x叫做以a为底N的对数(logarithm),记作x=logaN, 。其中,a叫做对数的底数,N叫做真数。
5^2 = 25 , 记作 2= log5 25
对数是一种运算,与指数是互逆的运算。例如
① 3^2=9 <==> 2=log<3>9;
② 4^(3/2)=8 <==> 3/2=log<4>8;
③ 10^n=35 <==> n=lg35。为了使用方便,人们逐渐把以10为底的常用对数记作lgN
对数阶
int count = 1;
while (count < n)
{
count = count * 2; /* 时间复杂度为O(1)的程序步骤序列 */
}
由于每次count乘以2之后,就距离n更近了一分。
也就是说,有多少个2相乘后大于n,则会退出循环。
由2^x=n得到x=log2n。所以这个循环的时间复杂度为O(logn)。
(3)线性阶O(n)
执行时间随问题规模增长呈正比例增长
data = [ 8,3,67,77,78,22,6,3,88,21,2]
find_num = 22
for i in data:
if i == 22:
print("find",find_num,i )
(4)线性对数阶O(nlog2n)
对数阶O(log2n) * n
(5)平方阶O(n^2)
for i in range(100):
for k in range(100):
print(i,k)
(6)立方阶O(n^3)
(7)k次方阶O(n^k),
(8)指数阶O(2^n)。
随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低。
分析算法时,存在几种可能的考虑:
算法完成工作最少需要多少基本操作,即最优时间复杂度
算法完成工作最多需要多少基本操作,即最坏时间复杂度
算法完成工作平均需要多少基本操作,即平均时间复杂度
对于最优时间复杂度,其价值不大,因为它没有提供什么有用信息,其反映的只是最乐观最理想的情况,没有参考价值。
对于最坏时间复杂度,提供了一种保证,表明算法在此种程度的基本操作中一定能完成工作。
对于平均时间复杂度,是对算法的一个全面评价,因此它完整全面的反映了这个算法的性质。但另一方面,这种衡量并没有保证,不是每个计算都能在这个基本操作内完成。而且,对于平均情况的计算,也会因为应用算法的实例分布可能并不均匀而难以计算。
因此,我们主要关注算法的最坏情况,亦即最坏时间复杂度。
时间复杂度的几条基本计算规则:
基本操作,即只有常数项,认为其时间复杂度为O(1)
顺序结构,时间复杂度按加法进行计算
循环结构,时间复杂度按乘法进行计算
分支结构,时间复杂度取最大值
判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略。
在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度。
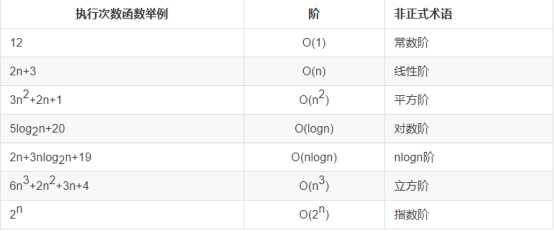
注意,经常将log2n(以2为底的对数)简写成logn
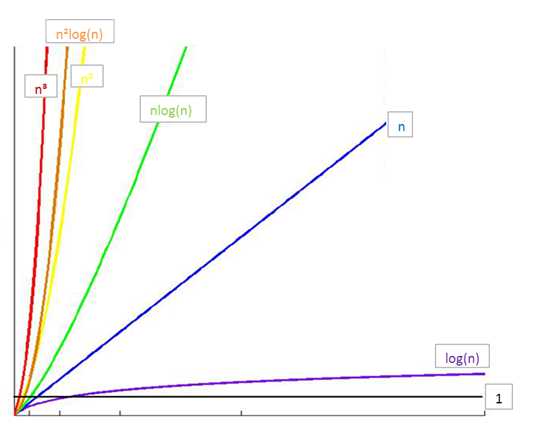
所消耗的时间从小到大
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
timeit模块
timeit模块可以用来测试一小段Python代码的执行速度。
class timeit.Timer(stmt=‘pass‘, setup=‘pass‘, timer=<timer function>)
Timer是测量小段代码执行速度的类。
stmt参数是要测试的代码语句(statment);
setup参数是运行代码时需要的设置;
timer参数是一个定时器函数,与平台有关。
timeit.Timer.timeit(number=1000000)
Timer类中测试语句执行速度的对象方法。number参数是测试代码时的测试次数,默认为1000000次。方法返回执行代码的平均耗时,一个float类型的秒数。
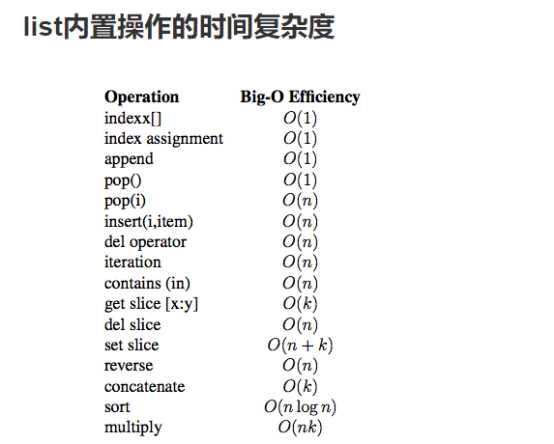
list的操作测试对比运行时间:
from timeit import Timer def t1(): list1 = [] for i in range(10000): # insert方法第一位插入更慢 list1.append(i) def t2(): list2 = [] for i in range(10000): list2 += [i] def t3(): list3 = [i for i in range(10000)] def t4(): list4 = list(range(10000)) def t5(): list5 = [] for i in range(10000): list5.extend([i]) time1 = Timer("t1()", "from __main__ import t1") print("法一:append方法:", time1.timeit(number=1000), "seconds") time2 = Timer("t2()", "from __main__ import t2") print("法二:concat + 操作:", time2.timeit(number=1000), "seconds") time3 = Timer("t3()", "from __main__ import t3") print("法三:comprehension(列表推导式) :", time3.timeit(number=1000), "seconds") time4 = Timer("t4()", "from __main__ import t4") print("法四:list range(迭代对象生成:", time4.timeit(number=1000), "seconds") time5 = Timer("t5()", "from __main__ import t5") print("法五:list range(迭代对象生成:", time5.timeit(number=1000), "seconds") # pop操作测试 x = [i for i in range(2000000)] pop_zero = Timer("x.pop(0)", "from __main__ import x") print("pop_zero ", pop_zero.timeit(number=1000), "seconds") y = [i for i in range(2000000)] pop_end = Timer("y.pop()", "from __main__ import y") print("pop_end ", pop_end.timeit(number=1000), "seconds")

概念
数据是一个抽象的概念,将其进行分类后得到程序设计语言中的基本类型。如:int,float,char等。数据元素之间不是独立的,存在特定的关系,这些关系便是结构。数据结构指数据对象中数据元素之间的关系。
Python给我们提供了很多现成的数据结构类型,这些系统自己定义好的,不需要我们自己去定义的数据结构叫做Python的内置数据结构,比如列表、元组、字典。而有些数据组织方式,Python系统里面没有直接定义,需要我们自己去定义实现这些数据的组织方式,这些数据组织方式称之为Python的扩展数据结构,比如栈,队列等。
(算法是解决问题的思路,数据结构是解决思路处理的数据是什么方式存在)
数据结构只是静态的描述了数据元素之间的关系。
高效的程序需要在数据结构的基础上设计和选择算法。
程序 = 数据结构 + 算法
总结:算法是为了解决实际问题而设计的,数据结构是算法需要处理的问题载体
3.抽象数据类型(ADT)
抽象数据类型(ADT)的含义是指一个数学模型以及定义在此数学模型上的一组操作。即把数据类型和数据类型上的运算捆在一起,进行封装。引入抽象数据类型的目的是把数据类型的表示和数据类型上运算的实现与这些数据类型和运算在程序中的引用隔开,使它们相互独立。
最常用的数据运算有五种:
插入
删除
修改
查找
排序
标签:put list for 忽略 地址 输入 分类 bsp 方便
原文地址:https://www.cnblogs.com/hszstudypy/p/11218695.html
