标签:erer col http import get com htm apple print
不废话,直接上干货:
#!/user/bin env python # author:Simple-Sir # time:2019/7/17 22:08 # 获取豆瓣网正在上映电影最热评论 import requests from lxml import etree # 伪装浏览器 headers ={ ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36‘, ‘Referer‘:‘https://movie.douban.com/‘ } # 获取首页网页信息并解析 url = ‘https://movie.douban.com/cinema/nowplaying/chengdu/‘ def getUrlText(url): respons = requests.get(url,headers=headers) # 获取网页信息 urlText = respons.text html = etree.HTML(urlText) # 使用lxml解析网页 return html # 提取电影名称及详情地址链接列表 def getWallUrl(url): hrefUrl = getUrlText(url) ul = hrefUrl.xpath(‘//ul[@class="lists"]‘)[0] # 获取ul标签 liList = ul.xpath(‘./li‘) # # 获取li标签列表 liHrefs = [] for li in liList: liHref = li.xpath(‘.//@href‘)[0] name = li.xpath(‘@data-title‘)[0] msg = { name:liHref } liHrefs.append(msg) return liHrefs # 解析电影详情地址 def downPL(url): moveUrl = getWallUrl(url) n=0 for murl in moveUrl: n+=1 for d in murl: plHtml = getUrlText(murl[d]) plTextFull = plHtml.xpath(‘//div[@id="hot-comments"]//span[@class="hide-item full"]//text()‘) plTextShort = plHtml.xpath(‘//div[@id="hot-comments"]//span[@class="short"]//text()‘) if(len(plTextFull)==0 and len(plTextShort)>0): print(‘正在写入《{}》的评论。‘.format(d)) with open(‘豆瓣评论.txt‘,‘a+‘,encoding=‘utf-8‘) as fp: fp.write(‘{}、《{}》的最热评论是:\n{}\n\n‘.format(n,d,plTextShort[0])) elif(len(plTextFull)>0): print(‘正在写入《{}》的评论。‘.format(d)) with open(‘豆瓣评论.txt‘,‘a+‘,encoding=‘utf-8‘) as fp: fp.write(‘{}、《{}》的最热评论是:\n{}\n\n‘.format(n,d,plTextShort[0])) else: print(‘正在写入《{}》的评论。‘.format(d)) with open(‘豆瓣评论.txt‘,‘a+‘,encoding=‘utf-8‘) as fp: fp.write(‘{}、《{}》暂无评论!\n\n‘.format(n,d)) return print(‘{}部电影的所有评论已全部写入“豆瓣评论.txt”,请查看。‘.format(n)) if __name__ == ‘__main__‘: downPL(url)
执行效果:
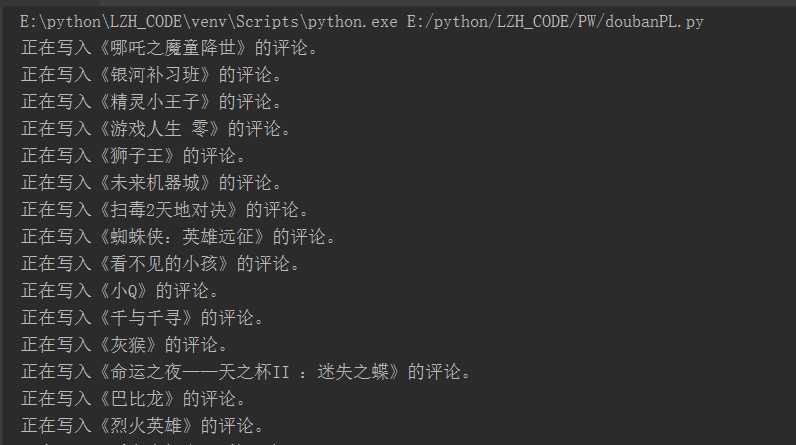
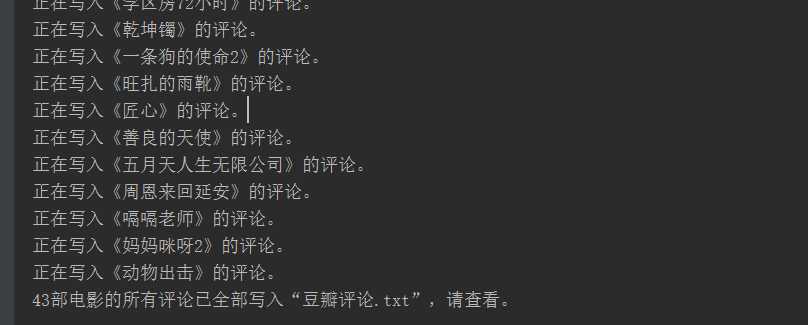
文件详情:
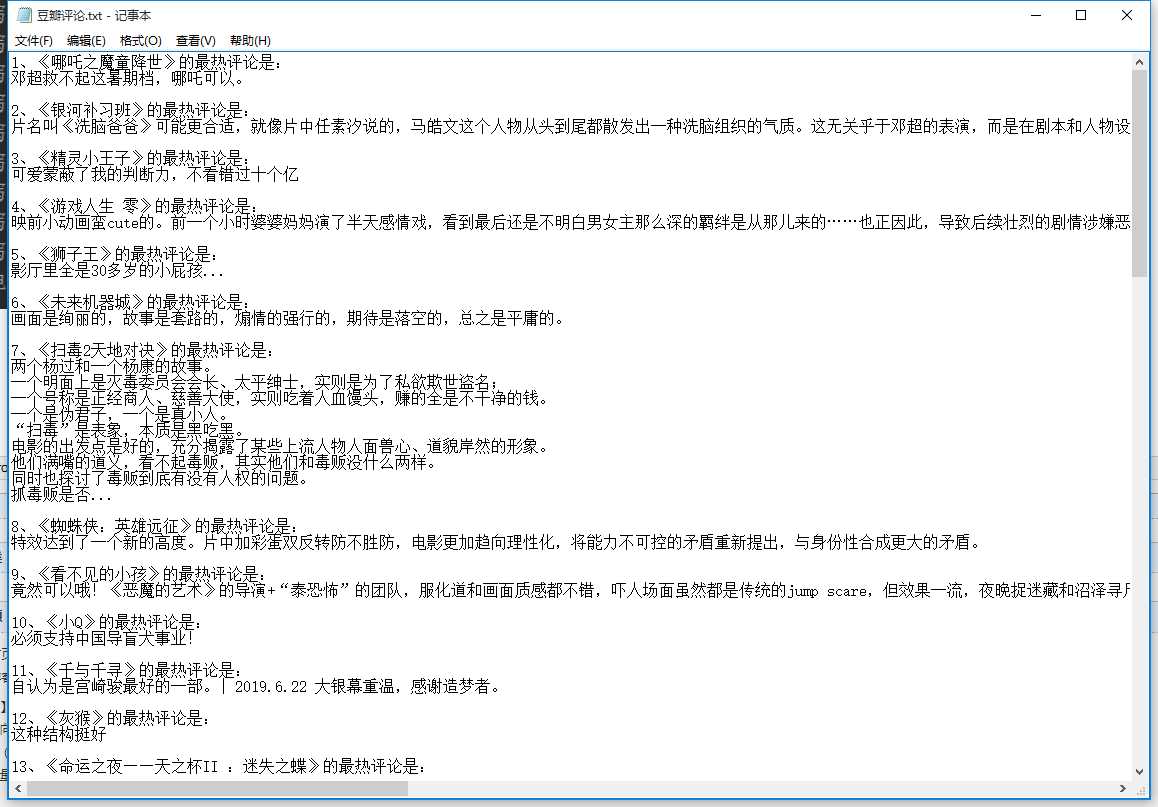
标签:erer col http import get com htm apple print
原文地址:https://www.cnblogs.com/simple-li/p/11219586.html