标签:tin 进程 数组元素 cti 处理 com 冒号 ret 赋值
SELinux策略
对象(object):所有可以读取的对象,包括文件、目录和进程,端口等
主体:进程称为主体(subject)
SELinux中对所有的文件都赋予一个type的文件类型标签,对于所有的进程也赋予各自的一个domain的标签。domain标签能够执行的操作由安全策略里定义
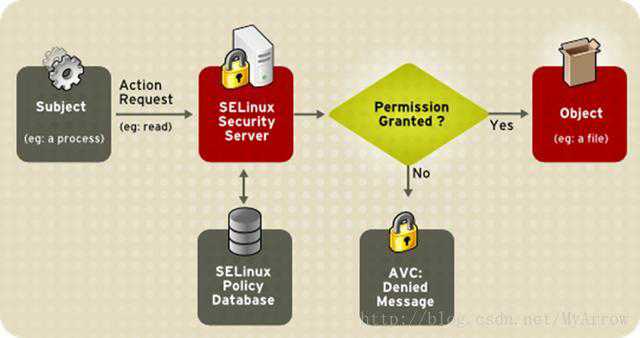
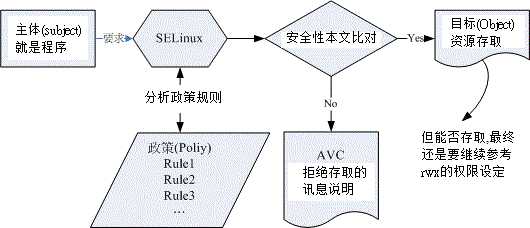
当一个subject试图访问一个object,Kernel中的策略执行服务器将检查AVC (访问矢量缓存Access Vector Cache), 在AVC中,subject和object的权限被缓存(cached),查找“应用+文件”的安全环境。然后根据查询结果允许或拒绝访问
安全策略:定义主体读取对象的规则数据库,规则中记录了哪个类型的主体使用哪个方法读取哪一个对象是允许还是拒绝的,并且定义了哪种行为是充许或拒绝
SELinux工作过程
配置SELinux
getenforce: 获取selinux当前状态
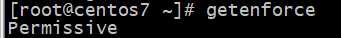
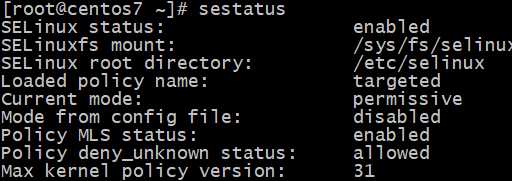
sestatus :查看selinux状态
setenforce设定selinux运行状态,1开启(Enforce),0关闭(Permissive)



修改配置文件
/etc/selin ux/config /etc/sysconfig/selinux selinux=enable
ux/config /etc/sysconfig/selinux selinux=enable
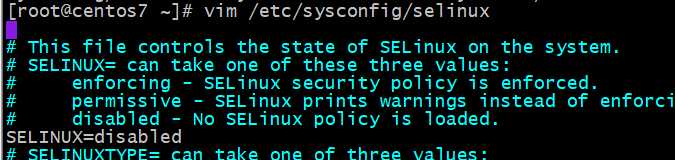
SELINUX={disabled|enforcing|permissive}
-------------------------------------------------------------------------------
awk介绍
有多种版本:New awk(nawk),GNU awk( gawk)
gawk:模式扫描和处理语言
基本格式:awk [options] ‘program‘ file…
pattern和action
pattern部分决定动作语句何时触发及触发事件
action statements对数据进行处理,放在{}内指明
分割符、域和记录
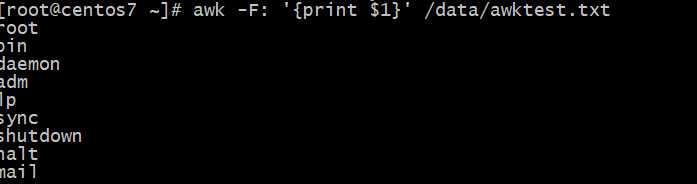
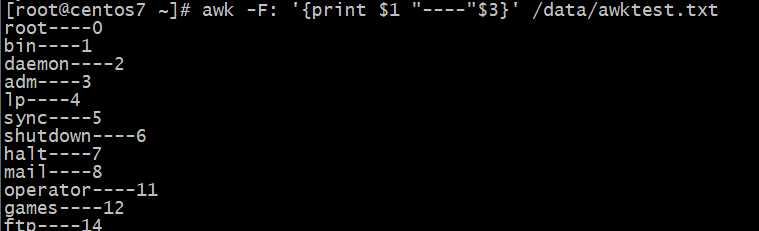
awk执行时,由分隔符分隔的字段(域)标记$1,$2...$n称为域标识。$0为所有域,注意:此时和shell中变量$符含义不同
文件的每一行称为记录
省略action,则默认执行 print $0 的操作
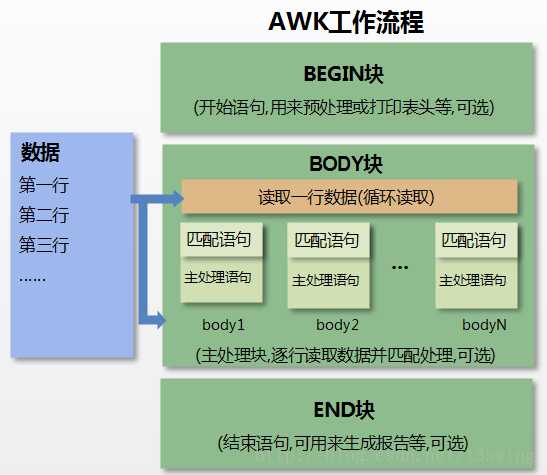
第一步:执行BEGIN{action;… }语句块中的语句
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ action;… }语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{action;…}语句块
BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块
pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块
print格式:print item1, item2, ...
实例:取出磁盘利用率


变量:内置和自定义变量
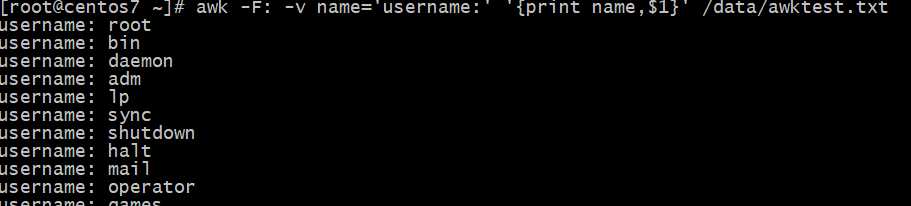
FS:输入字段分隔符,默认为空白字符
OFS:输出字段分隔符,默认为空白字符
RS:输入记录分隔符,指定输入时的换行符
ORS:输出记录分隔符,输出时用指定符号代替换行符
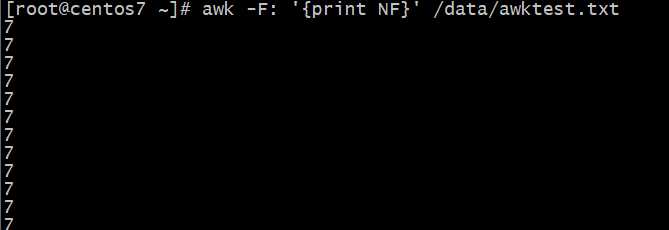
NF:字段数量
NR:记录号
FNR:各文件分别计数,记录号;
FILENAME:当前文件名;
ARGC:命令行参数的个数;
ARGV:数组,保存的是命令行所给定的各参数
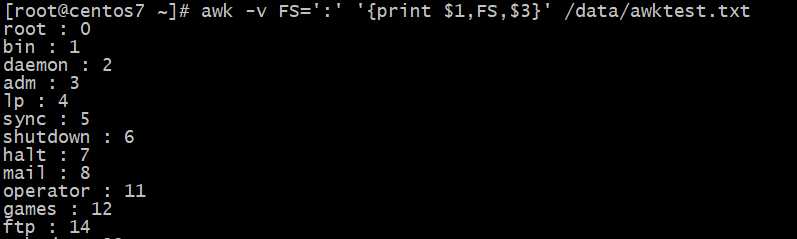
输入字段分隔符FS变量的使用
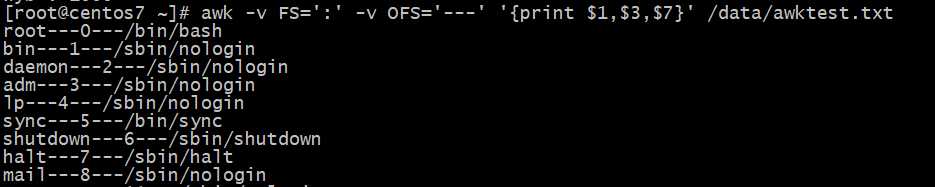
输入记录分隔符RS变量的使用

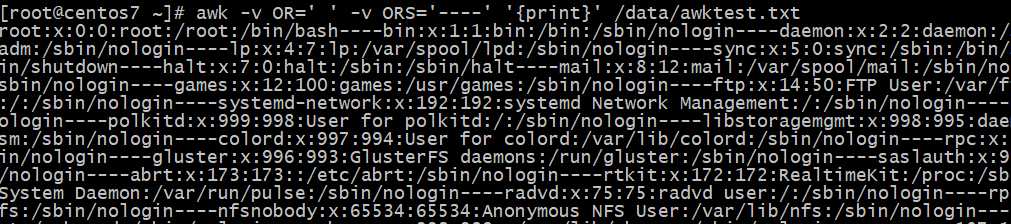
输出记录分隔符ORS变量
字段数量NF变量的使?
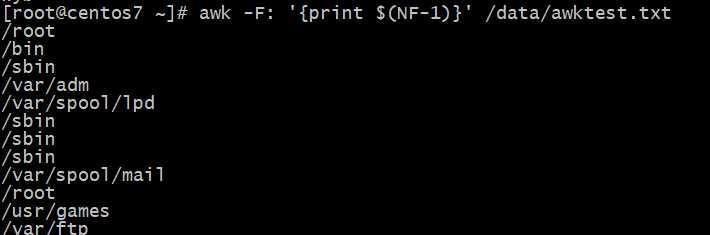
?号NR变量的使?
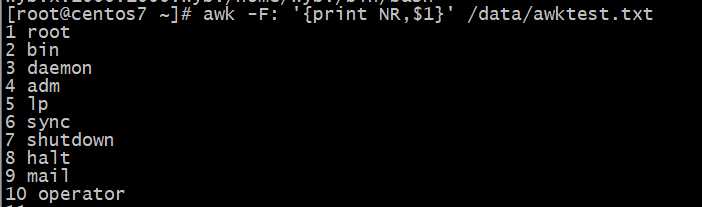
各?件分别的记录号FNR变量的使?
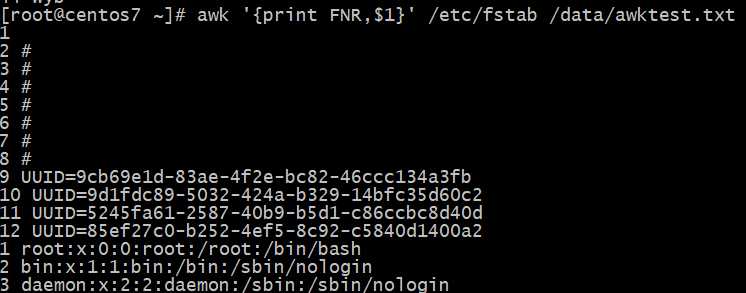
当前?件名FILENAME变量的使?
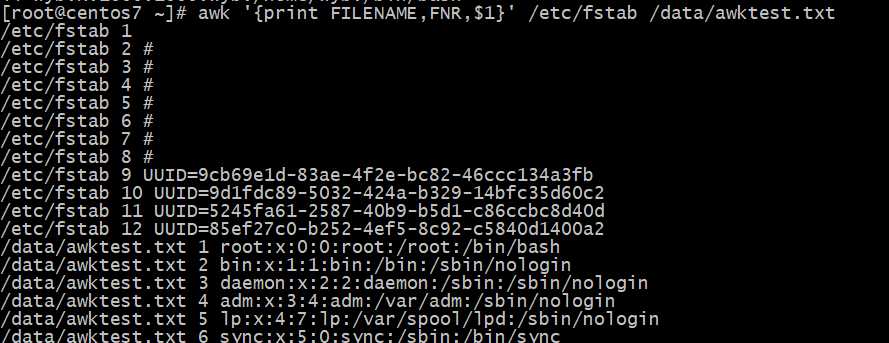
命令?参数的个数ARGC变量的使?

命令?给定的各参数的数组ARGV变量的使?

命令?给定的各参数的数组ARGV变量的使?
awk的格式化输出
格式输出:printf "FORMAT", item1, item2,...
必须知道FORMAT;
不会自动换行,需要显示给出换行控制符,\n;
FORMAT中需要分别为后面每个item指定格式符
格式符:与item??对应
%c:显示字符的ASCII码;
%d,%i:显示十进制整数;
%e,%E:显示科学计数法数值;
%f:显示为浮点数;
%g,%G:以科学计数法或浮点形式显示数值;
%s:显示字符串;
%u:无符号整数;
%%:显示%自身。
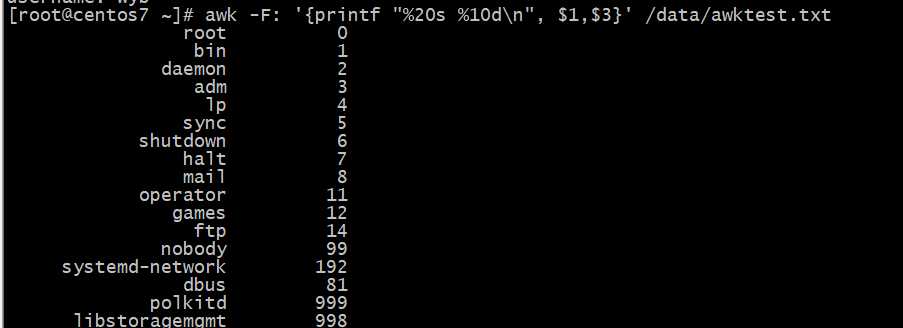
格式化输出,以冒号为分隔符,第?个字段宽度20个字符串,第?个字段宽度10个数?,??输出2个字段,然后
换?
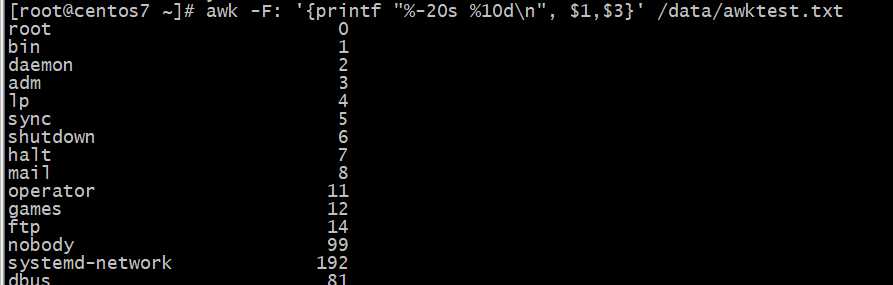
格式化输出为左对齐
awk的操作符
x+y:加法;
x-y:减法;
x*y:乘法;
x/y:除法;
x^y:幂运算;
x%y:取模(余数)
赋值操作符:
=:右边赋值给左边;
+=:先加,再赋值;
-=:先减,再赋值;
*=:先乘,再赋值;
/=:先除,再赋值;
%=:先取余,再赋值;
^=:先幂运算,再赋值;
++:递增操作;
--:递减操作。
?较操作符:
==:判断相等;
!=:判断不等;
\>:判断大于;
\>=:判断大于等于;
<:判断小于;
<=:判断小于等于
模式匹配符:
~:左边是否和右边匹配包含;
!~:是否不匹配。
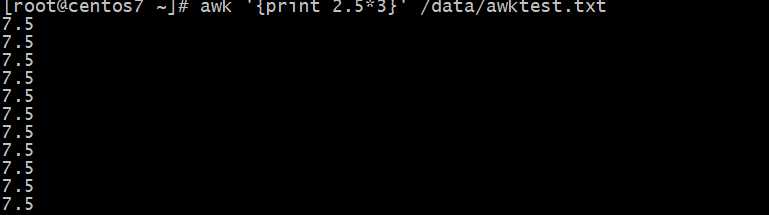
使?awk的算术操作符,计算5*4

使?awk的+=赋值操作符

使?awk的i++赋值操作符

使?awk的++i赋值操作符



匹配包含root?的记录

匹配不包含root?的记录
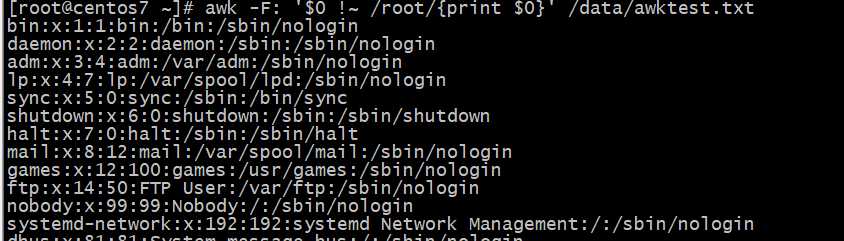
?正则表达式匹配包含root?的记录

显?硬盘分区的使?率

逻辑操作符:与&&,或||,非!
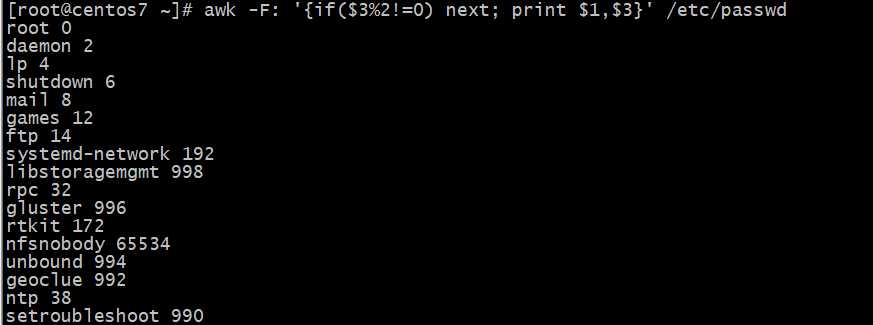
显?第三字段?于等于0,且?于等于1000的?中的第1字段
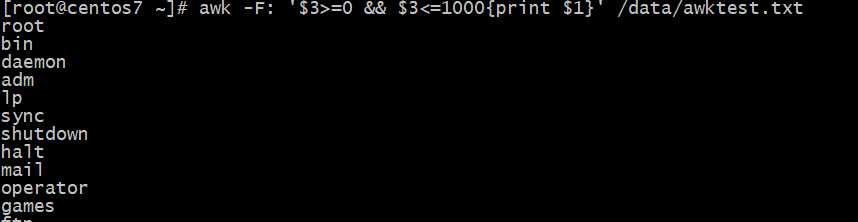
显?第三字段等于0,或?于等于1000的?中的第1字段

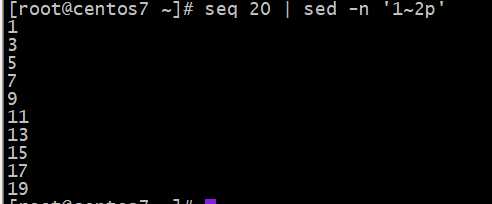
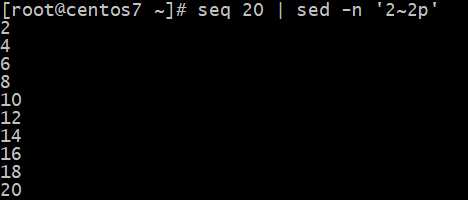
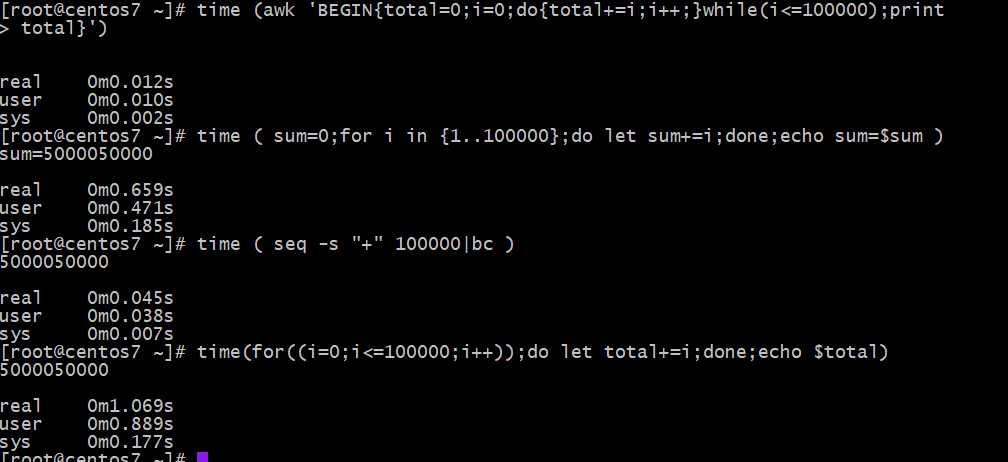
Awk实现打印奇数?和偶数?
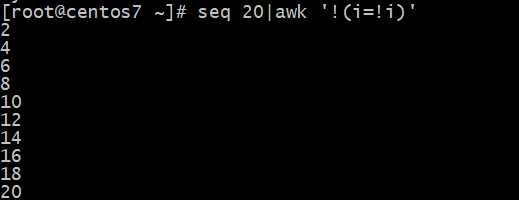
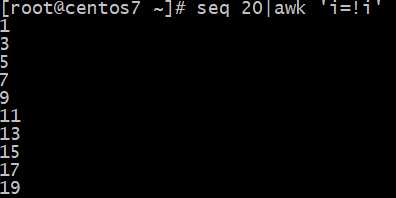
sed执行
awk PATTERN
PATTERN:根据pattern条件,过滤匹配的行,再做处理
BEGIN/END模式
BEGIN{}:仅在开始处理文件中的文本之前执行一次
END{}:仅在文本处理完成之后执行一次


BRGIN/END模式

awk控制语句if-else
使用场景:对awk取得的整行或某个字段做条件判断
查找最后?个字段是/bin/bash的?,打印第?个字段

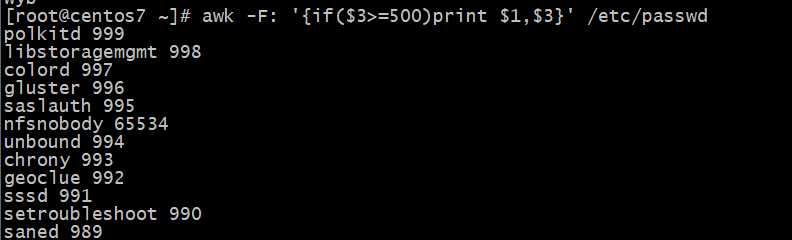
对第3字段判断?于等于500,则显?每?的
查找以空格为分隔符,显?每??于5个字段所在的?

awk的循环
while(condition){statement;...}
条件为真,进入循环,条件为假退出循环;
使?场景:对??内的多个字段逐?类似处理时使?;对数组中的各元素逐?处理时使?。
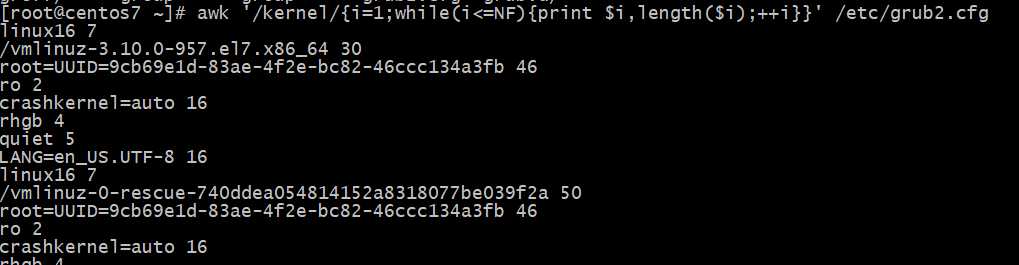
计算1+2+3+...+100的和

do-while循环
意义:无论真假,至少执行一次循环体

awk中使?for循环
计算100内整数的和

性能比较
continue语句
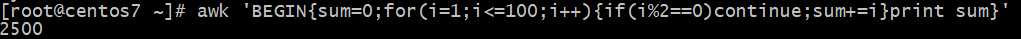
break语句
计算100内的整数和,但遇到整数66就不计算了,退出执?
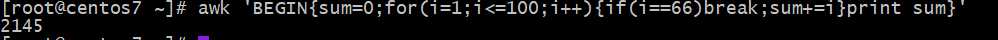
next:
提前结束对本行处理而直接进入下一行处理
awk数组
关联数组:array[index-expression]
index-expression:
可使用任意字符串;字符串要使用双引号括起来
如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为空串
若要判断数组中是否存在某元素,要使用index in array格式进行遍历
若要遍历数组中的每个元素,要使用for循环
统计各个tcp状态的个数:

Security-Enhanced Linux 文本处理三剑客之AWK
标签:tin 进程 数组元素 cti 处理 com 冒号 ret 赋值
原文地址:https://www.cnblogs.com/fengxixiaoxiao/p/11221026.html