标签:iss 序列 记忆 fill 需要 两种 lstm 参数 csdn
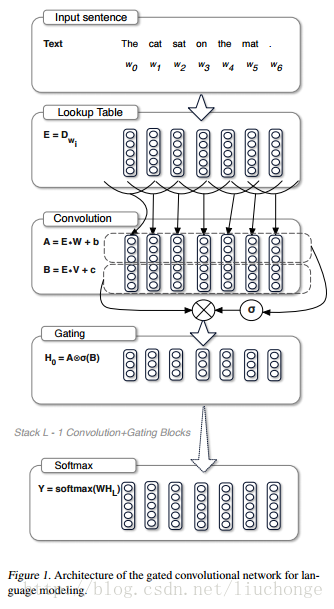

X*W+b中哪些信息可以传入下一层。这里将其定义为Gated Linear Units (GLU).然后就可以将该模型进行堆叠,以捕获Long_Term memory。 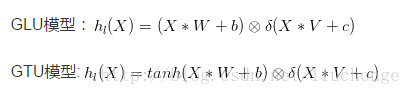

实验用了WikiText-103和GBW两个数据集,结果这里仅展示几个图表:
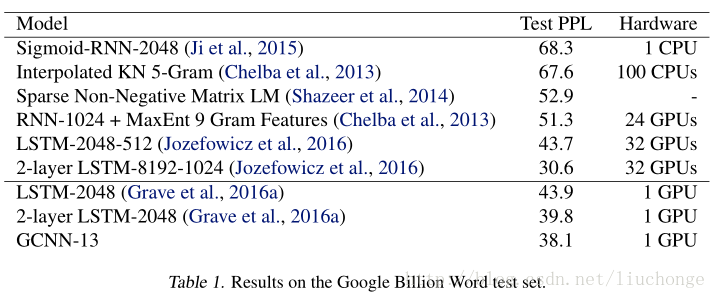
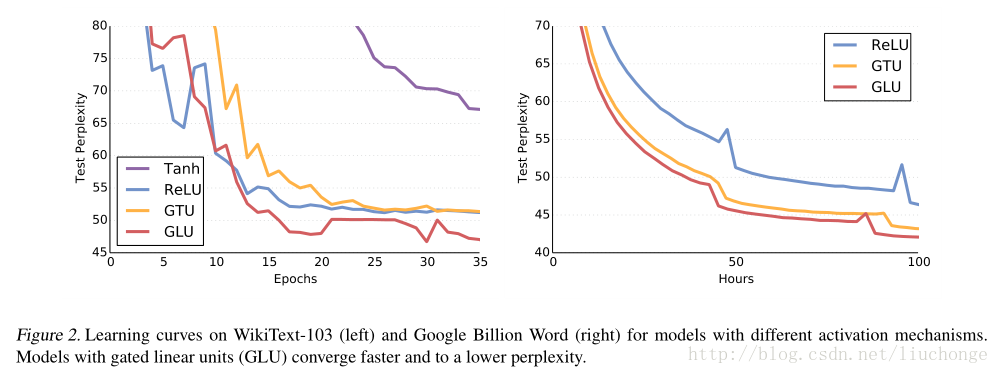
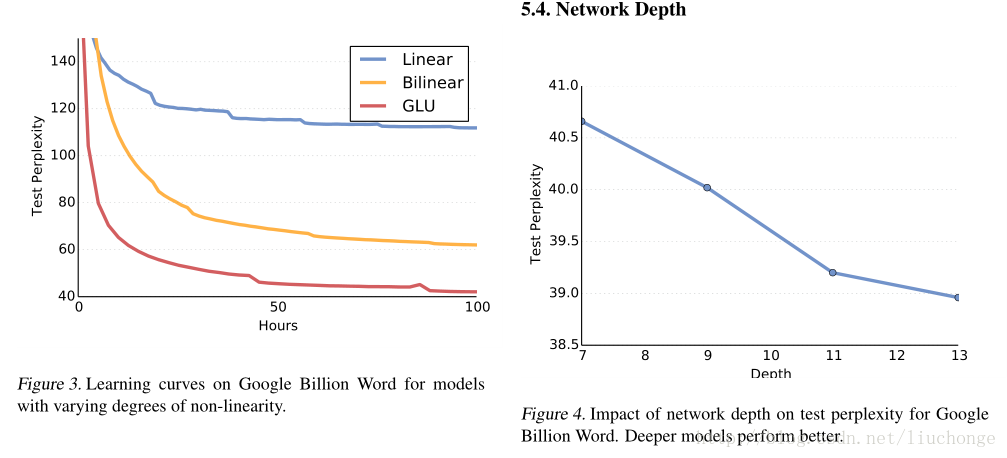
一个细节就是,对于文本长度更大的数据集而言,论文使用了更深的网络结构以获取其Long-Term记忆。
Language Modeling with Gated Convolutional Networks(句子建模之门控CNN)--模型简介篇
标签:iss 序列 记忆 fill 需要 两种 lstm 参数 csdn
原文地址:https://www.cnblogs.com/mfryf/p/11221917.html