标签:不同的 不同 ima 表示 bre 数据 mic 高效 最小
你在一家 IT 公司为大型写字楼或办公楼(offices)的计算机数据做备份。然而数据备份的工作是枯燥乏味的,因此你想设计一个系统让不同的办公楼彼此之间互相备份,而你则坐在家中尽享计算机游戏的乐趣。
已知办公楼都位于同一条街上。你决定给这些办公楼配对(两个一组)。每一对办公楼可以通过在这两个建筑物之间铺设网络电缆使得它们可以互相备份。
然而,网络电缆的费用很高。当地电信公司仅能为你提供 K 条网络电缆,这意味着你仅能为 K 对办公楼(或总计 2K 个办公楼)安排备份。任一个办公楼都属于唯一的配对组(换句话说,这 2K 个办公楼一定是相异的)。
此外,电信公司需按网络电缆的长度(公里数)收费。因而,你需要选择这 K对办公楼使得电缆的总长度尽可能短。换句话说,你需要选择这 K 对办公楼,使得每一对办公楼之间的距离之和(总距离)尽可能小。
下面给出一个示例,假定你有 5 个客户,其办公楼都在一条街上,如下图所示。这 5 个办公楼分别位于距离大街起点 1km, 3km, 4km, 6km 和 12km 处。电信公司仅为你提供 K=2 条电缆。
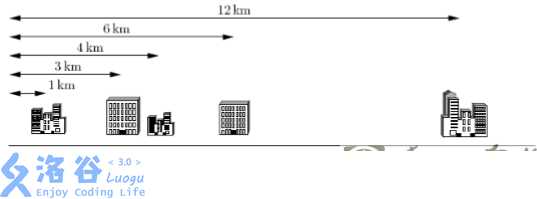
上例中最好的配对方案是将第 1 个和第 2 个办公楼相连,第 3 个和第 4 个办公楼相连。这样可按要求使用 K=2 条电缆。第 1 条电缆的长度是 \(3\text{km} - 2\text{km} = 1\text{km}\),第 2 条电缆的长度是 6km―4km = 2 km。这种配对方案需要总长 4km 的网络电缆,满足距离之和最小的要求。
显而易见,相邻两个办公楼之间连接电缆跨度最小,最为高效。但是由于每个办公楼只能属于唯一配对,所以会有以下的考虑:
\(dp\):\(O(n^3)\)
\(f[i,t]\)表示在第\(i\)个办公楼,使用\(t\)次电缆的情况,最终的答案应为:
\(\text{ans} = \min_{i ≥2k} \{f[i,k]\}\)
\[ f[i,t] = \min_{2 ≤ j ≤ i - 2}\{f[j][t-1] + x[i] - x[i - 1]\} \]
\(dp\):\(O(n^2)\)
\(f[i,t]\)表示在第\(i\)个办公楼,使用\(t\)次电缆的情况,最终的答案应为:
\(\text{ans} = \min_{i ≥2k} \{f[i,k]\}\)
\[ f[i][t] = \min \begin{cases} f[i-1][t] ~~~~~~&\text{not use}\f[i-2][t-1] + x[i] - x[i - 1]&\text{use} \end {cases} \]
高级贪心(反悔,赎回)
从一个简单的例子看起,首先对于下列数列(表示题中的差分数列):
\(7,~5,~3,~1,~3,~5,~7\)
找出最小:\(1\),删去与其相邻的两个以及自身,改为\(3 + 3 - 1 = 5\):
\(7,~5,~5,~5,~7\)
周而往复,可以发现上述的操作即为正解。
对于任意差分数列:
\[
d_1,~d_2,~d_3,~\cdots,~d_n
\]
而言,任意的\(d_i, i\in(1,n)\),若将其选出,删去原数列中的\(d_{i-1},~d_{i+1}\),并且将\(d_i\)更改为:\(d_{i + 1} + d_{i - 1} - d_i\)。接下来,可以验证这样的操作的反悔正确性:
若原差分数列的最小值:\(d_{\min} = d_i = \min\{d_j, j \in [1, n]\}, i \in (1, n)\)。进过上述的操作之后,若此时的最小值为\(d_{\min}’ = d_i’ = \min\{d_j’, j \in[1, n - 2]\}, i \in (1, n - 2)\),则两次取出的最小值之和:\(d_\min + d_\min’ = d_{i - 1} + d_{i + 1} - d_i + d_i = d_{i - 1} + d_{i + 1}\),所以这两个数仍然为原差分数列当中不重复的两个元素。
但是这种验证无法证明其边界的正确性,即当\(d_\min = d_1, d_\min = d_n\)的情况。
不妨令原来的数列为:
\[
d_0 = \infty,~d_1,~d_2,~d_3,~\cdots,~d_n, d_{n + 1} = \infty
\]
若此时最小的为\(d_\min = d_1\),则将\(d_1\)改为\(d_1’ = \infty + d_2 - d_1 = \infty\),所以此时任然可以维护最优,因为数列已经变为:
\[
d_1' = \infty,~d_3,~d_4,~d_5,~\cdots,~d_n,~d_{n+1} = \infty
\]
而对于队尾的\(d_n\)同理。
所以希望上述的操作可以再常数,或者对数的事件复杂度内完成。
所以需要用到以下三个关键的操作:
(一)查询、维护前继和后继
(二)懒删除
(三)间接比较:存序号
所以整个过程当中,需要维护一个双向链表,和一个堆,主程序思路:
while (k --> 0)的情况之下,按照上述操作维护堆和双向链表。代码:
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long ll;
const int maxn = 100005;
ll n, k, ans, val[maxn], prv[maxn], nxt[maxn];
struct Heap {
ll size;
ll Q[maxn];
bool dead[maxn];
void del_heap(int a) {
dead[a] = true;
}
ll top() {
if (!empty()) {
ll a = Q[1];
while (dead[a]) {
pop();
a = (empty() ? 0 : Q[1]);
}
return a;
} else return 0;
}
bool empty() {
return !size;
}
void swap_value(ll index_a, ll index_b) {
ll tmp = Q[index_a];
Q[index_a] = Q[index_b];
Q[index_b] = tmp;
}
void pop() {
swap_value(1, size);
size --;
down(1);
}
void down(ll i) {
ll j = 2 * i;
if (j + 1 <= size && val[Q[j + 1]] < val[Q[j]])
j = j + 1;
if (j <= size && val[Q[j]] < val[Q[i]]) {
swap_value(i, j);
down(j);
}
}
void push(ll x) {
size ++;
ll i = size;
while (i >= 2) {
ll father = i / 2;
if (val[Q[father]] <= val[x]) break;
Q[i] = Q[father];
i = father;
}
Q[i] = x;
}
} heap;
void del_link(ll i) {
ll prev_pointer = prv[i], next_pointer = nxt[i];
prv[next_pointer] = prev_pointer;
nxt[prev_pointer] = next_pointer;
// Also Right
// prv[nxt[i]] = prv[i];
// nxt[prv[i]] = nxt[i];
}
int main() {
cin >> n >> k;
// inital data
ll tmp1 = 0, tmp2 = 0;
cin >> tmp1;
for (int i = 1; i <= n - 1; i ++) {
cin >> tmp2;
val[i] = tmp2 - tmp1;
tmp1 = tmp2;
}
// create list
for (int i = 1; i <= n - 1; i ++) {
nxt[i] = i + 1;
prv[i] = i - 1;
}
prv[1] = 0; nxt[n - 1] = 0;
val[0] = 1000000000000;
// create heap
for (int i = 1; i <= n - 1; i ++) heap.push(i);
while (k --> 0) {
ll id = heap.top();
ans += val[id];
ll left_pointer = prv[id]; ll right_pointer = nxt[id];
heap.del_heap(left_pointer);
heap.del_heap(right_pointer);
del_link(left_pointer);
del_link(right_pointer);
val[id] = val[left_pointer] + val[right_pointer] - val[id];
heap.down(1);
}
cout << ans << endl;
return 0;
}普通建堆,时间复杂度:
\[
\begin {align}
&\log 1 + \log 2 + \log 3 + \log 4 + \cdots + \log n \=& \int_0^n \log x\mathrm dx < n\log n
\end {align}
\]
但是有\(O(n)\)的建堆算法:
// create heap
// O(nlog n)
// for (int i = 1; i <= n - 1; i ++) heap.push(i);
// O(n)
for (int i = 1; i <= n - 1; i ++) { heap.Q[i] = i; }
heap.size = n - 1;
for (int i = heap.size / 2; i > 0; i --) { heap.down(i); }标签:不同的 不同 ima 表示 bre 数据 mic 高效 最小
原文地址:https://www.cnblogs.com/jeffersonqin/p/11222402.html