标签:code 阻塞 获取 streaming 切分 tor pack info version
在实际开发中push会丢数据,因为push是由flume将数据发给程序,程序出错,丢失数据。所以不会使用不做讲解,这里讲解poll,拉去flume的数据,保证数据不丢失。
比如你有:【如果没有请走这篇:搭建flume集群(待定)】
这里使用的flume的版本是 apache1.6 cdh公司集成
apache1.6 cdh公司集成
这里需要下载
(1).我这里是将spark-streaming-flume-sink_2.11-2.0.2.jar放入到flume的lib目录下
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/lib
(ps:我的flume安装目录,使用ftp工具上传上去,我使用的是finalShell支持ssh也支持ftp(需要的小伙伴,点我下载))
(2)修改flume/lib下的scala依赖包(保证版本一致)
我这里是将spark中jar安装路径的scala-library-2.11.8.jar替换掉flume下的scala-library-2.10.5.jar
删除scala-library-2.10.5.jar
rm -rf /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/lib/scala-library-2.10.5.jar
cp /export/servers/spark-2.0.2/jars/scala-library-2.11.8.jar /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/lib/
(3)编写flume-poll.conf文件
创建目录
mkdir /export/data/flume
创建配置文件
vim /export/logs/flume-poll.conf
编写配置,标注发绿光的地方需要注意更改为自己本机的(flume是基于配置执行任务)
a1.sources = r1 a1.sinks = k1 a1.channels = c1 #source a1.sources.r1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /export/data/flume a1.sources.r1.fileHeader = true #channel a1.channels.c1.type =memory a1.channels.c1.capacity = 20000 a1.channels.c1.transactionCapacity=5000 #sinks a1.sinks.k1.channel = c1 a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink a1.sinks.k1.hostname=192.168.52.110 a1.sinks.k1.port = 8888 a1.sinks.k1.batchSize= 2000
底行模式wq保存退出
执行flume
flume-ng agent -n a1 -c /opt/bigdata/flume/conf -f /export/logs/flume-poll.conf -Dflume.root.logger=INFO,console
在监视的/export/data/flume下放入文件 (黄色对应的是之前创建的配置文件)
执行成功
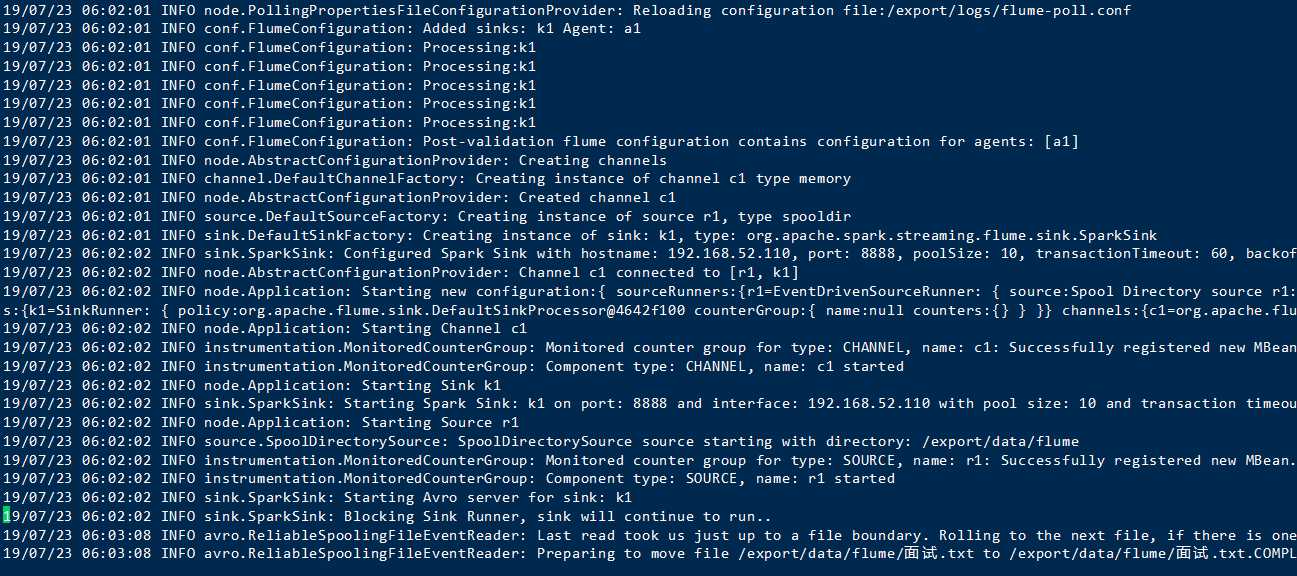
代表你flume配置没有问题,接下来开始编写代码
1.导入相关依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.11</artifactId>
<version>2.0.2</version>
</dependency>
2.编码
package SparkStreaming import SparkStreaming.DefinedFunctionAdds.updateFunc import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent} object SparkStreamingFlume { def main(args: Array[String]): Unit = { //创建sparkContext val conf: SparkConf = new SparkConf().setAppName("DefinedFunctionAdds").setMaster("local[2]") val sc = new SparkContext(conf) //去除多余的log,提高可视率 sc.setLogLevel("WARN") //创建streamingContext val scc = new StreamingContext(sc,Seconds(5)) //设置备份 scc.checkpoint("./flume") //receive(task)拉取数据 val num1: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createPollingStream(scc,"192.168.52.110",8888) //获取flume中的body val value: DStream[String] = num1.map(x=>new String(x.event.getBody.array())) //切分处理,并附上数值1 val result: DStream[(String, Int)] = value.flatMap(_.split(" ")).map((_,1)) //结果累加 val result1: DStream[(String, Int)] = result.updateStateByKey(updateFunc) result1.print() //启动并阻塞 scc.start() scc.awaitTermination() } def updateFunc(currentValues:Seq[Int], historyValues:Option[Int]):Option[Int] = { val newValue: Int = currentValues.sum+historyValues.getOrElse(0) Some(newValue) } }
运行

加入新的文档到监控目录 结果
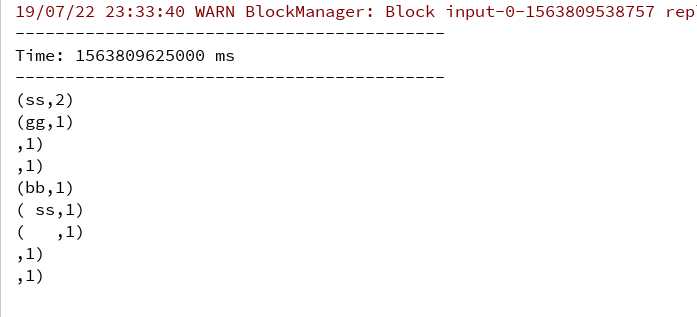
成功结束!
标签:code 阻塞 获取 streaming 切分 tor pack info version
原文地址:https://www.cnblogs.com/BigDataBugKing/p/11228784.html