标签:dep 特征 spl 非对称 png pool splay ref thinking
在《深度学习面试题20:GoogLeNet(Inception V1)》和《深度学习面试题26:GoogLeNet(Inception V2)》中对前两个Inception版本做了介绍,下面主要阐述V3版本的创新点
|
使用非对称卷积分解大filters |
InceptionV3中在网络较深的位置使用了非对称卷积,他的好处是在不降低模型效果的前提下,缩减模型的参数规模,在《深度学习面试题27:非对称卷积(Asymmetric Convolutions)》中介绍过。

end_point = ‘Mixed_6d‘
with tf.variable_scope(end_point):
with tf.variable_scope(‘Branch_0‘):
branch_0 = slim.conv2d(net, depth(192), [1, 1], scope=‘Conv2d_0a_1x1‘)
with tf.variable_scope(‘Branch_1‘):
branch_1 = slim.conv2d(net, depth(160), [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_1 = slim.conv2d(branch_1, depth(160), [1, 7],
scope=‘Conv2d_0b_1x7‘)
branch_1 = slim.conv2d(branch_1, depth(192), [7, 1],
scope=‘Conv2d_0c_7x1‘)
with tf.variable_scope(‘Branch_2‘):
branch_2 = slim.conv2d(net, depth(160), [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_2 = slim.conv2d(branch_2, depth(160), [7, 1],
scope=‘Conv2d_0b_7x1‘)
branch_2 = slim.conv2d(branch_2, depth(160), [1, 7],
scope=‘Conv2d_0c_1x7‘)
branch_2 = slim.conv2d(branch_2, depth(160), [7, 1],
scope=‘Conv2d_0d_7x1‘)
branch_2 = slim.conv2d(branch_2, depth(192), [1, 7],
scope=‘Conv2d_0e_1x7‘)
with tf.variable_scope(‘Branch_3‘):
branch_3 = slim.avg_pool2d(net, [3, 3], scope=‘AvgPool_0a_3x3‘)
branch_3 = slim.conv2d(branch_3, depth(192), [1, 1],
scope=‘Conv2d_0b_1x1‘)
net = tf.concat(axis=3, values=[branch_0, branch_1, branch_2, branch_3])
end_points[end_point] = net
|
重新设计pooling层 |
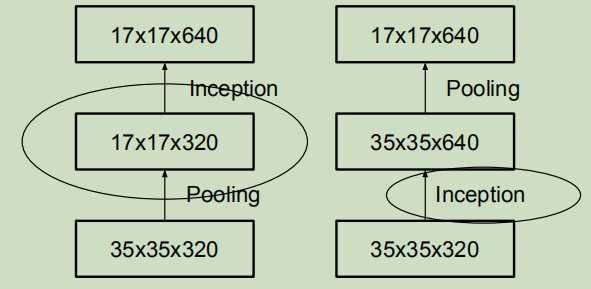
有两种减少网络参数的方式:
左边的做法是直接池化,这会降低网络的表现,因为他对特征图进行了压缩,可能这就是网络的瓶颈;
右边的做法是先增加通道数,再池化,这会增加很多计算量。
所以InceptionV3中使用了如下池化方式:
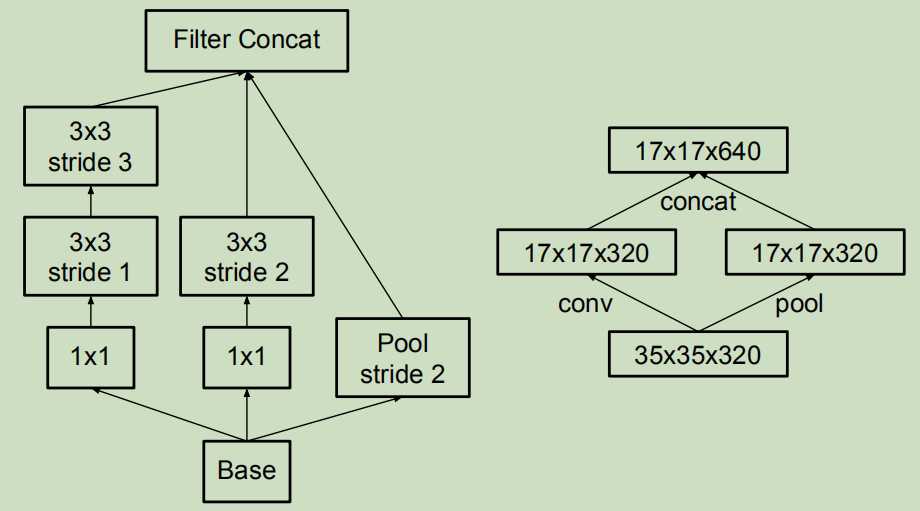
左图和右图是相同的,只不过右图是精简表示的版本
他的做法是一遍卷积,一遍池化,然后将最终结果合并。
这样做既可以减少参数,又可以避免出现表示瓶颈。
|
辅助构造器 |
去掉了第一个辅助构造器。
|
使用标签平滑 |
在《深度学习面试题27:非对称卷积(Asymmetric Convolutions)》中已经讲过,它具有防止过拟合的效果。
|
参考资料 |
Rethinking the Inception Architecture for Computer Vision
GoogLeNet的心路历程(四)
https://www.jianshu.com/p/0cc42b8e6d25
深度学习面试题29:GoogLeNet(Inception V3)
标签:dep 特征 spl 非对称 png pool splay ref thinking
原文地址:https://www.cnblogs.com/itmorn/p/11258955.html
