标签:输入 处理 net 学习 选择性 class 特征 种类 均衡
??最近在研究SSD算法,作为一名目标检测的新手,参考了许多优秀的博客,希望将他们的核心思想记录下来以便日后回忆学习,同时加深自己的理解,以下是我根据一些优秀的博客整理总结的,参考资料注明了其来源。
(1)two-stage方法 顾名思义,算法分为2大步骤,代表算法是RCNN系列的算法,通过选择性搜索(selective search)或者CNN网络(RPN)从特征图上提取可能的存在目标的候选框,然后对这些分类框进行分类与回归,最后给出图中目标的类别及位置。优点是准确度高,缺点因为在第一个步骤提取候选框数量多,在进行分类阶段时要处理每个候选框,因此花费更多时间。
(1)one-stage方法 代表算法是Yolo和SSD系列的算法,算法均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归。算法只有一个大步骤,因此优点是速度快,缺点是,均匀的密集采样的一个重要缺点是训练比较困难,因为正样本与负样本(背景)极其不均衡,导致模型准确度稍低。
??SSD和Yolo都属于one-stage方法,它们的区别在于:
(1) 相比Yolo,SSD采用CNN来直接进行检测,而不是像Yolo那样在全连接层之后做检测。
(2) SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。
(3) SSD采用了不同尺度和长宽比的先验框,Yolo算法缺点是难以检测小目标,而且定位不准,但是这几点重要改进使得SSD在一定程度上克服这些缺点。
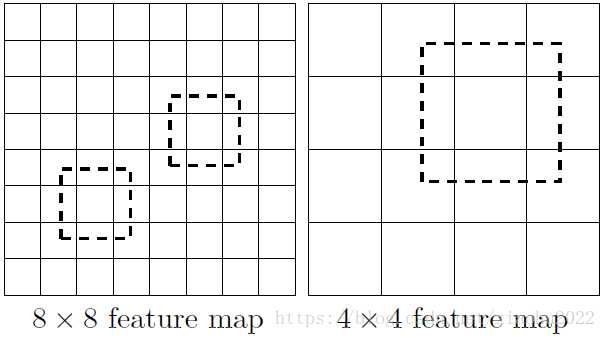
??CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,这正如图3所示,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标,如下图所示,8x8的特征图可以划分更多的单元,但是其每个单元的先验框尺度比较小。
??SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为m×n×p的特征图,只需要采用3×3×p这样比较小的卷积核得到检测值。
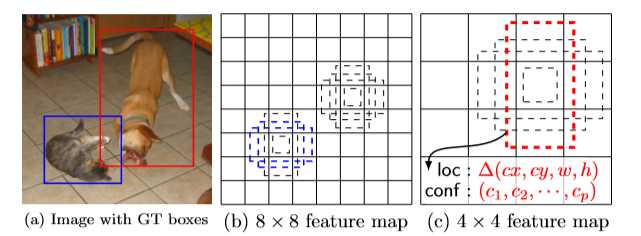
??SSD借鉴了Faster R-CNN中anchor的理念,在特征图每个anchor上设置尺度或者长宽比不同的候选框,预测的边界框(bounding boxes)是以这些候选框为基准的,在一定程度上减少训练难度。一般情况下,每个特征图都会设置多个先验框,如图5所示,可以看到每个anchor使用了4个不同的先验框,图片中猫和狗分别采用最适合它们形状的候选框来进行训练。
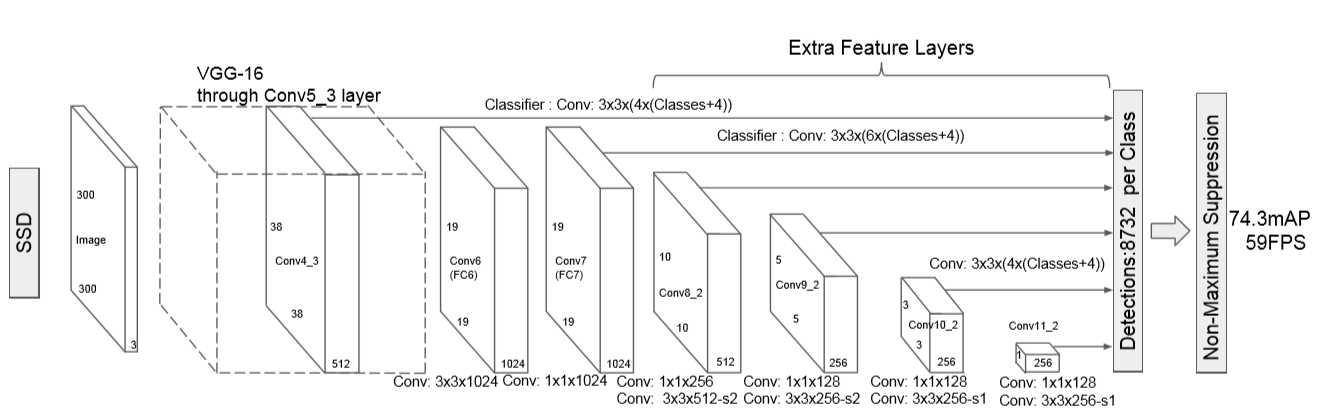
??SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。SSD的网络结构如下图所示。上面是SSD模型,下面是Yolo模型,可以明显看到SSD利用了多尺度的特征图做检测。模型的输入图片大小是300×300
【1】:https://blog.csdn.net/xiaohu2022/article/details/79833786
标签:输入 处理 net 学习 选择性 class 特征 种类 均衡
原文地址:https://www.cnblogs.com/huxiaozhouzhou/p/11259580.html