标签:不同 ddr src strip idt href statistic tracking RoCE
这是一个分析IP代理网站,通过代理网站提供的ip去访问CSDN博客,达到以不同ip访同一博客的目的,以娱乐为主,大家可以去玩一下。
首先,准备工作,设置User-Agent:
#1.headers headers={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0‘}
然后百度一个IP代理网站,我选用的是https://www.kuaidaili.com/free,解析网页,提取其中的ip、端口、类型,并以list保存:
#1.获取IP地址 html=requests.get(‘https://www.kuaidaili.com/free‘).content.decode(‘utf8‘) tree = etree.HTML(html) ip = tree.xpath("//td[@data-title=‘IP‘]/text()") port=tree.xpath("//td[@data-title=‘PORT‘]/text()") model=tree.xpath("//td[@data-title=‘类型‘]/text()")
接着分析个人博客下的各篇文章的url地址,以list保存
#2.获取CSDN文章url地址 ChildrenUrl[] url=‘https://blog.csdn.net/weixin_43576564‘ response=requests.get(url,headers=headers) Home=response.content.decode(‘utf8‘) Home=etree.HTML(Home) urls=Home.xpath("//div[@class=‘article-item-box csdn-tracking-statistics‘]/h4/a/@href") ChildrenUrl=[]
然后通过代理ip去访问个人博客的各篇文章,通过for循环,一个ip将所有文章访问一遍,通过解析"我的博客"网页,获取总浏览量,实时监控浏览量是否发生变化,设置任务数,实时显示任务进度,通过random.randint()设置sleep时间,使得spider更加安全。全代码如下:
import os
import time
import random
import requests
from lxml import etree
#准备部分
#1.headers
headers={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0‘}
#1.获取IP地址
html=requests.get(‘https://www.kuaidaili.com/free‘).content.decode(‘utf8‘)
tree = etree.HTML(html)
ip = tree.xpath("//td[@data-title=‘IP‘]/text()")
port=tree.xpath("//td[@data-title=‘PORT‘]/text()")
model=tree.xpath("//td[@data-title=‘类型‘]/text()")
#2.获取CSDN文章url地址 ChildrenUrl[]
url=‘https://blog.csdn.net/weixin_43576564‘
response=requests.get(url,headers=headers)
Home=response.content.decode(‘utf8‘)
Home=etree.HTML(Home)
urls=Home.xpath("//div[@class=‘article-item-box csdn-tracking-statistics‘]/h4/a/@href")
ChildrenUrl=[]
for i in range(1,len(urls)):
ChildrenUrl.append(urls[i])
oldtime=time.gmtime()
browses=int(input("输入需要访问次数:"))
browse=0
#3.循环伪装ip并爬取文章
for i in range(1,len(model)):
#设计代理ip
proxies={model[i]:‘{}{}‘.format(ip[i],port[i])}
for Curl in ChildrenUrl:
try:
browse += 1
print("进度:{}/{}".format(browse,browses),end="\t")
#遍历文章
response=requests.get(Curl,headers=headers,proxies=proxies)
#获取访问人数
look=etree.HTML(response.content)
Nuwmunber=look.xpath("//div[@class=‘grade-box clearfix‘]/dl[2]/dd/text()")
count=Nuwmunber[0].strip()
print("总浏览量:{}".format(count),end="\t")
‘‘‘
重新实现
#每个IP进行一次查询
if Curl==ChildrenUrl[5]:
ipUrl=‘http://www.ip138.com/‘
response=requests.get(ipUrl,proxies=proxies)
iphtml=response.content
ipHtmlTree=etree.HTML(iphtml)
ipaddress=ipHtmlTree.xpath("//p[@class=‘result‘]/text()")
print(ip[i],ipaddress)
‘‘‘
i = random.randint(5, 30)
print("间隔{}秒".format(i),end="\t")
time.sleep(i)
print("当前浏览文章地址:{}".format(Curl))
if browse == browses:
print("已完成爬取任务,共消耗{}秒".format(int(time.perf_counter())))
os._exit(0)
except:
print(‘error‘)
os._exit(0)
#打印当前代理ip
print(proxies)
实际运行效果图: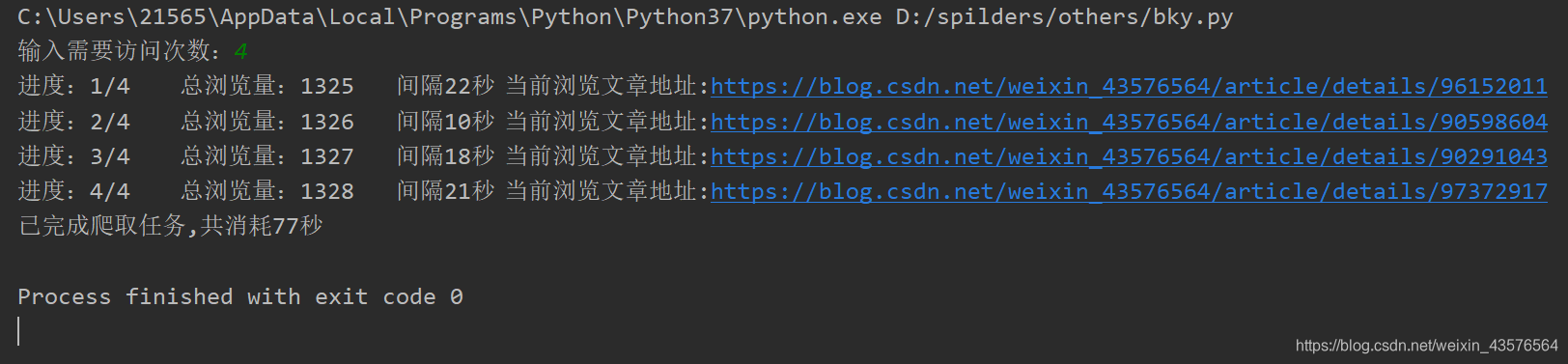
python requests、xpath爬虫增加博客访问量
标签:不同 ddr src strip idt href statistic tracking RoCE
原文地址:https://www.cnblogs.com/yxkj/p/11260383.html