标签:http 哈希 hashmap png treemap shc 对象产生 使用 移动
一直都觉得java集合学得糊里糊涂的,这次要学系统点了。 ——fzj
java集合分为两种:1.value(存值集合) 例如 List(对付顺序的好帮手) 和 Set(注重独一无二的性质)
2.key-value(存键值对集合) 例如 Map(用Key来搜索的专家)
List 是有序的,可以重复的。
Set 是无序的,不可以重复的。(根据equals 和 hashcode 判断,也就是如何一个对象要存储在Set中,必须重写equals 和 hashcode方法)
详细一点:
Collection和Map,是集合框架的根接口。
Collection的子接口:
Set:接口 ---实现类: HashSet、LinkedHashSet
Set的子接口SortedSet接口---实现类:TreeSet
List:接口---实现类: LinkedList,Vector,ArrayList
Collection 接口还有个Queue接口(这个我很少见)
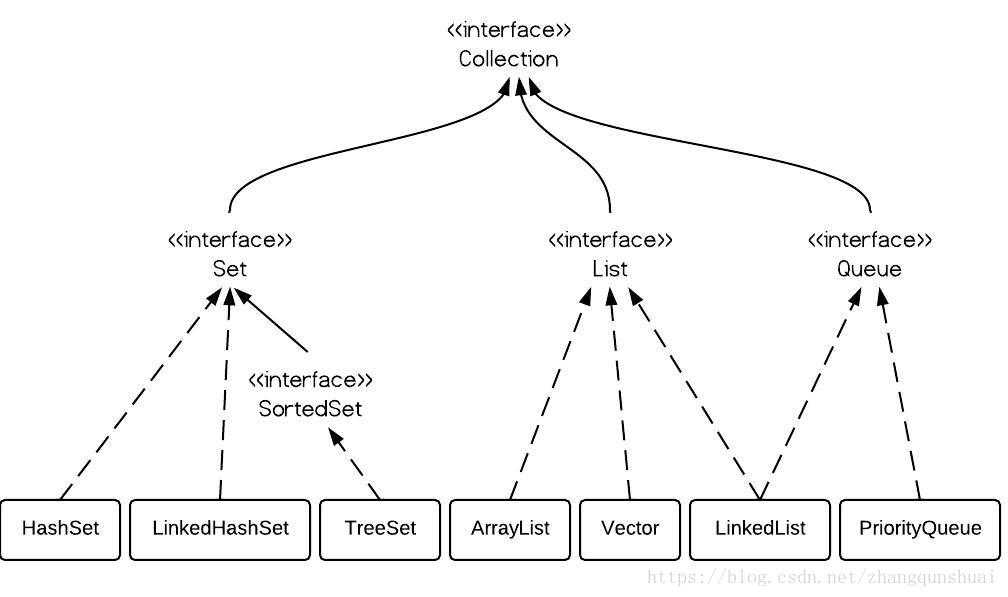
①Queue、list、set 这三者是同一个级别的接口,都是继承了Collection接口。
②SortedSet是一个借口来的,因为里面只有TreeSet(底层结构是红黑树)这一个实现可以用,所以元素一定是有序的。
③LinkedList既可以实现Queue接口,也可以实现List接口。只不过呢,LinkedList实现了Queue接口。
List集合(有序,可重复)
有序列表,允许存放重复的元素;
实现类:
ArrayList:数组实现,查询快,增删慢,轻量级;(线程不安全,效率高)
LinkedList:双向链表实现,增删快,查询慢 (线程不安全,效率高)
Vector:数组实现,重量级 (线程安全、使用少,效率低)
set集合(无序,不可重复)
实现类 :
HashSet
底层数据结构是哈希表。(无序,唯一)
如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals()
LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一
TreeSet
底层数据结构是红黑树。(唯一,有序)
1. 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
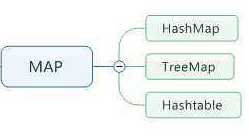 Map接口有三个比较重要的实现类,分别是HashMap、TreeMap、HashTable
Map接口有三个比较重要的实现类,分别是HashMap、TreeMap、HashTable
其中,TreeMap是有序的,HashMap和HashTable是无序的。
HashTable 和HashMap的主要区别:
HashTable的方法是同步的,线程安全但是效率低。父类是Dictionary。不允许null值
HashMap的方法不是同步的,线程不安全但是效率高。父类是AbstractMap。允许null值(key和value都允许)
1.ArrayList和LinkedList的区别以及使用场景:
ArrayList底层使用的是数组。数组具有索引查询特定元素特别快,而插入删除修改比较慢(数组的内存中是一块连续的内存,如果插入或删除是需要移动内存)。
LinkedList底层使用的是链表。链表不要求内存是连续的,在当前元素存放下一个或上一个元素地址,查询时需要从头部开始,一个一个的找,所以查询效率低。插入时不需要移动内存,只需改变引用指向即可。所以插入或者删除的效率高。
ArrayList 使用在查询比较多,但是插入和删除比较少的情况,而LinkedList使用再查询比较少而插入和删除比较多的情况。
2.HashSet如何检查重复
当把对象加入 HashSet时,它会先计算对象的HashCode值来判断对象加入的位置,同时也将其他对象的HashCode的值作为比较,比较完成后没有发现相符的HashCode,HashSet会假设对象没有重复出现。但是如果发现有相同的HashCode值的对象,就回调用equals()方法检查HashCode相等的对象是否真的相同。如果两者相同,HashSet就不会让其加入操作成功。
hashCode()与equals()的相关规定:
3.如何选用集合
这个主要是根据需求来选用。再根据每个集合的特点来使用。在网上看到一段很好的话,在这里引用
“主要根据集合的特点来选用,比如我们需要根据键值获取到元素值时就选用Map接口下的集合,需要排序时选择TreeMap,不需要排序时就选择HashMap,需要保证线程安全就选用ConcurrentHashMap.当我们只需要存放元素值时,就选择实现Collection接口的集合,需要保证元素唯一时选择实现Set接口的集合比如TreeSet或HashSet,不需要就选择实现List接口的比如ArrayList或LinkedList,然后再根据实现这些接口的集合的特点来选用。”
Collection
SET
Map
【感觉写的不多,但是这个我这个小白,也就只能到这里了。立个flag,后面再更新】
——fzj
标签:http 哈希 hashmap png treemap shc 对象产生 使用 移动
原文地址:https://www.cnblogs.com/fzzzjjj/p/11262331.html