标签:ESS 请求 开始 test ring 笛卡尔积 规则 selection left join
本章涉及的内容是TiDB的计算层代码,就是我们编译完 TiDB 后在bin目录下生成的 tidb-server 的可执行文件,它是用 go 实现的,里面对 TiPD 和 TiKV实现了Mock,可以单独运行;
用explain语句可以看到一条sql在TiDB中生成的最终执行计划,例如:我们有一条关联子查询: select * from t1 where t1.a in (select t2.a from t2 where t2.b = t1.b);
tidb> explain select * from t1 where t1.a in (select t2.a from t2 where t2.b = t1.b); +--------------------------+-------+------+--------------------------------------------------------------------------------------------+ | id | count | task | operator info | +--------------------------+-------+------+--------------------------------------------------------------------------------------------+ | HashLeftJoin_9 | 4.79 | root | semi join, inner:TableReader_15, equal:[eq(test.t1.b, test.t2.b) eq(test.t1.a, test.t2.a)] | | ├─TableReader_12 | 5.99 | root | data:Selection_11 | | │ └─Selection_11 | 5.99 | cop | not(isnull(test.t1.a)), not(isnull(test.t1.b)) | | │ └─TableScan_10 | 6.00 | cop | table:t1, range:[-inf,+inf], keep order:false, stats:pseudo | | └─TableReader_15 | 5.99 | root | data:Selection_14 | | └─Selection_14 | 5.99 | cop | not(isnull(test.t2.a)), not(isnull(test.t2.b)) | | └─TableScan_13 | 6.00 | cop | table:t2, range:[-inf,+inf], keep order:false, stats:pseudo | +--------------------------+-------+------+--------------------------------------------------------------------------------------------+
最终的sql算子差不多是这个样子的:
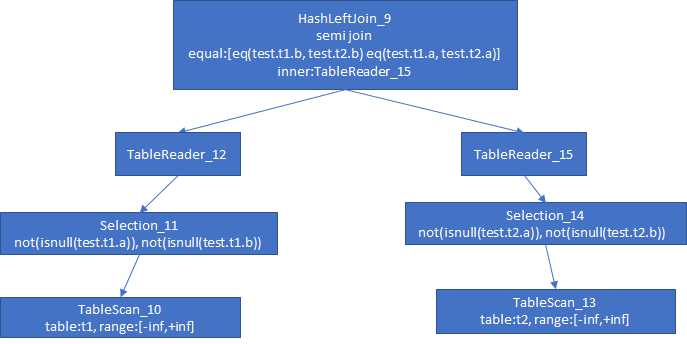
上面是一个物理查询计划树,顶层算子是Join算子,t1表和t2表的数据关联操作用的是Hash Join,因为只返回左表(Outer Plan)的数据,所以用了左外连接(Left Join); Join条件是 t1.b = t2.b,t1.a = t2.a,其中内表数据取自 TableReader_15---就是t2表的数据,t2表作为 Inner Plan的数据;
下层左右两边的算子类似,都是TableReader接了Selection算子,Selection算子负责过滤掉空数据;底层算子是2个最基本的扫表算子(TableScan),分别扫 t1 和 t2 的数据,返回给上层算子;
TiDB代码中,explain语句和select语句类似,都是这样的处理逻辑:
clientConn.handleQuery---处理mysql客户端来的请求
TiDBContext.Execute
session.execute
session.ParseSQL---解析SQL
Compiler.Compile---遍历SQL语法树,生成逻辑计划树和物理计划树
session.executeStatement
clientConn.writeResultset
clientConn.writeChunks
ResultSet.Next---Next函数驱动数据行的获取
clientConn.writePacket---将数据写回客户端
explain语句结果生成的代码在这里:
ExplainExec.Next
ExplainExec.generateExplainInfo
Explain.RenderResult
Explain.explainPlanInRowFormat---遍历物理执行计划树,格式化输出
Explain.explainPlanInRowFormat 会从根节点开始递归的访问PhysicalPlan和子树,遍历物理执行计划树,生成explain的结果集;
explain显示的信息是最终优化生成的执行计划;
我们看看中间生成的执行计划是怎样的:
sql的解析和生成逻辑计划树的代码在这里:
func Optimize(ctx sessionctx.Context, node ast.Node, is infoschema.InfoSchema) (plannercore.Plan, error) {
//根据sql语法树(ast.Node)生成逻辑执行计划(LogicalPlan)
func (b *PlanBuilder) Build(node ast.Node) (Plan, error) {
func (b *PlanBuilder) buildExplainPlan(targetPlan Plan, format string, analyze bool, execStmt ast.StmtNode) (Plan, error) {
func (b *PlanBuilder) buildSelect(sel *ast.SelectStmt) (p LogicalPlan, err error) {
// DoOptimize optimizes a logical plan to a physical plan.
//将逻辑执行计划树(LogicalPlan)转为物理执行计划树(PhysicalPlan)
func DoOptimize(flag uint64, logic LogicalPlan) (PhysicalPlan, error) {
buildExplain 调用 buildSelect 来生成 select 语句的逻辑执行计划树 (LogicalPlan),接着调用DoOptimize来进行优化;比如类似这样的优化:对关联子查询进行改写,应用关系代数的一些规则,将 in子句 转为 semi join,因为 semi join 可以有多种方式进行高效的数据集连接操作;
然后,我们看看优化之前的执行计划:
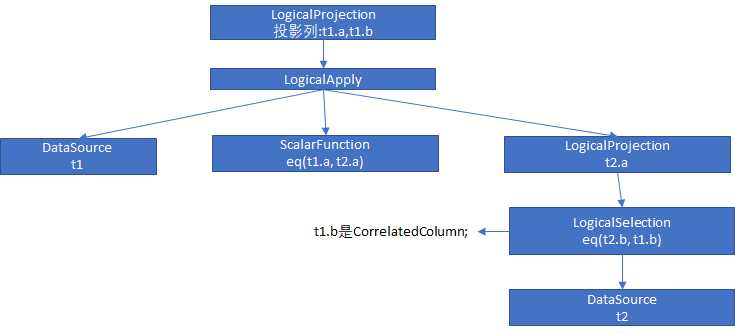
这个执行计划大体是这样的,执行计划的根节点是一个投影算子(Projection),取表 t1 的两个列 t1.a 和 t1.b;根节点下面是一个 Apply 算子,Apply 算子是为了满足关联子查询的需要,子查询语句中用到了外面的结果集,就像我们示例的 sql,子查询里面的选择算子是 t2.b = t1.b,t1.b 就是关联到外部执行计划的列;
Apply关联了两个算子,一个是上图中左边的DataSource,这个DataSource算子是对t1的扫表操作;另一个算子是上图中的 下面那个 LogicalProjection 算子,这个算子下面接了选择算子(LogicalSelection),相当于执行 t1.b = t2.b 的操作,然后是扫表算子,对 t2 进行扫表;
相对于我们这条语句,Apply算子大概是这样的执行步骤:
从扫表算子(TableScan)中获取一条 t1 的数据;
从投影算子(Projection)获取一条 t2 的数据;
投影算子调用选择算子(Selection);
选择算子拿的外部关联的数据 t1.a;
选择算子对 t2 扫表,条件是 t2.b = t1.b,获取 t2.a;其中,t1.b 相对于Apply 算子是外部计划的列;
执行一个标量算子,判断 t1.a = t2.a;不管 t2.a 的记录有多少,只要有一条满足,即成功;
可以看到,对关联子查询,需要执行嵌套循环(NestedLoop),对 t1 的每条记录循环,传给 Apply算子, Apply算子再用这条记录去 t2 表对每条记录执行循环;
而我们看到 explain 语句显示的最终执行计划,是用 semi join 来改写的,t1 和 t2 用 semi join 来连接,连接条件是 t1.a = t2.a and t1.b = t2.b,连接方式是左半连接;
说的直白一点就是:t1 和 t2 做 Left Outer Join,然后对结果集去重;
semi join有很多种策略,mysql支持差不多5种 Semi Join;
TiDB执行计划优化代码在这里:
// DoOptimize optimizes a logical plan to a physical plan.
func DoOptimize(flag uint64, logic LogicalPlan) (PhysicalPlan, error) {
......
logic, err := logicalOptimize(flag, logic)
......
physical, err := physicalOptimize(logic)
......
finalPlan := postOptimize(physical)
return finalPlan, nil
}
调用 PlanBuilder.buildSelect 生成的逻辑计划(LogicalPlan),会传到 DoOptimize 进行优化,DoOptimize主要做了两件事:
一件事做基于规则的优化(RBO),应用关系代数规则,对关系代数进行等价改写,生成更优的执行计划,例如:一些简单的关系代数转换---谓词下推,常量折叠,子查询展开,投影合并等等;或者一些更高级的关系代数转换,子查询转 semi join,子查询转各种连接,等等;基本上涉及到数据集连接或者有子集嵌套的sql优化起来难度要大很多;要应用到的关系代数规则也更多;
另一件事是做基于代价的优化(CBO),这个我也不懂 ??;
在传统数据库如 mysql, oracle中,这些优化做完之后已经是极限了,但是在NewSQL中,优化空间还有,例如:谓词下推,列剪裁这种简单的规则,可以从计算节点下推到KV节点上;再比如:NewSQL中的KV是多副本和Range分片的,这样可以将计算分布在不同的节点上;
传统数据库都是基于关系代数设计的,所以对集合连接,集合查询非常友好;但是随着数据的增长,数据库架构上不得不使用分片来解决针对海量数据的读写能力;
分片可以获得优良的单条数据的读写能力,但是失去了数据库的事务性;比起牺牲事务性,更大的问题是牺牲了传统的关系代数运算,分片之后,多个表的数据连接变得异常困难,对于子查询再嵌套子查询,几乎是无法完成的任务;
为了折衷,大部分企业在分片的数据库集群下游接了一个OLAP集群,来满足传统意义上的关系代数操作;
关系代数最早是由早期的SQL提出的;
后来各种大数据平台Hadoop,HBase和 MapReduce 计算框架出现后,碰到很多数据集和数据过滤的问题,不得不通过关系代数来解决,于是人们将目光转回到了传统的关系代数上,Hive,Calcite这种支持SQL的外挂引擎出现了,这些引擎实现了SQL的解析和规则优化,我们只需要将算子应用到底层的数据存储就可以了;
结尾;
附:关系代数几个常用的符号,这些符号可以对应到SQL里面的算子,算子优化是通过关系代数的等价转换来进行的:
σF(R):对集合R选择;--- 相当于 where t1.b=t2.b;
ΠA(R):对集合R投影;--- 相当于 select t1.a, t1.b;
R×S:连接;这是关系代数最重要的操作,连接有很多种,自然连接,左连接,右连接,笛卡尔积,Semi Join 等等,子查询这种场景通常被转换为了各种连接;
R A⊗ E:Apply,对R中的每条记录,代入E中进行运算,然后把记录做各种连接;
肤浅的聊聊关联子查询,数据集连接,TiDB代码,关系代数,等等
标签:ESS 请求 开始 test ring 笛卡尔积 规则 selection left join
原文地址:https://www.cnblogs.com/lijingshanxi/p/11283825.html