标签:回顾 转化 emd 识别 完全 另一个 操作 部分 评估
这篇文章主要总结文本中的对抗样本,包括器中的攻击方法和防御方法,比较它们的优缺点。
最后给出这个领域的挑战和发展方向。
对抗样本有两个核心:一是扰动足够小;二是可以成功欺骗网络。
所有DNNs-based的系统都有受到对抗攻击的潜在可能。
很多NLP任务使用了DNN模型,例如:文本分类,情感分析,问答系统,等等。

以上是一个对抗攻击实例。除此之外,对抗样本还会毒害网络环境,阻碍对恶意信息[21]-[23]的检测。
除了对比近些年的对抗攻击和防御方法,此外,文章还会讲CV和NLP中该领域的方法(包括评价方法)为何不通用,以及测试和验证的重要性。
本文结构:首先在第二节中给出一些关于对抗性例子的背景知识。在第三节中,回顾了文本分类和其他实际NLP任务的对抗性攻击。第五节和第六节主要介绍了以防御为中心的研究,一是对文本中已有的防御方法的研究,二是从另一个角度研究如何提高DNNs的鲁棒性。本文的讨论和结论见第七和第八节。
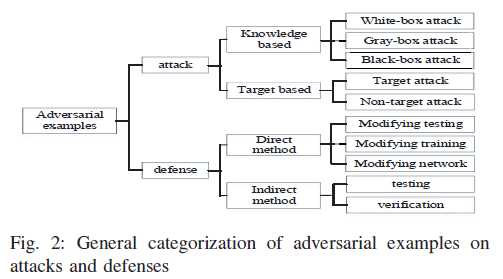
以文本分类问题为例。
黑盒。不需要了解网络结构或只了解一点点。
白盒。完全理解目标模型,包括架构,各种参数和权重。
黑盒和白盒的方法都不能改变训练数据和模型。
定向攻击。对抗样本的目标是被成功分到类别t(既定的类别)。主要是来增加类别t的置信度。
不定向攻击。目标只是将样本分到错误的类别(这个类别不特定)。目标是欺骗模型,主要是降低真实类别的置信度。
主要的两种方法)、总结如下:
为了保护基于DNN的系统免受对抗攻击,评估这些系统在最坏情况下的鲁棒性,这导致了两种防御方向。
一种是通过修改测试、训练或模型来直接防御对抗性攻击。直接法上常用的方法有对抗性样本的检测、对抗性训练和损失函数的变化。
二是通过提高DNNs的鲁棒性,包括测试和验证方法。
在图像中,几乎所有最近关于对抗性攻击的研究都采用Lp距离作为距离度量来量化对抗性实例的不可感知性和相似性。Lp距离的广义项为:
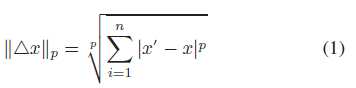
△x表示扰动。这个方程是一组距离的定义其中p可以是0 1∞等等。特别是L0 [28] - [30] L2[30] -[33]和L∞[7],[8]、[33]-[36]是对抗性图像中最常用的三种规范。
L0距离计算修改前后改变的像素数。它看起来像编辑距离,但它可能不能直接在文本中工作。因为文本中单词改变的结果是不同的。有些与原文相似,有些则相反,尽管它们之间的距离是相同的。
L2距离是欧几里德距离。最初的欧几里德距离是欧几里德空间中一点到另一点的直线。当图像、文本等映射到它时,欧几里得空间就变成了度量空间,用来计算以向量表示的两个对象之间的相似性。
L∞距离表示最大变化量,如下:
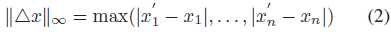
虽然L∞距离被认为是一些工作中使用的最优距离度量,但在文本中可能会失败。修改后的单词可能不存在于预先训练好的字典中,因此它们被认为是未知单词,它们的单词向量也是未知的。因此,L∞距离很难计算。
因此,文本中需要可用的评价标准,但和图像领域是大有不同的。
为了克服对抗性文本中的度量问题,本文提出了一些度量方法,并对其中五个已在相关文献中得到证明的度量方法进行了描述。
欧几里得距离
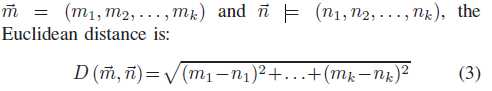
相比文本欧氏距离更多地用于度量对抗性图像[30]-[33],叫做L2范数或L2距离。
余弦相似度
余弦相似度也是一种基于词向量的语义相似度计算方法,通过两个向量夹角的余弦值来计算。与欧氏距离相比,余弦距离更关注两个向量方向的不同。两个向量的方向越一致,相似性越大。对于给定的两个字向量~m和~n,余弦相似度为
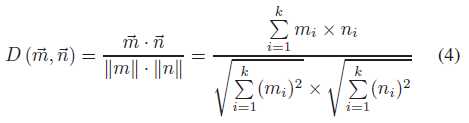
但是限制是单词向量的维数必须相同。
Jaccard相似性系数。对于两个给定的集合A和B,它们的Jaccard相似系数为:
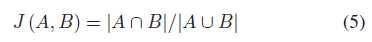
0 ≤ J(A,B) ≤ 1,J(A,B)的值越接近1,它们就越相似。在文本中,交集A∩B是指例子中相似的词,并集A∪B是所有词(without duplication)。
单词移动距离(WMD)
WMD[39]是Earh Mover‘s Distance(EMD)[40]的一种变化。它可以用来衡量两个文本文档之间的差异,依赖于从一个文档的嵌入词到另一个文档的移动距离。换句话说,WMD可以量化文本之间的语义相似性。同时,欧氏距离也用于WMD的计算。
编辑距离
编辑距离是通过将字符串转换为另一个字符串来度量最小修改量的一种方法。它越高,就越不相似。它可以应用于计算生物学和自然语言处理。Levenshtein距离[41]也称为编辑距离,在[24]的工作中使用插入、删除、替换操作。(leetcode有一道类似的题之后再仔细看下)
这些度量方法用于不同的情况。向量上采用欧氏距离、余弦距离和WMD。在文本中,对抗样本和干净样本应该转化为向量。然后用这三种方法计算它们之间的相似度。Jaccard相似系数和编辑距离可以直接用于不需要形式转换的文本输入。
为了使需要数据的人更容易访问数据,文章收集了一些近年来应用于NLP任务的数据集。
下载地址:
1http://www.di.unipi.it/ gulli/AG corpus of news articles.html
2https://wiki.dbpedia.org/services-resources/ontology
3http://snap.stanford.edu/data/web-Amazon.html
4 https://sourceforge.net/projects/yahoodataset/
5https://www.yelp.com/dataset/download
6http://www.cs.cornell.edu/people/pabo/movie-review-data/
7http://mpqa.cs.pitt.edu/
8http://ai.stanford.edu/ amaas/data/sentiment/
9https://nlp.stanford.edu/projects/snli/
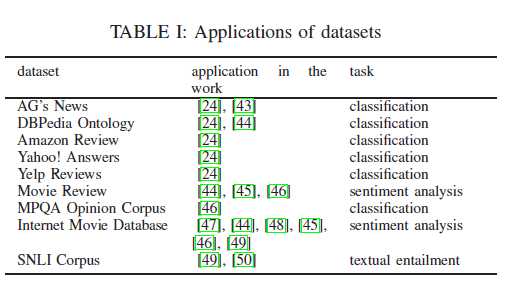
表I是数据的应用。研究工作中使用的其他数据集列在附录X中。
描述
AG’s News1: 由一个名为ComeToMyHead的学术新闻搜索引擎从2000多个新闻源中收集了超过100万篇文章的新闻集。所提供的db版本和xml版本可以下载用于任何非商业用途。
DBPedia Ontology2:包含来自各种Wikimedia项目中创建的信息的结构化内容。它有超过68个类,2795个不同的属性,现在这个数据集中包含了400多万个实例。
Amazon review 3:从1995年6月到2013年3月,Amazon review数据集拥有近3500万条评论,包括产品和用户信息、评分和纯文本评论。它被200多万种产品中的600多万用户收集,并被分为33个类,大小从KB到GB不等。
Yahoo! answer 4:语料库包含400万个问题及其答案,可以方便地在问答系统中使用。此外,还可以用一些主类构造主题分类数据集。
Yelp Reviews5:提供的数据由Yelp提供,以使研究人员或学生能够开发学术项目。它包含470万条用户评论,其中包含json文件和sql文件的类型。
Movie Review(MR)6:这是一个有标记的数据集,涉及情感极性、主观评分和带有主观地位或极性的句子。可能因为它是由人类标记的,所以这个数据集的大小比其他数据集要小,最大为几十MB。
MPQA Opinion Corpus7: 多视角问答(Multi-Perspective Question answer, MPQA),语料库收集了各种各样的新闻来源,并为观点或其他私有状态进行注释。MITRE公司为人们提供了三种不同的版本。版本越高,内容越丰富。
Internet Movie Database (IMDB)8: IMDBs是从互联网上抓取的,包括5万条正面和负面的评论,平均评论长度近200字。它通常用于二元情绪分类,包括比其他类似数据集更丰富的数据。IMDB还包含附加的未标记数据、原始文本和已处理的数据。
SNLI Corpus9:斯坦福自然语言推理(SNLI)语料库是一个人工标注数据的集合,主要用于自然语言推理(NLI)任务。有近50万对句子是人类在一定的语境中写成的。关于这个语料库的更多细节可以在Samuel等人的研究中看到。
研究人员通常通过准确率或错误率来评估他们对目标模型的攻击。
正确率:输入正确识别率。正确率越低,对抗性的例子越有效。
此外,一些研究人员更喜欢利用攻击前后的准确性差异,因为它可以更直观地显示攻击的效果。这些标准也可以用来抵御对抗性样本。
由于对抗性攻击的目的是使DNNs行为失当,因此可以从广义上将其视为一个分类问题(正确或错误的判断)。近年来,文本中具有代表性的对抗性攻击大多与分类任务有关。在本节中,我们根据分类的类型将文本中现有的大多数对抗性攻击分为三个部分。下面给出了每种攻击方法的技术细节和相应的注释,以便读者更清楚地了解这些攻击方法。
Towards a Robust Deep Neural Network in Text Domain A Survey
标签:回顾 转化 emd 识别 完全 另一个 操作 部分 评估
原文地址:https://www.cnblogs.com/shona/p/11305232.html