标签:属性 模糊 优化 div reg ast tin 操作 mic
映射关系:
表名 --------------------》类名
字段--------------------》属性
表记录-----------------》类实例化对象
ORM的两大功能:
操作表:
- 创建表
- 修改表
- 删除表
操作数据行:
- 增 删 改 查
ORM利用pymysql第三方工具链接数据库
Django默认的是sqlite数据库

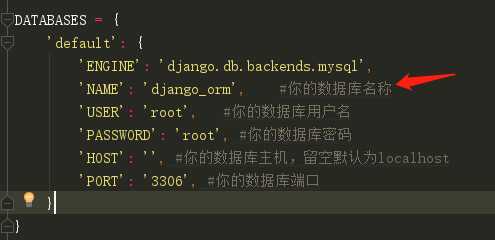
1、settings.py 配置
DATABASES = { ‘default‘: { ‘ENGINE‘: ‘django.db.backends.mysql‘, ‘NAME‘: ‘django_orm‘, #你的数据库名称 ‘USER‘: ‘root‘, #你的数据库用户名 ‘PASSWORD‘: ‘root‘, #你的数据库密码 ‘HOST‘: ‘‘, #你的数据库主机,留空默认为localhost ‘PORT‘: ‘3306‘, #你的数据库端口 } }
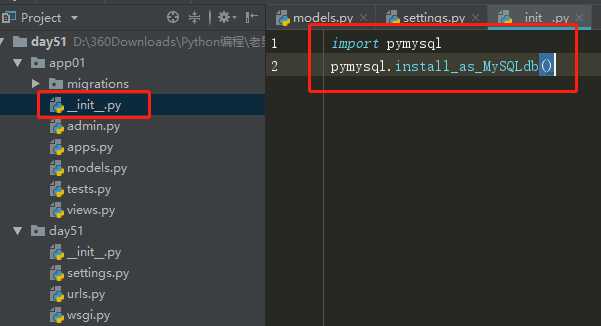
2、在项目文件夹下 __init__.py 导入pymysql
3、命令行中打印 SQL语句 ---> 配置在settings.py 中

LOGGING = { ‘version‘: 1, ‘disable_existing_loggers‘: False, ‘handlers‘: { ‘console‘:{ ‘level‘:‘DEBUG‘, ‘class‘:‘logging.StreamHandler‘, }, }, ‘loggers‘: { ‘django.db.backends‘: { ‘handlers‘: [‘console‘], ‘propagate‘: True, ‘level‘:‘DEBUG‘, }, } }
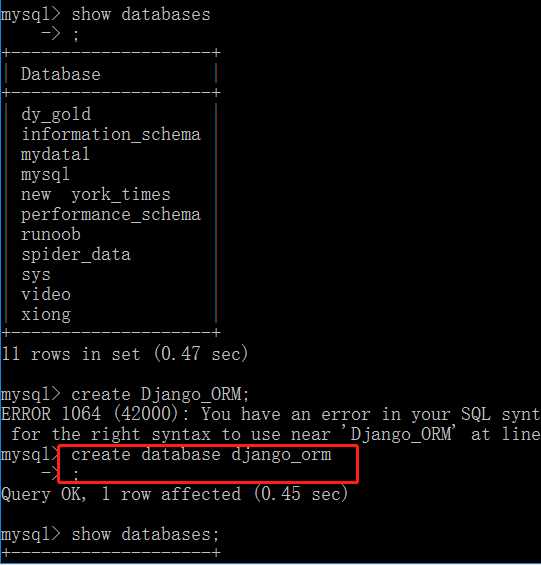
Django没办法帮我们创建数据库,只能我们创建完之后告诉它,让django去链接
python manage.py makemigrations 创建脚本
python manage.py migrate 迁移
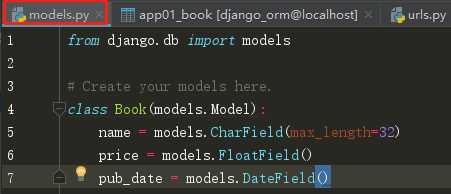
执行成功之后 项目文件夹app01 的migrations 文件夹下生成一个 xxx_initial.py 文件
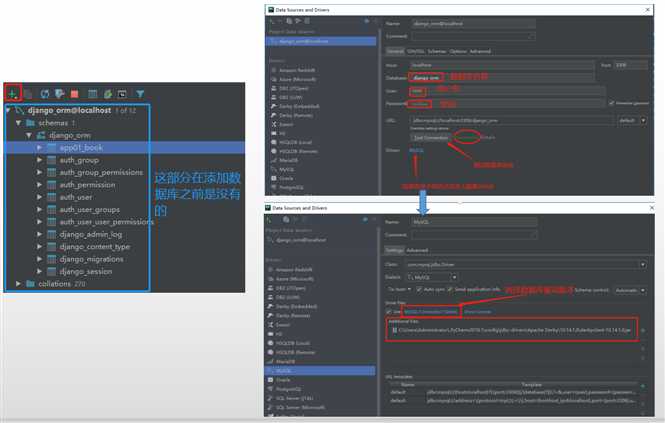
配置:
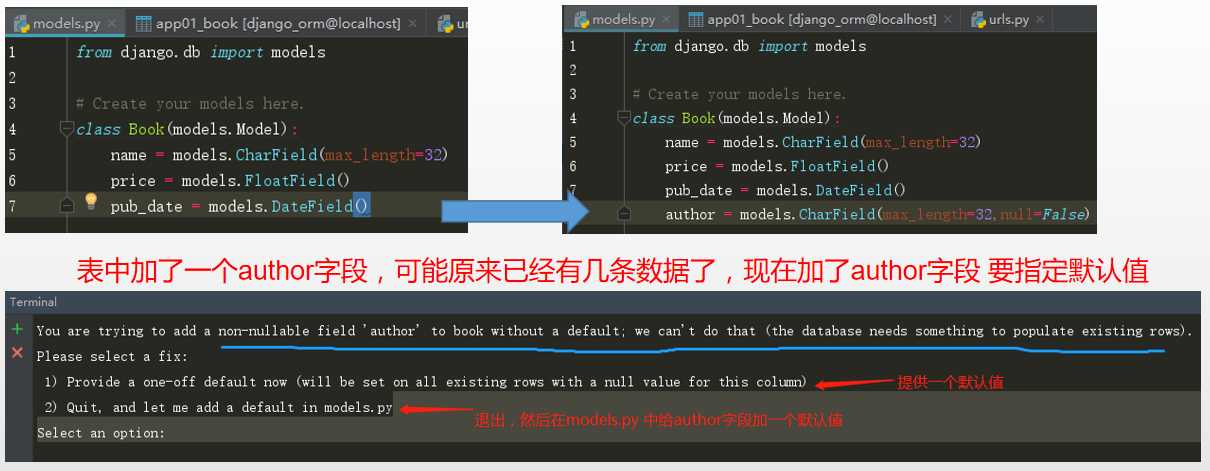
修改表中字段,重新初始化
注意:想在Python print 显示对应的sql 语句控制命令,需要在 settings.py 加上日志记录部分:
LOGGING = { ‘version‘: 1, ‘disable_existing_loggers‘: False, ‘handlers‘: { ‘console‘:{ ‘level‘:‘DEBUG‘, ‘class‘:‘logging.StreamHandler‘, }, }, ‘loggers‘: { ‘django.db.backends‘: { ‘handlers‘: [‘console‘], ‘propagate‘: True, ‘level‘:‘DEBUG‘, }, } }
# 增加数据方式一: # b = Book(name="python基础",price=99,pub_date="2016-7-9",author="xiong") # b.save() #增加数据方式二:(推荐使用) Book.objects.create(name="Linux基础",price=59,pub_date="2013-7-9",author="jack")
Book.objects.filter(author="alex").delete()
# 方法一(推荐) Book.objects.filter(id=2).update(author="tom") #方法二 # author = Book.objects.get(id=2) # author.name = "oldwang" # author.save() # return HttpResponse("修改成功")
update() 是 QuerySet 对象的方法 ,update() 会根据筛选条件 只针对这一个属性进行修改,
save() 则会对筛选对象的所有属性赋值(效率低,不推荐用)
# 查询相关API: ## <1>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象(返回一个可迭代对象) ## <2>all(): 查询所有结果(返回一个可迭代对象) ## <3>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 #-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()-------- ## <4>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 ## <5>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 ## <6>order_by(*field): 对查询结果排序 # <7>reverse(): 对查询结果反向排序 ## <8>distinct(): 从返回结果中剔除重复纪录 ## <9>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 ## <10>count(): 返回数据库中匹配查询(QuerySet)的对象数量。 # <11>first(): 返回第一条记录,是一条数据,返回一个实例对象 # <12>last(): 返回最后一条记录 # <13>exists(): 如果QuerySet包含数据,就返回True,否则返回False。
实例练习:
#查询所有结果(返回一个可迭代对象)-QuerySet 可以切片 # book_list = Book.objects.all() # print(book_list) #<QuerySet [<Book: java>, <Book: python基础>, <Book: Linux基础>, <Book: 三体>]> # print(book_list[0]) #java #取前3条 # book_list = Book.objects.all()[:3] # 取第1 3 5 7 。。。条 # book_list = Book.objects.all()[::2] # 倒着取 # book_list = Book.objects.all()[::-1] # 取第一条 最后一条 # book_list = Book.objects.first() # book_list = Book.objects.all()[0] # 相当于first 用法 # book_list = Book.objects.last() # book_list = Book.objects.all()[-1] # 相当于last 用法 #filter 取出的都是可迭代对象,虽然结果是只有一项的QuerySet列表 # book_list = Book.objects.filter(id=2) # get 取出的就是一条对象,不可迭代 # book_list = Book.objects.get(id=2) # book_list = Book.objects.get(author="alex") #如果找不到该作者或找到的作者对应多个 都会报错 # 只想找某个对象对应的某个属性 # book_list = Book.objects.filter(author="alex").values("name") #<QuerySet [{"name":"python"},{"name":"java"}]> #推荐使用 values() # ret1 = Book.objects.filter(author="alex").values("name","price") #<QuerySet [{"name":"python","price":65},{"name":"java","price":49}]> # # book_list = Book.objects.filter(author="alex").values_list("name","price") #<QuerySet [("python",65),("java",49)]> # print(ret1) # print(book_list) # 按照某个values() 查询 对相同结果进行去重 # ret2 = Book.objects.filter(author="tom").values("name").distinct() # ret3 = Book.objects.filter(author="tom").values("name").distinct().count() # print("ret===>",ret2,ret3) # 模糊查询 ---> 了不起的双下划线 __ # 查找价格大于60的书 # book_list = Book.objects.filter(price__gt = 60) # 查找价格大于等于60的书 # book_list = Book.objects.filter(price__gte=60) # 查找价格小于等于60的书 # book_list = Book.objects.filter(price__lte=60) # 查找作者为 [‘alex‘,‘xiong‘] book_list = Book.objects.filter(author__in=[‘alex‘,‘xiong‘]) # 查找id范围为[2,4] book_list = Book.objects.filter(id__range=[2,4]) # 查找书名包含 p字符 不区分大小写 book_list = Book.objects.filter(name__icontains="p") print(book_list) return render(request,"index.html",{"book_list":book_list})
#---------------了不起的双下划线(__)之单表条件查询---------------- # models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 # # models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 # models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in # # models.Tb1.objects.filter(name__contains="ven") # models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 # # models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and # # startswith,istartswith, endswith, iendswith,
# 向Book表添加记录 # 方法1 Book.objects.create(name="PyQt5入门到精通", price=89, pub_date="2017-6-1", publish_id=1) # 方法2 publish_obj = Publish.objects.filter(name="机械工业出版社")[0] Book.objects.create(name="数据结构与算法", price=99, pub_date="2016-3-1", publish=publish_obj)
# 查询 机械工业出版社出版过的所有书 #1、正向查找 :查 python入门到精通 这本书的出版社信息 # pub_obj = Publish.objects.get(name="机械工业出版社") # book_obj = Book.objects.filter(publish=pub_obj) # print(book_obj.values("name","price")) #2、反向查找: 查 机械工业出版社 出版的书 pub_obj = Publish.objects.get(name="机械工业出版社") book_obj = pub_obj.book_set print(book_obj.all())

# 需求:查询出版过Python类型书籍的出版社信息 # 方法一:正向 查找出版社 就对出版社对象操作 Publish.objects # ret1 = Publish.objects.filter(book__name__icontains="python").values("name","city") # print(ret1) # 方法二:反向 通过Python书 找对应出版社 # ret2 = Book.objects.filter(name__icontains="python").values("publish__name") # print(ret2) # 需求:查询机械工业出版社出版过的所有书 #方法一:正向 # ret3 = Book.objects.filter(publish__name="机械工业出版社").values("name","price") # print(ret3) # 方法二:反向 # ret4 = Publish.objects.filter(name="机械工业出版社").values("book__name","book__price") # print(ret4) # 需求:查询位于北京的出版过出版过的所有书 # 方法一:正向 # ret5 = Book.objects.filter(publish__city="北京").values("name","price") # print(ret5) # 方法二:反向 # ret6 = Publish.objects.filter(city="北京").values("book__name","book__price") # print(ret6) # 需求:2018年出版的书的出版社信息 # 方法一:正向 # ret7 = Publish.objects.filter(book__pub_date__gte="2018-1-1",book__pub_date__lte="2018-12-31").values("name","city") # print(ret7) # 方法二:反向 # ret8 = Book.objects.filter(pub_date__gte="2018-1-1",pub_date__lte="2018-12-31").values("name","price") # print(ret8)
# 需求:查找 python入门到精通 这本书对应的作者 # book_obj1 = Book.objects.filter(name="python入门到精通") # author_obj1 = book_obj1[0].author # print(author_obj1.all()) # 需求:id=2 作者出版的书 # author_obj2 = Author.objects.get(id=2) # print(author_obj2.book_set.all()) #向第三张关系表中 添加记录 # 需求:给python入门到精通 这本书添加所有作者 # book_obj3 = Book.objects.filter(name="python入门到精通") # author_objs1 = Author.objects.all() #是一个QuerySet集合 # book_obj3[0].author.add(*author_objs) #author_objs是一个QuerySet集合要加与一个* # author_obj = Author.objects.get(id=3) # 是一个对象 # book_obj3[0].author.add(author_objs) # author_obj是一个对象 # 向第三张关系表中 移除记录 # 需求:给 python入门到精通 这本书 移除掉作者 1 # book_obj4 = Book.objects.filter(name="python入门到精通") # author_objs2 = Author.objects.get(id=1) # 是一个QuerySet集合 # book_obj4[0].author.remove(author_objs2) # author_objs是一个QuerySet集合要加与一个*
# 需求1:杜甫出过的书及价格 # 方法一:正向 # ret1 = Book.objects.filter(author__name="杜甫").values("name","price") # print(ret1) # 方法二:反向 # ret2 = Author.objects.filter(name="杜甫").values("book__name","book__price") # print(ret2) # 需求2:Linux运维 这本书的作者 # 方法一:正向 # ret3 = Author.objects.filter(book__name="Linux运维").values("name","age") # print(ret3) # 方法二:反向 # ret4 = Book.objects.filter(name="Linux运维").values("author__name","author__age") # print(ret4)
需求1:求所有书的价格 和 平均值 书数目统计 书价格最大 最小值
# 需求1:求所有书的价格 和 平均值 书数目统计 书价格最大 最小值 # ret_sum = Book.objects.all().aggregate(Sum("price")) # print(ret_sum) #{‘price__sum‘: 476} #price__sum 是price + Sum 组合的,也可以自己起名字 # # ret_avg = Book.objects.all().aggregate(avg_price = Avg("price")) # print(ret_avg) #{‘avg_price‘: 68.0} # # ret_count = Book.objects.all().aggregate(Count("name")) #Count("name") Count("price") 都可以只是统计条数 # print(ret_count) #{‘name__count‘: 7} # # ret_max = Book.objects.all().aggregate(Max("price")) # print(ret_max) #{‘price__max‘: 99} # # ret_min = Book.objects.all().aggregate(Min("price")) # print(ret_min) #{‘price__min‘: 39}
Author.objects.values("name").annotate(Sum("book__price"))
annotate 前面是分组(按照作者名称分组),后面是针对每一组的处理函数(每一个作者关联书籍的价格求和)
# 需求1:求每一个作者 写的书的总价钱 # ret_SumPrice = Author.objects.values("name").annotate(Sum("book__price")) # print(ret_SumPrice) # 需求2:求每一个出版社 出版的最便宜的书 # ret_MinPrice = Publish.objects.values("name").annotate(Min("book__price")) # print(ret_MinPrice)
# F 使用查询条件的值, 专门取对象中某列值的操作 # 需求1:实现所有书价格 +10 # Book.objects.update(price=F("price")+10)
# Q 构建搜索条件,与 或 非 # 需求1:查询价格大于80 或者小于40的书籍 # ret1 = Book.objects.filter(Q(price__gt=80) | Q(price__lt=40)) # print(ret1.all()) # 需求2:查询机械工业出版社出版的价格大于60的书 # ret2 = Book.objects.filter(Q(publish__name="机械工业出版社") & Q(price__gt=60)) # print(ret2.all()) # 需求3:查询机械工业出版社出版且不是杜甫写的书 # ret3 = Book.objects.filter(Q(publish__name="机械工业出版社") & ~Q(author__name="杜甫")) # print(ret3.all())
< 1 > Django的queryset是惰性的。
< 2 > 要真正从数据库获得数据,你可以遍历queryset或者使用if queryset, 总之你用到数据时就会执行sql。
< 3 > queryset是具有cache的。
< 4 >使用obj.exists() 可以判断QuerySet 是否有数据,如果取出的几万条数据都放在内存中会影响性能。
< 5 > 当queryset非常巨大时,cache会成为问题。
# < 1 > Django的queryset是惰性的 # < 2 > 要真正从数据库获得数据,你可以遍历queryset或者使用if queryset, 总之你用到数据时就会执行sql。 # < 3 > queryset是具有cache的 bool_obj = Book.objects.values("name","price") print(bool_obj) print(bool_obj) #SQL语句查询只会执行一次 # 《4》使用obj.exists() 可以判断QuerySet 是否有数据,如果取出的几万条数据都放在内存中会影响性能 obj = Book.objects.filter(id=4) # exists()的检查可以避免数据放入queryset的cache。 if obj.exists(): print("hello world!") # < 5 > 当queryset非常巨大时,cache会成为问题 # 处理成千上万的记录时,将它们一次装入内存是很浪费的。更糟糕的是,巨大的queryset可能会锁住系统 # 进程,让你的程序濒临崩溃。要避免在遍历数据的同时产生querysetcache, # 可以使用iterator()方法来获取数据,处理完数据就将其丢弃。 objs = Book.objects.all().iterator() # iterator()可以一次只从数据库获取少量数据,这样可以节省内存 for obj in objs: print(obj.name) # BUT,再次遍历没有打印,因为迭代器已经在上一次遍历(next)到最后一次了,没得遍历了 for obj in objs: print(obj.name) # 当然,使用iterator()方法来防止生成cache,意味着遍历同一个queryset时会重复执行查询。所以使 # 用iterator()的时候要当心,确保你的代码在操作一个大的queryset时没有重复执行查询 # 总结: # queryset的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候才会查询数据库。 # 使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并不会生成queryset cache,可能会造成额外的数据库查询。 # 所以,当查询到超大量数据且不是反复使用 最好用iterator(),当查询到少量数据且要反复使用 就直接放在QuerySet cache中即可。
# 总结: # queryset的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候才会查询数据库。 # 使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并不会生成queryset cache,可能会造成额外的数据库查询。 # 所以,当查询到超大量数据且不是反复使用 最好用iterator(),当查询到少量数据且要反复使用 就直接放在QuerySet cache中即可。
标签:属性 模糊 优化 div reg ast tin 操作 mic
原文地址:https://www.cnblogs.com/XJT2018/p/11309025.html
