标签:size 就是 png 基础 基础学习 eps col 现在 color
给定一个目标函数f(x)和初始点x0
△xt = -▽f(xt)
xt+1 = x + η△xt
停止条件:当 |△xt| < ε时停止
三大问题:局部最小值、鞍点、停滞区。
1.1 局部最小值(极值)
1.2 停滞区
函数有一段很平的区域,这时梯度很小,权值就更新的特别慢。
1.3 鞍点
鞍点处梯度为0,但不是局部最大值也不是局部最小值。
鞍点坐在的位置在一个方向上式最大值,在另一个方向上是最小值。
给定一个目标函数f(x)和初始点x0,初始动量v0
△xt = -▽f(xt)
vt+1 = γvt + η△xt
xt+1 = xt + vt+1
停止标准:冲量小于一个值,或梯度小于一个值,或给定一个迭代次数
在梯度下降法的基础上,加上一个冲量的项,每次迭代乘一个衰减系数。
改进带冲量的梯度下降法。
给定一个目标函数f(x)和初始点x0,初始动量v0
△xt = - ▽f( xt + γvt )
vt+1 = γvt + η△xt
xt+1 = xt + vt+1
可以发现,求梯度的位置不在是当前位置的梯度,而是沿着当前冲量乘衰减系数前进一步之后所在的位置。
例如骑自行车下坡,原来是根据当前的坡度决定车怎么走,而现在是根据前方的坡度来决定车往哪儿拐。
用来寻找实值方程的近似解。
给定方程f(x)= 0,初始点x0
△x = - f(xt) / f‘(xt)
xt+1 = xt + △x
停止:如果|f(x)| < ε
给定f(x)和初始点x0
xt+1 = xt - f‘(xt)/f‘‘(xt)
停止:| f‘(xt) | < ε
若f(x+△x)是极小值点,将其泰勒展开到二阶:
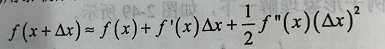
函数对称轴出就是极值,则:

牛顿法每次迭代,在所在的位置对要求解的函数做一次二次近似,然后直接用这个近似的最小值作为下一次迭代的位置。在高维下计算量有点大。
五、学习率衰减
前期使用叫大的学习率,后期使用较小的学习率。
lr = lrbase x γ| step/stepsize |
基础学习率;
γ是小于1 的衰减系数;
step:当前迭代步数
stepsize:总共迭代次数
标签:size 就是 png 基础 基础学习 eps col 现在 color
原文地址:https://www.cnblogs.com/pacino12134/p/11318068.html