标签:utf-8 名称 response http seh urllib stp drs lse
需求:爬取网站上的公司信息
代码如下:
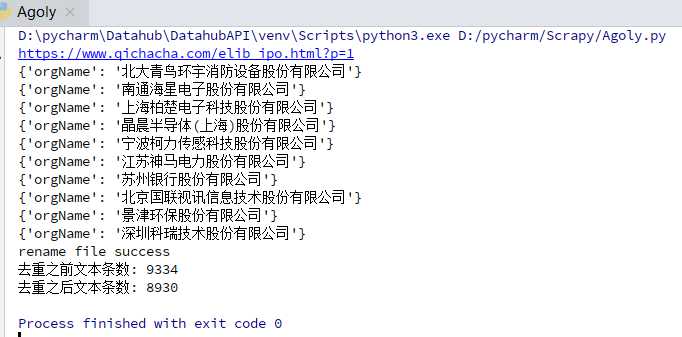
import json import os import shutil import requests import re import time requests.packages.urllib3.disable_warnings() #通过url请求接口,获取返回数据 def getPage(url,headers): try: response = requests.get(url=url, headers=headers, verify=False) response.encoding = ‘utf-8‘ if response.status_code == 200: #print (response.text) return response.text else: print(‘请求异常:{} status:{}‘.format(url, response.status_code)) except Exception as e: print(‘请求异常: {} error: {}‘.format(url, e)) return None #删除文件的重复行 def file2uniq(file,destpath): sum = 0 sum_pre = 0 addrs = set() with open(file, ‘r‘,encoding=‘utf8‘) as scan_file: for line in scan_file.readlines(): sum_pre += 1 # addr = get_addr(line) # line.decode(‘utf8‘) addrs.add(line) scan_file.close() with open(destpath, ‘w‘,encoding=‘utf8‘) as infile: while len(addrs) > 0: sum += 1 infile.write(addrs.pop()) infile.close() if (os.path.exists(file)): os.remove(file) try: os.rename(destpath, file) except Exception as e: print (e) print (‘rename file fail\r‘) else: print (‘rename file success\r‘) #print(addrs) print("去重之前文本条数: "+str(sum_pre)) print("去重之后文本条数: "+str(sum)) return sum_pre,sum #通过正则表达式提取页面内容 def parseHtml(html): #pattern = re.compile(r‘<tr> <td class="tx">.+\s(.+)‘, re.I) # 不区分大小写 匹配股票名称 # 不区分大小写 获取完整公司名 pattern = re.compile(r‘<td class="text-center">.+</td> <td> <a href="/firm_.+">\s(.+)‘, re.I) # 获取证券公司 #pattern = re.compile(r‘\t(.+)[\s]+</a> </td> <td class="text-center">.+</td> <td class="text-center">.+</td> </tr>‘, re.I) #pattern = re.compile(r‘\t(.+)\s\t\t\t\t\t\t\t </a> </td> <td class="text-center">.+</td> <td class="text-center">.+</td> </tr> <tr> <td class="tx">‘, re.I) # 不区分大小写 #pattern = re.compile(r‘</a>\s</td>\s<td class="text-center">.+</td> <td> <a href="/firm_.+.html">\s(.+)[\s]+</a> </td> <td> <a href="/firm_.+.html">\s(.+)‘, re.I) # 不区分大小写 匹配股票名称 items = re.findall(pattern, html) #print (items) for item in items: yield { ‘orgName‘: item.strip(), } def write2txt(content): with open(file, ‘a‘, encoding=‘utf-8‘) as f: f.write(json.dumps(content, ensure_ascii=False) + ‘\n‘) def removeStr(old_str,new_str): """ with open(‘sanban.txt‘, ‘a‘, encoding=‘utf-8‘) as fpr: content = fpr.read() content = content.replace(r‘{"orgName": "‘, ‘‘) content = content.replace(r‘"}‘, ‘‘) """ file_data = "" with open(file, ‘r‘, encoding=‘utf-8‘) as f: for line in f: if old_str in line: line = line.replace(old_str,new_str) file_data += line with open(file, ‘w‘, encoding=‘utf-8‘) as f: f.write(file_data) def main(page): #url = ‘https://www.qichacha.com/elib_sanban.html?p=‘ + str(page) url = ‘https://www.qichacha.com/elib_ipo.html?p=‘ + str(page) # https://www.qichacha.com/elib_ipo.html?p=2 headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36‘, } print (url) html = getPage(url,headers) #print (html) for item in parseHtml(html): print(item) write2txt(item) removeStr(r‘{"orgName": "‘,‘‘) removeStr(r‘"}‘, ‘‘) file2uniq(file, destpath) if __name__ == ‘__main__‘: file = r‘orgName.txt‘ #file = r‘midOrg.txt‘ #sourcepath = r‘sanban.txt‘ destpath = r‘temp.txt‘ for page in range(1,2): main(page) time.sleep(1)
标签:utf-8 名称 response http seh urllib stp drs lse
原文地址:https://www.cnblogs.com/qmfsun/p/11322893.html