存储过程(stored procedure)是一组为了完成特定功能的SQL语句集合,经编译后存储在服务器端的数据库中,利用存储过程可以加速SQL语句的执行。
自定义存储过程,由用户创建并能完成某一特定功能的存储过程,存储过程既可以有参数又有返回值,但是它与函数不同,存储过程的返回值只是指明执行是否成功,
存储过程并不能像函数那样被直接调用,只能利用 execute 来执行存储过程。
优点:
1、提高应用程序的通用性和可移植性:存储过程创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。并且数据库专业人员可以随时对存储过程进行
修改,且对程序源代码没有影响,这样就极大的提高了程序的可移植性。
2、可以提高SQL的速度,存储过程是编译过的,如果某一个操作包含大量的SQL代码或分别被执行多次,那么使用存储过程比直接使用单条SQL语句执行速度快的多。
3、减轻服务器的负担:当用户的操作是针对数据库对象的操作时,如果使用单条调用的方式,那么网络上还必须传输大量的SQL语句,如果使用存储过程,
则直接发送过程的调用命令即可,降低了网络的负担。
语法:
CREATE PROC [ EDURE ] procedure_name [ ; number ] [ { @parameter data_type } [ VARYING ] [ = default ] [ OUTPUT ] ] [ ,...n ] [ WITH { RECOMPILE | ENCRYPTION | RECOMPILE , ENCRYPTION } ] [ FOR REPLICATION ] AS [ begin ] T-SQL 语句 [ end ]
一、參数简单介绍 1、 procedure_name 新存储过程的名称。过程名必须符合标识符规则,且对于数据库及其全部者必须唯一。 要创建局部暂时过程,能够在 procedure_name 前面加一个编号符 (#procedure_name),要创建全局暂时过程。能够在 procedure_name 前面加两个编号符 (##procedure_name)。完整的名称(包含 # 或 ##)不能超过 128 个字符。指定过程全部者的名称是可选的。 2、;number 是可选的整数。用来对同名的过程分组,以便用一条 Drop PROCEDURE 语句就可以将同组的过程一起除去。比如。名为 orders 的应用程序使用的过程能够命名为 orderproc;1、orderproc;2 等。Drop PROCEDURE orderproc 语句将除去整个组。假设名称中包括定界标识符,则数字不应包括在标识符中,仅仅应在 procedure_name 前后使用适当的定界符。 3、@parameter 过程中的參数。在 Create PROCEDURE 语句中能够声明一个或多个參数。 用户必须在运行过程时提供每一个所声明參数的值(除非定义了该參数的默认值)。 存储过程最多能够有 2100 个參数。 使用@符号作为第一个字符来指定參数名称。 參数名称必须符合标识符的规则。每一个过程的參数仅用于该过程本身;同样的參数名称能够用在其他过程中。默认情况下,參数仅仅能取代常量,而不能用于取代表名、列名或其他数据库对象的名称。 4、data_type 參数的数据类型。全部数据类型(包含 text、ntext 和 image)均能够用作存储过程的參数。只是,cursor 数据类型仅仅能用于 OUTPUT 參数。假设指定的数据类型为 cursor,也必须同一时候指定 VARYING 和 OUTPUT keyword。 说明:对于能够是cursor 数据类型的输出參数。没有最大数目的限制。 5、VARYING 指定作为输出參数支持的结果集(由存储过程动态构造,内容能够变化)。仅适用于游标參数。 6、default 參数的默认值。 假设定义了默认值,不必指定该參数的值就可以运行过程。默认值必须是常量或 NULL。假设过程将对该參数使用 LIKE keyword。那么默认值中能够包括通配符(%、_、[] 和 [^])。 7、OUTPUT 表明參数是返回參数。该选项的值能够返回给 EXEC[UTE]。 使用 OUTPUT 參数可将信息返回给调用过程。Text、ntext 和 image 參数可用作 OUTPUT 參数。使用 OUTPUT keyword的输出參数能够是游标占位符。 8、n 表示最多能够指定 2100 个參数的占位符。 9、{RECOMPILE | ENCRYPTION | RECOMPILE, ENCRYPTION} RECOMPILE 表明 SQL Server 不会缓存该过程的计划,该过程将在执行时又一次编译。在使用非典型值或暂时值而不希望覆盖缓存在内存中的执行计划时,请使用 RECOMPILE 选项。 ENCRYPTION 表示 SQL Server 加密 syscomments 表中包括 Create PROCEDURE 语句文本的条目。 使用 ENCRYPTION 可防止将过程作为 SQL Server 复制的一部分公布。 说明:在升级过程中,SQL Server 利用存储在 syscomments 中的加密凝视来又一次创建加密过程。 10、FOR REPLICATION 指定不能在订阅server上运行为复制创建的存储过程。.使用 FOR REPLICATION 选项创建的存储过程可用作存储过程筛选,且仅仅能在复制过程中运行。本选项不能和 WITH RECOMPILE 选项一起使用。 11、AS 指定过程要运行的操作。 12、sql_statement 过程中要包括的随意数目和类型的 Transact-SQL 语句。但有一些限制。 13、 n 是表示此过程能够包括多条 Transact-SQL 语句的占位符。 14、凝视 /*和*/之间的为凝视。能够包括一行和多行的说明文字。 15、 其它说明 存储过程的最大大小为 128 MB。 二、小注: 存储过程一般用来完毕数据查询和数据处理操作,所以在存储过程中不能够使用创建数据库对象的语句,即在存储过程中一般不能含有下面语句: CREATE TABLE ; CREATE VIEW 。 CREATE DEFAULT ; CREATE RULE ;CREATE TRIGGER 。CREATE PROCEDURE
无参数存储过程:
--创建名为 GetStuCou 的无参数存储过程 create procedure GetStuCou as begin select * from Student s left join Course c on s.C_S_Id=c.C_Id end --执行名为 GetStuCou 的无参数存储过程 execute GetStuCou
有返回值的存储过程:
--创建名为 GetStuCou_Re 的有返回值的存储过程 create procedure GetStuCou_Re as begin insert into Course(C_Name) values(‘HTML5‘) return SCOPE_IDENTITY(); -- 返回为当前表插入数据最后生成的标识值。 end --执行名为 GetStuCou 的有返回值的存储过程 execute GetStuCou_Re
有输入参数的存储过程:
--创建名为 GetStuCou_In 的有输入参数的存储过程 create procedure GetStuCou_In @StuNo nvarchar(64)=‘001‘ --设置默认值 as begin select * from Student where S_StuNo=@StuNo end --执行名为 GetStuCou_In 的有输入参数的存储过程(不传参数,即使用默认值) execute GetStuCou_In --执行名为 GetStuCou_In 的有输入参数的存储过程(传入参数) execute GetStuCou_In ‘005‘
有输入、输出参数的存储过程:
--创建名为 GetStuCou_Out 的有输入参数和输出参数的存储过程 create procedure GetStuCou_Out @StuNo nvarchar(64), @Height nvarchar(32) output as begin if(@StuNo is not null and @StuNo <> ‘‘) begin select @Height=S_Height from Student where S_StuNo=@StuNo end else begin set @Height=‘185‘ end end --执行名为 GetStuCou_Out 的有输入参数和输出参数的存储过程 execute GetStuCou_Out ‘005‘,null
有输入、输出参数和结果集的存储过程:
--创建名为 GetStuCou_DS 的有输入参数、输出参数和结果集的存储过程 create procedure GetStuCou_DS @StuNo nvarchar(64), @Height nvarchar(32) output as begin if(@StuNo is not null and @StuNo <> ‘‘) begin select @Height=S_Height from Student where S_StuNo=@StuNo end else begin set @Height=‘185‘ end select s.S_Id,s.S_StuNo,s.S_Name,s.S_Sex,s.S_Height,s.S_BirthDate,c.C_Id,c.C_Name from Student s left join Course c on s.C_S_Id=c.C_Id where S_StuNo=@StuNo end --执行名为 GetStuCou_DS 的有输入参数、输出参数和结果集的存储过程 execute GetStuCou_DS ‘005‘,null
返回多个结果集的存储过程:
--创建名为 GetStuCou_DSS 的返回多个结果集的存储过程 create procedure GetStuCou_DSS @StuNo nvarchar(64), @Height nvarchar(32) as begin if(@StuNo is not null and @StuNo <> ‘‘) begin select * from Student where S_StuNo=@StuNo end if(@Height is not null and @Height <> ‘‘) begin select * from Student where S_Height=@Height end end --执行名为 GetStuCou_DSS 的返回多个结果集的存储过程 execute GetStuCou_DSS ‘005‘,‘185‘
存储过程里面不仅可以进行查询,还可以进行各种增删改操作。其实存储就是由很多 T-SQL 语句组成的代码块。
存储过程中创建变量、赋值变量、创建表变量和临时表:
--创建名为 GetStuCou_Ext 的返回多个结果集的存储过程 create procedure GetStuCou_Ext @StuNo nvarchar(64), @Height nvarchar(32) as begin declare @Var nvarchar(10) --定义变量 set @Var=‘123‘ --赋值变量 --定义表变量 declare @StuTab table ( ID int not null primary key, StuNo nvarchar(50) unique, Name varchar(50), Sex varchar(10), Height varchar(10) ) --表变量只能在定义的时候添加约束 --定义临时表 create table #Tab ( ID int not null primary key, StuNo nvarchar(50), Name varchar(50), Sex varchar(10), Height varchar(10) ) alter table #Tab add constraint S_UNIQUE unique(StuNo) --临时表可以在之后添加约束 if(@StuNo is not null and @StuNo <> ‘‘) begin insert into @StuTab(ID,StuNo,Name,Sex,Height) --把数据插入表变量 select S_Id,S_StuNo,S_Name,S_Sex,S_Height from Student where S_StuNo=@StuNo insert into #Tab(ID,StuNo,Name,Sex,Height) --把数据插入临时表 select S_Id,S_StuNo,S_Name,S_Sex,S_Height from Student where S_StuNo=@StuNo end if(@Height is not null and @Height <> ‘‘) begin insert into @StuTab(ID,StuNo,Name,Sex,Height) --把数据插入表变量 select S_Id,S_StuNo,S_Name,S_Sex,S_Height from Student where S_Height=@Height insert into #Tab(ID,StuNo,Name,Sex,Height) --把数据插入临时表 select S_Id,S_StuNo,S_Name,S_Sex,S_Height from Student where S_Height=@Height end SELECT * FROM @StuTab select * from #Tab end --执行名为 GetStuCou_DSS 的返回多个结果集的存储过程 execute GetStuCou_Ext ‘005‘,‘185‘
存储过程动态执行 SQL 语句:
以上可以看出我们传入的参数(学号)是单个的,那么如果一次性传入多个学号呢(使用逗号隔开,即 ‘005,006,007‘ ),这就需要用到动态拼接并执行 sql 语句。
create proc GetStus @StuNo nvarchar(500) as begin declare @Sql nvarchar(3000) if(@StuNo is not null and @StuNo <> ‘‘) begin set @Sql=‘ select * from Student where S_StuNo in (‘+@StuNo+‘) ‘ end exec (@Sql) --执行动态 sql end exec GetStus ‘003,005,009‘ --执行存储过程 GetStus
现在还有一个问题,我想要执行动态 sql 的时候并返回变量值,比如我现在需要执行动态 sql 的时候返回课程 ID ,然后根据课程 ID 查询课程。
使用系统存储过程 sp_executesql 动态 sql 给变量赋值。
修改存储过程之后:
ALTER proc [dbo].[GetStus] @StuNo nvarchar(500) as begin declare @Sql nvarchar(3000) declare @C_Id int declare @Cou int if(@StuNo is not null and @StuNo <> ‘‘) begin set @Sql=‘ select @CId=C_S_Id,@cou=count(1) from Student where S_StuNo in (‘+@StuNo+‘) group by C_S_Id ‘ end exec sp_executesql @Sql,N‘@CId int output,@cou int output‘,@CId = @C_Id output,@cou = @Cou output; select @C_Id,@Cou --查看返回变量的值 select * from Course where C_Id=@C_Id end exec GetStus ‘005‘ --执行存储过程 GetStus
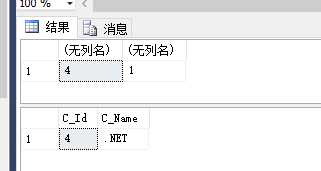
PS:sp_executesql 要求动态 Sql 和动态 Sql 参数列表必须是 NVARCHAR 类型。
动态Sql的参数列表与外部提供值的参数列表顺序必需一致,例如:N‘@CId int output,@cou int output‘,@CId = @C_Id output,@cou = @Cou output;,@CId 对应 @C_Id,@cou 对应 @Cou。
动态SQl的参数列表与外部提供参数的参数列表参数名可以同名,如果不一样,需显示注明,例如:N‘@CId int output,@cou int output‘,@CId = @C_Id output,@cou = @Cou output;,即 @CId = @C_Id 和 @cou = @Cou 。
https://www.cnblogs.com/zhaojinyan/p/9583348.html