标签:cPage style blog http color io os ar 使用
本文关注以下方面(本文所有的讨论基于SQL Server数据库):
一、索引定义分类
让我们先来回答几个问题:
二、索引数据结构
在SQL Server数据库中,索引的存储是以B+树(注意和二叉树的区别)结构来存储的,又称索引树,其节点类型为如下两种:
索引节点按照层级关系,有时又可以分为根节点和中间节点,其本质是一样的,都只包含下一层节点的入口值和入口指针;
叶子节点就不同了,它包含数据,这个数据可能是表中真实的数据行,也有可能是索引列值和行书签,前者对应于聚集索引,后者对应于非聚集索引。
三、索引存储结构
在正式讨论索引的存储结构之前,我们有必要先来了解一下SQL Server数据库的存储结构。
SQL Server数据库存储(结构)的最小单位是页,大小为8K,共8 * 1024 = 8192Byte,不论是数据页还是索引页都是以此方式存放。实际上对于SQL Server数据库而言,其页(Page)类型有很多种,大概有如下十几种(http://www.sqlnotes.info/2011/10/31/page-type/):
表中所有数据页的存放在磁盘上又有两种组织方式:
如果表中所有数据页是以一种页间无序、随机存储的方式,则称这样的表为堆表;
否则如果表中数据页间按某种方式(如表中某个字段)有序地存储与磁盘上,则称为索引组织表。
四、聚集索引
下面我们将深入研究一下数据库中的索引到底是如何存储的以及如何被使用的。
为了测试验证等,我们在数据库PCT上新建一张测试表Employee,有两个字段,其中EmployeeId为主键
USE PCT CREATE TABLE Employee ( EmployeeId NVARCHAR(32) NOT NULL PRIMARY KEY, EmployeeName NVARCHAR(40) NOT NULL, );
插入10W笔测试数据
SET NOCOUNT ON declare @i int set @i=1 while @i<=100000 begin INSERT INTO Employee VALUES(replace(newid(), ‘-‘, ‘‘), ‘Employee_‘ + CONVERT(varchar, @i) ); set @i = @i+1 end
通过DBCC IND命令来查看索引的情况
DBCC IND ([PCT], [DBO.Employee], -1)
结果如下
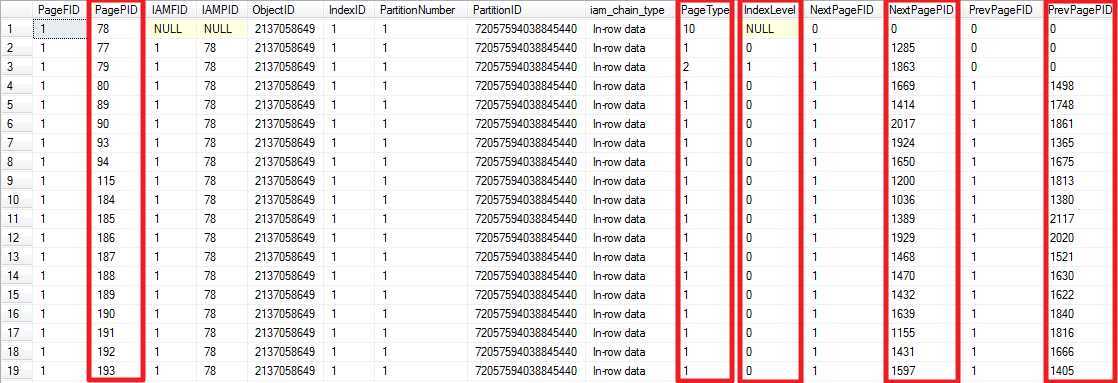
红色标记说明:
为了方便查找,我们也可以把上述结果存入表中,为此建表
CREATE TABLE DBCCIndResult ( PageFID NVARCHAR(200), PagePID NVARCHAR(200), IAMFID NVARCHAR(200), IAMPID NVARCHAR(200), ObjectID NVARCHAR(200), IndexID NVARCHAR(200), PartitionNumber NVARCHAR(200), PartitionID NVARCHAR(200), iam_chain_type NVARCHAR(200), PageType NVARCHAR(200), IndexLevel NVARCHAR(200), NextPageFID NVARCHAR(200), NextPagePID NVARCHAR(200), PrevPageFID NVARCHAR(200), PrevPagePID NVARCHAR(200) )
插入数据
INSERT INTO DBCCIndResult EXEC (‘DBCC IND(PCT,Employee,-1) ‘)
我们可以通过下面的语句来查看索引的深度
select * from sys.dm_db_index_physical_stats(db_id(‘PCT‘),object_id(‘Employee‘),null,null,null)

我们看到索引的深度为3,上面的IndexLevel分别有0,1,2也验证了这一点。page_count为1944,但是我们上面查到的结果却是1977,这是因为这里的语句没有计算Index为1和2的页(注意index_level列)
接下来我们看看B树中各种节点存储的到底是什么?
找到根节点283
select * from DBCCIndResult where pagetype = 2 and indexLevel = 2
查看页里的数据
DBCC TRACEON (3604); GO DBCC PAGE (PCT, 1, 283, 3); GO
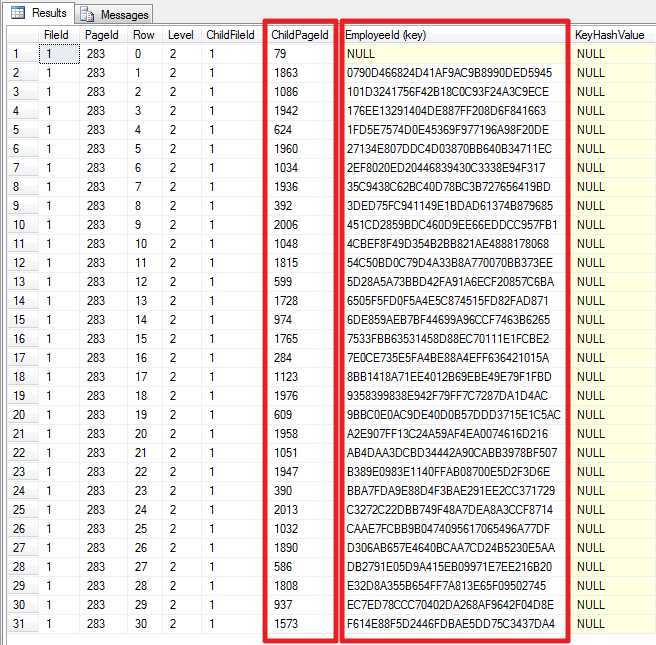
从上图,可以看出,此根节点共有31个儿子(中间节点),而且还存有主键值EmployeeId,那么这31个主键值是哪些记录的主键值呢?我们继续深入
以中间节点1863为例
DBCC TRACEON (3604); GO DBCC PAGE (PCT, 1, 1863, 3); GO
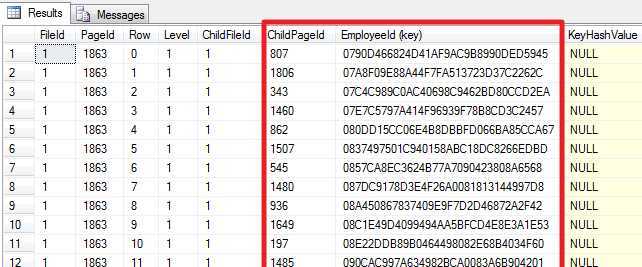
这和根节点很类似,标明了包含下一层的节点(共65个)和主键值,继续深入
以叶节点807为例
DBCC TRACEON (3604); GO DBCC PAGE (PCT, 1, 807, 3); GO
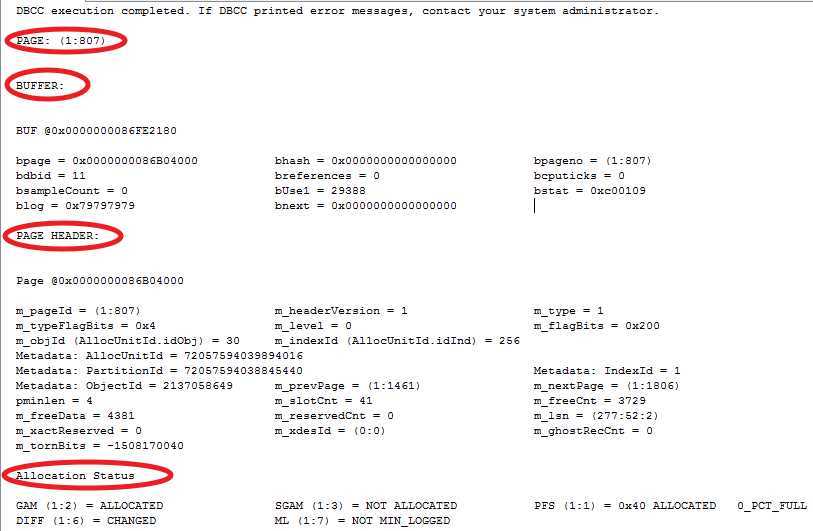
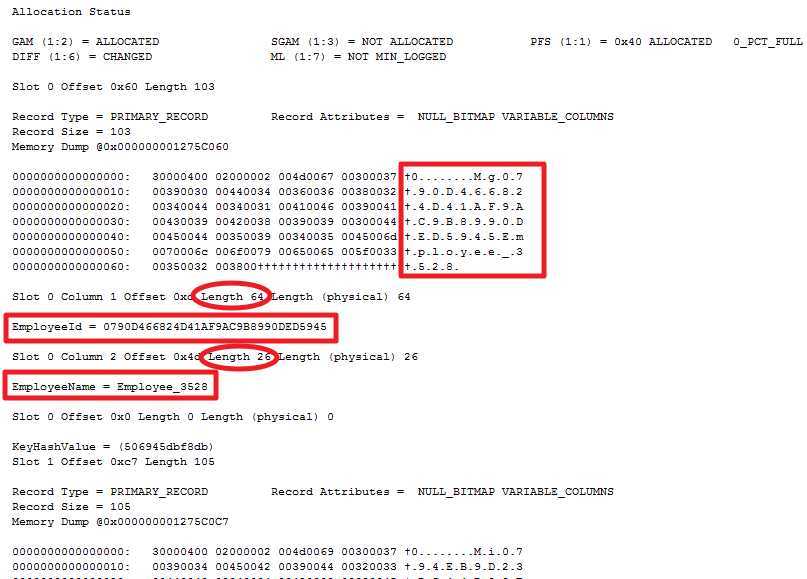
由于结果太多,我就不把所有的截图都发出来了,但是从上面我们已经看到了一些重要的东西
首先PAGE:(1:807)表明这是一个叶节点,同时也是一个数据页,因为它存放了表里所有字段的数据(EmployeeId和EmployeeName),换句话说这儿的叶节点就是表Employee在数据库中的存储数据页,也就是说聚集索引的叶节点其实就是表的数据存储页
其次我们看标红的EmployeeId,它就是我们在之前根节点283和中间节点1863存储的主键值,而且它是位于数据存储页的第一个数据
至此我们总结如下:
为了更方便地查看叶节点的数据,我们将其存入表中
DBCC PAGE(PCT,1,807, 3) WITH TABLERESULTS
这种方式是以表的方式展示
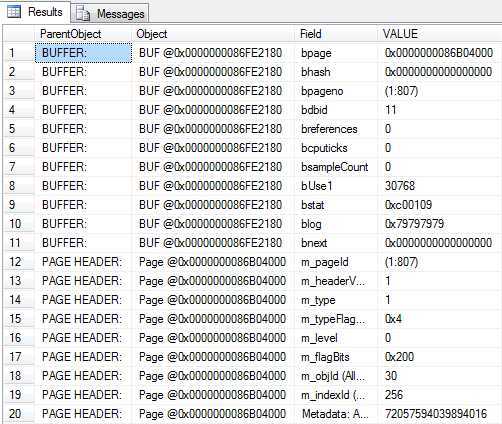
但是这种方式也不便查找,我们索性新建表
CREATE TABLE DBCCPageResult( ParentObject NVARCHAR(200), Object NVARCHAR(200), Field NVARCHAR(200), Value NVARCHAR(200) )
插入数据
INSERT INTO DBCCPageResult EXEC (‘DBCC PAGE(PCT,1,807, 3) WITH TABLERESULTS‘)
查看EmployeeId数据
select * from DBCCPageResult where Field = ‘EmployeeId‘
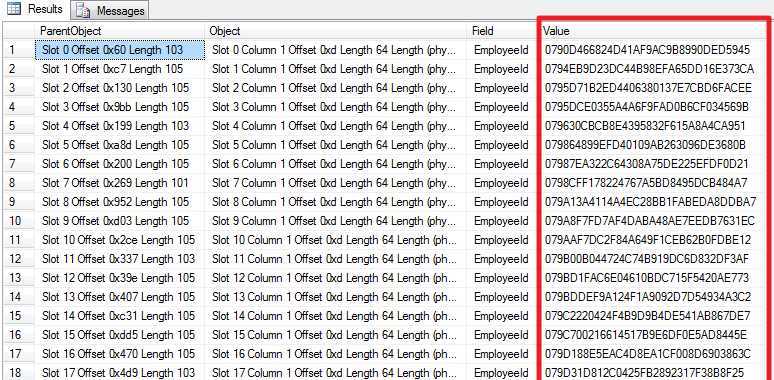
注意Value,是按顺序排好的,这也是聚集索引的意义了 - 把数据按顺序存储.
至此我们又可以得出:
五、非聚集索引
在表Employee字段EmployeeName建立非聚集索引
CREATE NONCLUSTERED INDEX IX_TBL_Employee_EmployeeName ON Employee(EmployeeName) WITH FILLFACTOR= 30 GO
再增加一列PhoneNumber以备测试之用
ALTER TABLE Employee ADD PhoneNumber INT NULL
先清空表DBCCIndResult数据
TRUNCATE TABLE DBCCIndResult
再重新插入数据
INSERT INTO DBCCIndResult EXEC (‘DBCC IND(PCT,Employee,-1) ‘)
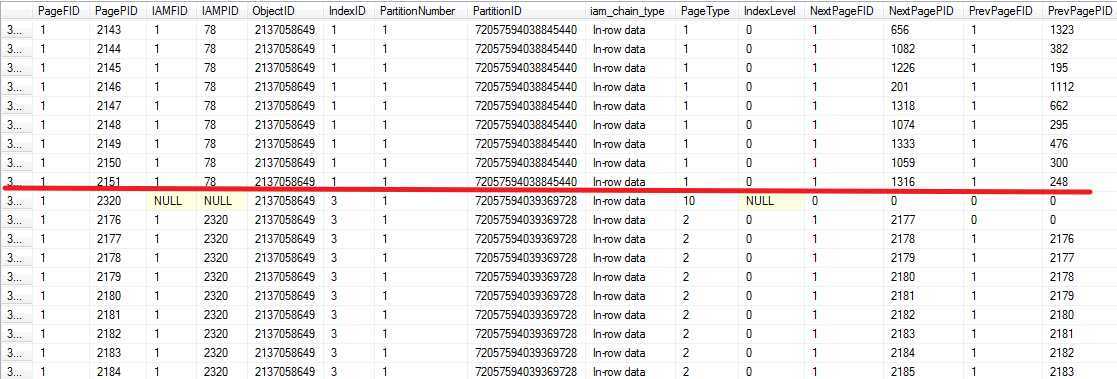
中间红线上面的是之前聚集索引的数据,下面是非聚集索引的数据
找到非聚集索引树的根节点,为2482
select * from DBCCIndResult where IAMPID = 2320 and indexlevel = 2
查看根节点2482数据
DBCC TRACEON (3604); GO DBCC PAGE (PCT, 1, 2482, 3); GO
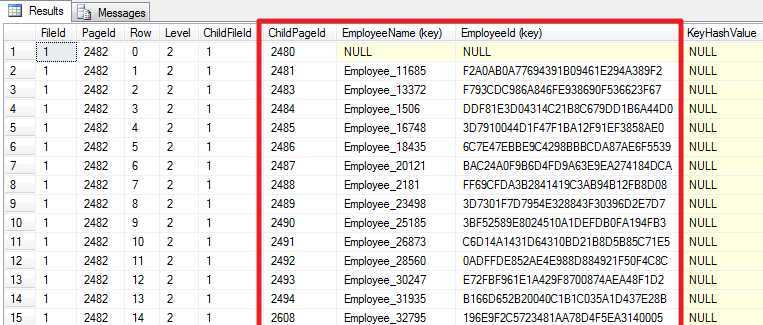
上图说明根节点包含下一层中间节点的页号,非聚集索引的键值EmployeeName以及聚集索引的键值EmployeeId
继续查看中间节点2481情况
DBCC TRACEON (3604); GO DBCC PAGE (PCT, 1, 2481, 3); GO
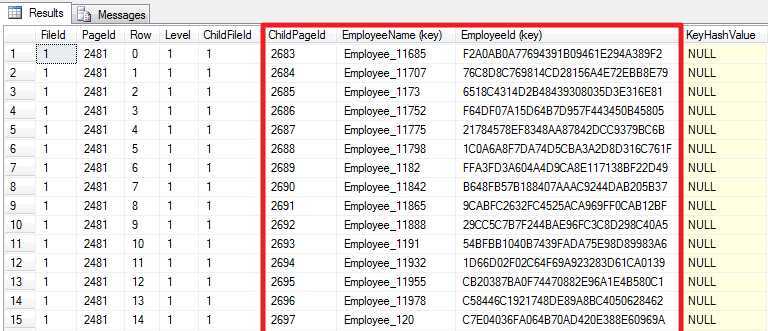
中间页节点(Level为1)同样包含了下一层(叶节点)的页号以及聚集、非聚集键值
继续查看叶节点2683情况
DBCC TRACEON (3604); GO DBCC PAGE (PCT, 1, 2683, 3); GO
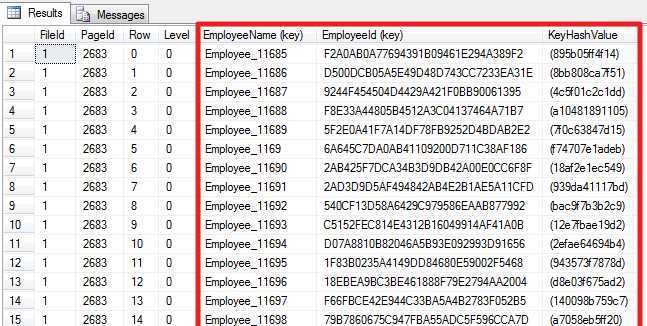
此处叶节点包含聚集、非聚集索引键值以及一个KeyHasValue
至此,我们总结如下:
非聚集索引行中的行定位器可以是指向行的指针,也可以是行的聚集索引键,具体根据如下情况而定:
六、索引覆盖
新加字段
ALTER TABLE EMPLOYEE ADD DepartmentCode NVARCHAR(50) NULL
删除并新建索引(索引覆盖)
drop index IX_TBL_Employee_EmployeeName on Employee create index IX_Employee_EmployeeName on Employee(EmployeeName) include(DepartmentCode)
把索引保存进表(先删除记录)
truncate table dbccindresult INSERT INTO dbccindresult EXEC (‘DBCC IND(PCT,Employee,-1) ‘)
和上面类似,找到非聚集索引的根节点6386
select * from dbccindresult where IAMPID = 127 and pagetype = 2 and indexlevel = 2
查看根节点数据
DBCC TRACEON (3604); GO DBCC PAGE (PCT, 1, 6386, 3); GO

查看中间节点6385
DBCC TRACEON (3604); GO DBCC PAGE (PCT, 1, 6385, 3); GO

查看叶节点6715
DBCC TRACEON (3604); GO DBCC PAGE (PCT, 1, 6715, 3); GO

总结如下:
标签:cPage style blog http color io os ar 使用
原文地址:http://www.cnblogs.com/panchunting/p/SQLServer_IndexStructure.html