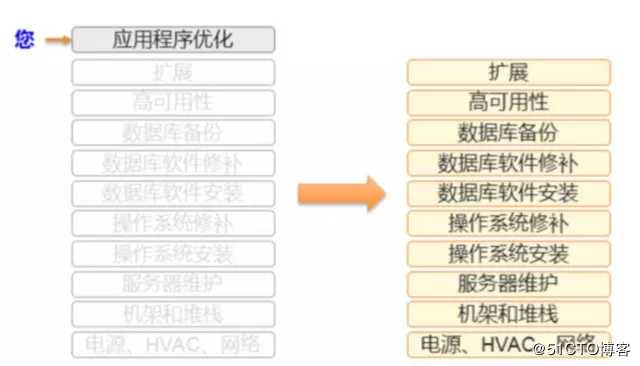
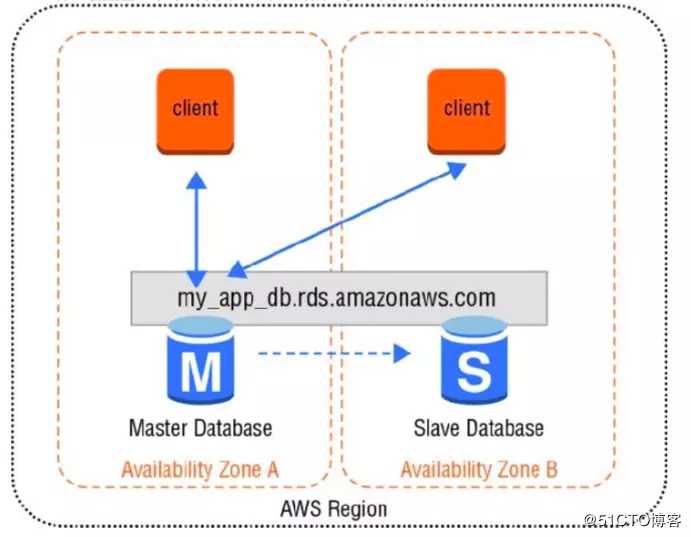
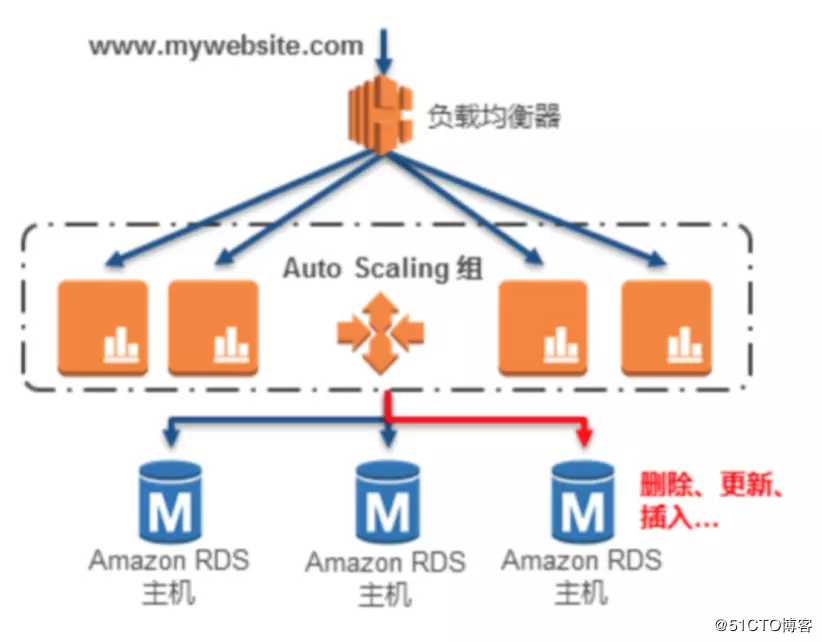
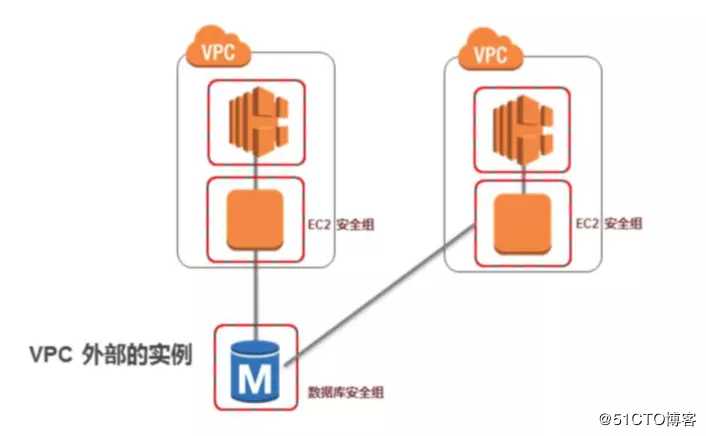
标签:除了 express 转移 挖掘 高效 默认 out double 关系数据库
SQL 数据库的默认端口
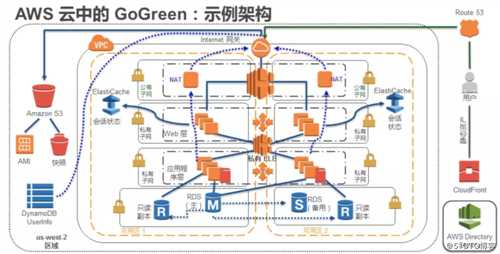
AWS 数据库(七)
原文地址:https://blog.51cto.com/wzlinux/2427961